- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
UIT Redirect-on-write 快照技术助力电信级数据容灾
录入:edatop.com 点击:
随着电信存储数据重要性的提高,用户需要在线方式进行数据保护,而创新科存储(UIT)的SVM的独创的Redirect-on-write 快照技术(简称PIT)能更好,更加有效的保护电信级的数据。在本文中,我们将讨论Redirect-on-write 快照技术的技术原理和如何做好电信级的容灾保护。
为了让大家更好的理解Redirect-on-write 快照技术(简称PIT),我们首先从磁盘的机理开始讨论。硬盘的每个盘片都有两个盘面(side),即上、下盘盘面,安照顺序从上至下从"0"开始依次编号。磁盘在格式化时被划分成许多同心圆,这些同心圆轨迹叫磁道(track)。磁道从外向内从0开始顺序编号。所有盘面上的同一磁道构成的一个圆柱,通常称做柱面(cylinder),每个柱面上的磁头由上而下从"0"开始编号。操作系统以扇区(sector)形式将信息存储在硬盘上,每个扇区包括512个字节的数据和一些其他信息。
这些通常用来表示硬盘的物理地址,现在随着硬盘容量增大我们用逻辑地址即线性地址(LBA)。LBA是一个地址转化技术,Block存放位置由索引表记录,第一个Block LBA=0,第二个LBA=1以此类推。 这里面主要是柱面(cylinder)-头(head)-扇区(sector) (CHS)配置。系统通过LBA到存储设备获取Block级的I/O。 一个简单的例子就是,如果一个Volume映射到一个物理磁盘,LBA直接传递到磁盘控制器。由于一些复杂的因素(特别是RAID设备和SAN,逻辑驱动器(LUN)通过LUN构成) LBA从磁盘的应用模式转换成存储设备能够使用的。在复杂的部署中,特别是在存储SAN环境中,这些LBA中的一部分会在众多磁盘中分布。存储系统控制器将单颗物理硬盘组成RAID Group,根据设定的Stripe Sieze条带化大小(64KB/128KB)将数据以分布式的方式存放在众多磁盘中用以提升性能,每次数据的读写都会调动所有驱动器。
Redirect-on-write 快照技术(PIT)
传统的快照技术都是基于即写即拷(copy-on-write)快照和分割镜像快照。但创新科存储的PIT技术完全不同与传统的快照,而使用了指针重定向技术。
Redirect-on-write快照技术执行时一个写I/O请求会通过hash表查找LBA队列和数据段. 不同的是如果在Hash表中发现了LBA,就在Snapshot卷上执行了一个写操作,在源卷上没有执行写操作.
如果在Hash表中没有发现LBA的写操作,LBA新地址就插入到Hash表中,在Snapshot卷上执行写操作,Redirect-on-write保留原卷不受任何影响。那么,原数据就保留在源卷上,所有的变化写在Snapshot卷上,point-in-time快照影像完全保留在源卷上。源卷在备份后或者创建了另外一个快照后就会更新。因此 redirect-on-write快照不会删除复制,可以推迟到稍后的时间而不是在当前的生产时间。
因为最新的变化数据在Snapshot卷中,没有变化的数据在源卷中,读I/O需要合并这两个卷中的数据。当一个读I/O 请求过来时,读请求会被分割成一个或者多个请求,这个取决于Snap_block 大小和LBA。每一个分割的读请求,会利用LBA作为关键值在Hash表中寻找。如果发现了LBA,说明此Block最新的数据在Snapshot卷中。我们快照卷中读取数据块. 否则就是从源卷中读取。当所有的数据段读取后,将需要的数据Block合并到Read Buffer中,给发起者发出可读响应。在这里面会用到许多I/O优化技术,一个直接的优化就是利用Bloomfilter 技术快速决定我们将从哪个卷读取。我们当前用的是结合多种优化方法在此并没有展开论述。
数据段和队列
对redirect-on-write来说数据段和队列都是必需的。数据段将请求分割成几个小的请求。I/O请求的LBA需要排列snap_block的LBA,这样I/O请求可以从任何地址开始,也许是Snap_block的中间。
假设开始I/O的LBA为A,Snap_block 大小为B,I/O请求的大小为L。假设一个LBA就是一个逻辑扇区地址,一个扇区是512字节。
