- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
黑龙江移动区域化营销系统优化
录入:edatop.com 点击:
背景分析
2007年1月,中国移动集团公司下发了《区域管理应用业务技术方案》,并将区域化营销的相关技术部署工作正式纳入BASS1.5工程中进行实施。3月,集团公司将区域化营销的相关应用定为经营分析1.5工程中三大重点应用之一,要求各省公司进行推广和使用。
黑龙江省区域化营销的系统开发工作,于2007年3月25日完成并上线运行,在区域化归属过程中,系统是基于对全部客户的通话清单进行运算,且计算过程比较繁琐,每月计算期间所涉及到的数据量高达250G左右,总数据量已经接近1.5T(截至2007年12月份),对目前的系统造成了极大的压力。
为了更好地为市场服务,优化现有系统,黑龙江移动以目前区域化营销系统的实际情况为出发点,以更准确、高效地进行客户归属为目的,从理论上研究并论证区域化营销系统性能和归属算法优化的方法及实施的可行性,并进行了试验验证,实现了系统的优化。
现有方法
目前,黑龙江移动采用的客户区域归属方法是对客户的每日数据进行精确汇总,将数据存放在本地数据库中,然后在月末或年末根据客户所有数据进行精确归属。目前的客户区域化归属算法流程如图1所示。
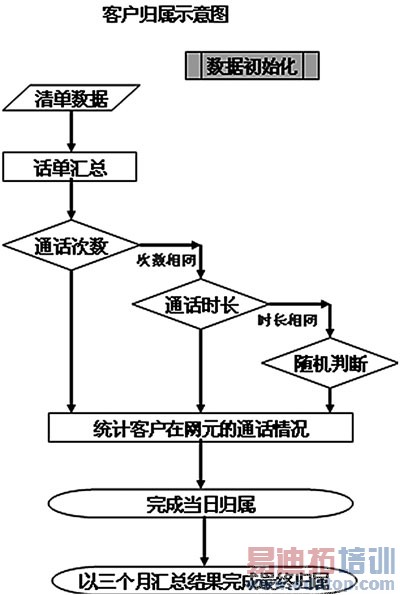
图1 客户区域化归属算法流程图
对本省客户先计算年末三个月的累计本地语音业务清单,汇总客户在各通信小区中的累计通话次数、通话时长,并归属到对应的片区中,作为初始化数据。
每月对当月新入网的客户按照通话次数最多的原则计算归属的区域,将其作为入网当月的归属区域,累计计算至三个月,完成归属。
上述传统方法存在一些不足,主要表现在以下方面。
1.归属时间代价过高:整个客户归属过程需要对原始海量数据进行多次扫描,归属过程的时间代价过高,会影响其它可能的业务系统运行。
2.归属的空间代价过高:用于客户归属的所有数据都需保存在本地数据库中。数据是海量的,并且随时间会不断增长,因此传统的方法会对磁盘的容量带来巨大挑战。
3.先验知识利用不足:绝大部分客户的频繁活动区域相对固定且较小,现有方法精确地计算了客户的所有活动区域,没有很好地利用先验知识,从而导致算法的时空代价极高。
客户区域化归属
针对已有方法的不足,笔者提出一套有效计算客户归属的方案。该方案主要是基于先进的数据流分析技术和抽样技术的基础上,提出了时空代价有效的在线客户归属方案,并且给出了实验验证,可以有效解决当前客户区域化归属过程中所遇到的难题,具有很高的市场应用和推广价值。
1.数据流技术
许多应用中,数据以流的形式存在,而不是存放在数据库中,如股票交易数据,Web服务器日志,通话记录等等。数据流环境与传统数据库环境的区别表现在两个方面:数据流数据量非常巨大、且仅允许访问一次;查询结果需要实时响应。数据流技术适用于解决数据海量且实时性要求极高的数据环境。
区域化营销系统环境是一个非常典型的数据流环境,其每日从Boss系统取批价之后的话单,并进行加载入库,在完成日加载之后,进行汇总,最终完成当日的统计。从开始加载,到最终的统计结束,按照每批话单的抽取和加载时间、顺序来看,恰好形成数据流的环境。
客户归属的目的是找到客户通话次数最频繁的一个区域,该区域的通话次数占总通话次数的比例相对其他区域来说较大。因此,根据这个特点,结合上述的归属理论,提出计算客户归属的方法,该方法如下所示。(一个桶记录客户的一个通话区域)