段请求和最后一个段请求可能会处理Block数据的一部分。我们简单化了这些过程通过排列LBA地址到A-Remain而且从源卷第一个和最后一个Block段填满其它数据。实际上snap_block只是被部分数据填满就像众所周知的内部数据段(碎片). 这样的内部段会导致性能损失,因为内部段不仅仅额外占用snapshot卷的空间,而且导致额外的I/O操作。几个优化方法会避免这些额外的开销,例如变化的Block大小。但是这些优化通常需要在Hash表中额外的数据结构。这样会导致Hash表非常复杂但优化效果依然可以看到。
SVM快照使用描述
如下图所示,假如生产数据的原始卷是存储区域(1)(假设只包含1-16个数据块,用对应序号所示),如果系统要在时间点10:00时对原始卷做快照(SnapShot),SVM首先将原始卷冻结,同时开辟临时存储区域(2)(缺省初始大小256M,其大小随着数据块改变量的增加会由SVM控制动态改变 ),同时创建对应的数据块指针表(用于为文件系统重新定向被应用改变的数据块指针),也就是说,从时间点10:00开始,到下一个时间点(例如 11:00)快照建立之前,应用程序对生产原始卷对应的数据块的改变都以紧密排列方式相应地写到快照_01的存储区域(2),(例如 被改变的块 2、4、5、8、9、11、16),此时生产系统将根据SVM为其定向的文件系统数据块指针,同时访问原始卷和快照_01,原始卷为只读(暂时不可改写,固态方式保存时间点10:00之前的生产卷的真实数据),快照_01为读写属性(动态方式保存时间点10:00之后原始生产卷对应数据块的改变状态)。此时从应用的角度看来,存储区域(1)和存储区域(2)合为当前的生产卷;
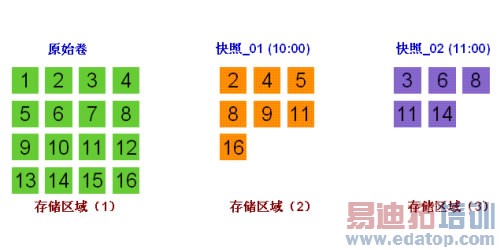
同理,当时间点11:00的时刻创建快照_02时,系统会将这之前的快照_01和原始卷同时冻结,也就是说,从现在开始,原始生产卷对应的数据块的改变,将全部动态地记录到快照_03对应的存储区域(3)之中,此区域和先前冻结的快照_01以及原始卷,合为当前的生产卷,应用程序将根据SVM为文件系统定向的指针,访问当前的生产卷,而此之前冻结的快照_01和原始卷,以只读方式记录着时间点11:00之前生产卷的数据状态;
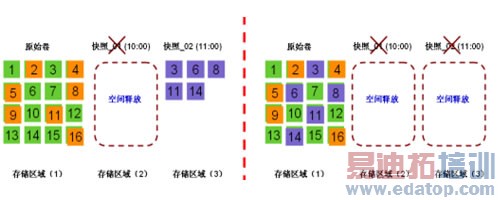
当对快照删除或系统从快照进行数据回滚时,对应的快照中的数据块将回写到它之前的存储区域中,如下左图所示,如果删除快照_01,其当中保存的此期间的数据块的变化量,将按块序号一一对应回写到原始卷的对应块的位置(Merge),原快照_01对应的存储区域(2)将释放为自由空间,以备之后用于其它的快照临时存储空间创建;
同理,如果删除快照_02,将发生如下右图所示的类似情况,原快照_02所对应的存储区域(2)也将释放为自由空间,系统中不存在小的碎块在存储中遍布的情况;
PIT快照技术在电信数据容灾上的使用
从以上的原理描述中我们可以看到,Redirect-on-write快照技术能通过指针的重定向,保留各个时间不同的数据版本。而这些数据版本能让用户快速的将应用切换到以前不同的时间点。大家看看下图:

Source卷中的数据到拍第一个快照的时候就冻结了,比如9点中,我们开始做第一个快照PIT1,那么所有的数据新增及变化都将加入到PIT1的卷中。到了10点,我们做第二个快照的时候,又将SOURCE和PIT1卷都进行冻结,而10点以后的所有数据变化都将放入PIT2卷中。 大家可以看到这样的好处就是,我们同时保留了9点,10点,和现在的生产数据。 并且以前的数据版本可以生成VIEW给别的机器使用。 这样的系统,第一可以作为一个很好的测试系统, 每个测试人员都可以针对自己想要的数据进行测试,而不对生产系统造成影响。 第二,将每个PIT卷复制到容灾站点就可以进行数据的保护及容灾。并且UIT SVM设备独有的通过IP 的断点续传功能能保证,将数据传递到世界的任何地方。 如图:
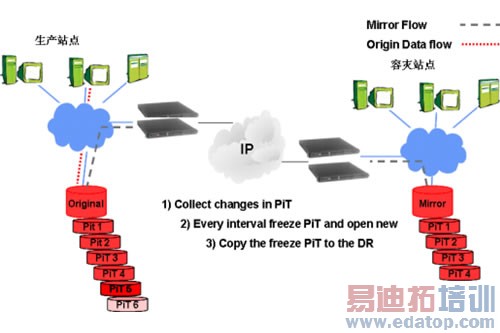
生产站点定期的做逻辑快照,将新增和变化的数据放在新的快照卷中,然后将冻结的快照卷不断的复制到容灾站点,和传统的容灾方式比较: UIT 的PIT快照技术能让容灾端随时查看复制过来的结构化数据,并且不需要带宽上有很高的要求。
创新科存储(UIT)的PIT快照技术颠覆了传统的磁盘式容灾,容灾站点随时查看数据使容灾系统的功能多元化,不仅可以做容灾中心,也可以作为数据查询中心和报告及数据统计中心。 在电信级的高可用数据保护需求下,相信创新科存储(UIT)的PIT快照技术能在数据容灾及保护领域发挥更大的作用。
来源:C114
上一篇:IP化核心传送网解决方案
下一篇:采用混合信号FPGA实现智能化热管理