①分析历史数据,统计客户通话最频繁区域的通话次数占总通话次数的比例F,即最频繁区域的通话频率F。
②根据①中的通话频率F,计算出每个客户归属所需的桶的个数K:K>=1/F-1。每个桶用来记录一个通话区域及其相应的通话次数。
③根据Top-K计算方法,对每个客户的每条通话记录进行计算。
④在每个客户的K个桶中,找出次数最多的桶对应的区域,即为所求。
该算法是一个近似算法:第1步通过分析客户历史数据,统计出客户最频繁区域的通话次数占总通话次数的比例,不同用户这个比例不同;第2步通过第一步的通话频率F和公式K>=1/F-1计算出至少需要为每个用户设置多少个桶,才能计算出客户通话的最频繁区域。这里桶个数的计算方法主要是依据Top-K理论反推出来的。算法的3,4步比较直观,通过运用算法2计算所有的通话记录,最后找到最频繁的区域。
另外,对于新客户,由于没有历史信息可以利用,必须单独为它们设定桶的个数。笔者通过统计用户的信息发现,绝大部分用户的桶的个数不超过一个较小的常数M,因此对于新客户,可根据以往数据分析出M的大约值,这样就可以保证以极小的错误率计算出客户的最频繁区域。
2.抽样技术
客户区域归属任务本质上就是要对数据流进行摘要。数据流的实时性特点要求摘要算法必须有较小的时间复杂度,而数据流的无限性特点又限制了算法的空间复杂度不能过高。所以,在设计算法的时候,面临着时间复杂度和空间复杂度之间的权衡。
以上权衡是在数据集不变的情况下发生的。如果能够得到一个足以代表该数据集的子集的话,那么,尽管算法并没有从时间复杂度和空间复杂度上得到优化,但缩小数据子集带来的处理时间和耗费空间减少是不可忽视的。我们在研究中,采用了抽样技术,来有效地缩小数据子集。
①数据流抽样
采样算法与其他精确算法相比,其优势是在给定内存大小的条件下,抽样算法能够基于一定错误上界获得并存储能代表整个总体的数据子集,而由于数据集的减少带来的处理时间和使用空间的减少特点是精确算法所没有的。另外,由于数据流的无限性,采样算法会出现内存占用空间大于给定内存大小的时候,一方面保持了样本集前后一致的采样特性,另一方面为更多的数据腾出空间。
②计数采样方法
由于计数采样是有偏采样,因此其算法在改变采样阈值的同时必须保证该有偏采样的一致性。我们可以按照如下步骤设计采样算法。
首先,给定内存大小m,然后按照五个步骤进行:第一,初始化抽样阈值г=1;第二,如果样本值不存在于样本集中,则以1/г的抽样概率增加一个新的单元组到样本集;第三,否则,执行下面两项中的一项:把样本集的某一个单元组转换为二元组,或者把样本集的某一个二元组中的计数加1;第四,如2、3执行以后,内存占用空间>m,那么把抽样阈限从г提高到г’,然后对样本集每一个样本值的第一个样本点以г/г’概率随机筛选,对剩下的样本点以1/г’概率随机筛选;第五,重复第2个步骤。
3.归属方案
①基于内存的归属
处理过程:首先将所有客户桶个数信息从外存读入内存,建立相应数据结构,然后依据归属算法、根据当日的数据对客户信息进行更新,并进行抽样计算,处理完成后将所有客户信息写回外存。
过程描述如图2所示。
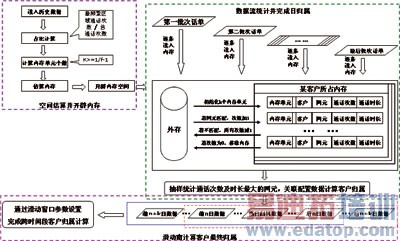
图2 基于内存的客户归属处理过程
②方案验证
在黑龙江移动真实数据集之上,笔者对方案进行了实验验证,证明所提出的方案在实际运营环境中的可行性和优越性。
在实验数据方面,以黑龙江移动2007年6月份话单月轻度汇总表和2007年7月1日语音GSM话单数据表为例。
6月份轻度汇总表包含以下属性:统计月份,地区代码,电话号码,话单类型,漫游类型,呼叫时段,交换机,lac代码,cell代码,呼叫次数,呼叫分钟,计费时长,呼叫时长,费用,优惠费用,约3亿条记录。
7月1日话单数据表包含以下属性:清单类型,清单入库日期,地区代码,主叫号码,主被叫,手机串码,对端类型,对端号码,拨打类型,通话日期,通话时间,呼叫时段,呼叫时长,计费时长,呼叫分钟,交换机,lac代码,cell代码,对端cell,对端lac,漫游类型,漫游地,对端接入地,对端漫游地,长途类型,基本费优惠基本费,约5300万条记录。
在实验平台方面,硬件环境为CPU:Intel(R)Xeon(R)CPU5110@ 1.60GHz(dual core);Memory:8 GB;Hard Disk:SCSI 300G x 2。软件环境为:操作系统:Debian GNU/Linux;数据库系统:postgresql 8.1;开发语言:Java JDBC。
基于内存的归属方案验证目标为基于内存的归属方案的时间和空间代价。
实验步骤主要有4个。
步骤1.分析表nm_voice200706,统计客户通话最频繁区域的通话次数占总通话次数的比例F,即最频繁区域的通话频率F。采用将数据库表读入内存的方式来执行,这样做的效率比较高。
步骤2.根据1中的通话频率F,计算出每个客户归属所需的桶的个数K:K>=1/F-1。每个桶用来记录一个通话区域及其相应的通话次数。然后将客户桶个数信息写入一个数据库表中。
步骤3.对表vc20070701的数据进行处理:按小时对数据进行处理。首先将步骤2中客户桶个数信息读入内存,在内存为每个用户建立相应数据结构。接着对vc200707011小时的记录进行顺次处理。如果该记录对应的客户已在内存中有相应信息,表示该客户的桶个数已经确定,相应内存单元加1;如果该记录对应的客户在内存中无相应信息,则为该客户创建数据结构,设客户的桶个数为M,然后按Top-K算法对该记录进行处理。
步骤4.按小时处理完vc20070701的所有记录后,将内存中的客户信息写入数据库表中。
我们从实验结果中得出,系统处理一天数据每小时所需的时间平均为5分钟,内存占用量不超过15G。
结束语
本算法在黑龙江移动公司的真实数据基础上,以课题的形式进行了讨论,依据数据流、滑动窗及抽样理论,笔者对于目前的系统算法进行了研究和探讨,试验结果,超出预期想象,对于系统日后的建设,具有积极的意义,具体体现在几个方面。
1.降低系统消耗,节约空间资源。
本算法剔除了现有系统中不必要的计算,且可通过抽样进行数据的精简,能够降低现有系统的空间占用情况及与其他程序的性能消耗情况。
2.能够大大提高系统处理速度,为将来实现各地市的个性化的归属计算奠定了基础。
通过增量的计算,取代现有的全量计算;通过内存计算,取代现有的数据库中的运算,从而大大提高了运算速度,使系统能够留出大量时间进行不同规则的属地化运算,如部分地市需要考虑缴费的权重,部分地市需要考虑通话时段或者节假日的权重,奠定了系统后续进行类似运算的基础。
3.更好地利用了已有的归属知识,使信息能够得到积累。
通过对历史归属信息的分析,并结合到现有算法中,过去的信息有效地得到了继承,避免现有算法中,一旦完成最终归属当年就不再变化的弊端,使分析人员能够更好地把握市场。
作者:刘刚 焦丽红 迟建德 孙德志 王敬尧 来源:通信世界周刊
上一篇:DCN网络(数据通信网)安全解决方案
下一篇:WLAN网络中VoIP的安全隐患

