- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
基于嵌入式TCP/IP软件体系结构的优化设计与实现
录入:edatop.com 点击:
随着计算机网络技术和电子信息技术的迅猛发展,Internet的普及,接入Internet的非PC设备越来越多,各类电子设备像Web个人数字助理、Web可视电话、TV机顶盒接入Internet的需求也越来越大,嵌入式TCP/ IP的Internet网络化将成为网络发展的趋势。
嵌入式系统中大量存在的是8/16位低速处理器,在进行Internet接入时,嵌入式TCP/IP对于计算机存储器、运算速度要求比较高,占用大量系统资源,因而常嵌入TCP/IP协议簇的子集或用UDP代替TCP实现。
本文提出一种基于嵌入式TCP/IP软件体系结构的优化设计和实现方案,从实现相应的功能又节省系统资源角度出发,对嵌入TCP/IP优化设计,实现嵌入式的Internet接入。
嵌入式TCP/IP接入方法
嵌入式电子设备接入Internet有多种解决方案:如在低速微处理器运行剪裁的TCP/IP协议栈;使用一些ASIC实现TCP/IP的芯片如ADI的Internet Modem;也可以使用嵌入式操作系统自带的完整的TCP/IP协议栈。在某些对网络速度要求不高的领域,可以精简的TCP/IP实现;在对性能要求高的场合,则可以选择后两种方案。嵌入式设备接入Internet网络常用的方案比较如表1所示。

但以上接入方法一般专门为某种微处理器设计,不具有通用性,而且效率较低或功能不够全面。本文提出的经过优化设计的嵌入式TCP/IP适合移植到各种嵌入式处理器中,如单片机、ARM或ARM+FPGA多核嵌入式处理器中,具有较小的代码量、RAM使用量和较高的效率,同时支持套接字形式的多个TCP连接和多个网络设备连接,支持通过网关发送数据包和数据包转发,支持TCP包的整序、重发和窗口控制流量控制等等。
嵌入式TCP/IP的软件体系结构与优化设计
嵌入式TCP/IP软件体系结构
与PC TCP/IP协议相似,嵌入式TCP/IP采用协议分层的结构:应用层、TCP层、IP层和网络设备接口层图1描述了嵌入式TCP/IP输入和输出数据包流程以及调用的函数。
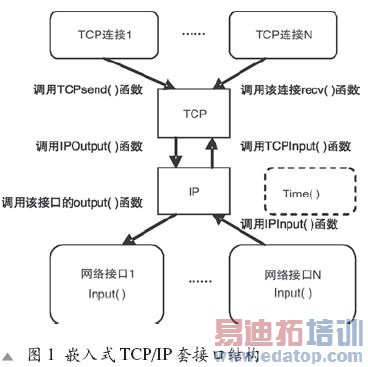
其中,Timer()函数调用TCPTimer()处理TCP数据包重发,以及调用每个接口的Input()函数接收到达的数据包。Timer()函数必须在短时间(一般<20ms)内被调用一次,否则接收数据包和TCP定时等功能将停止。
输出时,TCP层先查看unsend队列,发现非空,将数据包插入队列;发现为空,则查看对方窗口是否够大能够接收这个数据包,然后填写TCP头部信息。IP层选择网络设备接口,目的IP和该接口的子网掩码相与是否等于子网掩码。然后调用这个接口的Output函数来发送。
输入时,Timer()函数调用每个接口的Input函数。IP层判断IP版本、IP校验和、判断是否应该转发数据包,然后根据IP头部的protocol字段将包传给相应的高层处理。TCP层,需要判断TCP校验和,然后在现有的套接字中查找,判断是否有套接字可以接收这个数据包,判断TCP序号是否为希望的,然后更新这个连接的状态(包括释放被应答的数据包和TCP状态机的转化等),调用该套接字的回调函数recv。
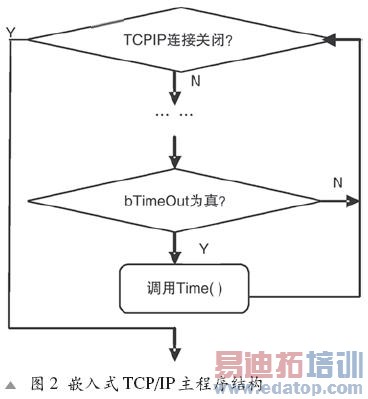
图2程序主流程是一个大循环,在循环中处理发送数据包等应用层协议同时查询变量bTimeOut,在定时中断中将bTimerOut设置为真,应用层在程序流程中反复查询bTimerOut是否为真,真则调用Timer(),然后置bTimerOut为假。
嵌入式TCP/IP设计优化
因为网络中数据非常多,如果把所有的数据都读到内存中再判断是否应该丢弃帧显然效率不高。所以边读取数据边判断而没有一开始就把整个帧全部读到内存中,同时在程序里定义帧中各个部分的相对地址,可以方便的对帧的各个字节寻址。这样的设计是基于提高访问速度考虑的。
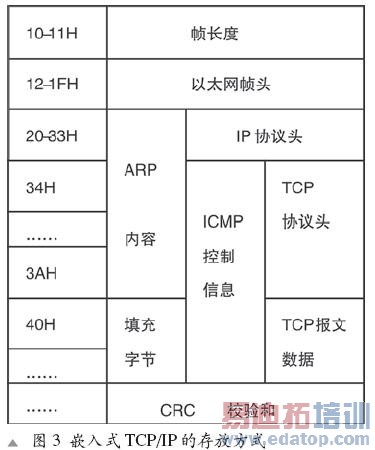
为了减小RAM使用量,当数据包需要重新发送时,如果能够重新产生数据包所需的数据,可以不存储需要被应答的TCP包。图3给出了嵌入式CPU中TCP/IP的内存划分,以及内存中帧的各个字节的定义和相对位置,其中PacketRAM为存放帧的首地址。
发送TCP/IP过程中主要的运算量集中在三个部分:应用程序将数据拷贝到RAM、计算TCP校验和、将RAM中的数据包拷贝到网络设备的发送缓冲区。对每一个字节数据,两次拷贝大致共使用12×2=24个指令周期;计算TCP校验和使用为16个指令周期。为提高速度可采用快速CPU或提高晶振频率。例如采用12M晶振时,网络传输速度为25K字节/s;而在高频PCB电路板使用233M晶振时,网络传输速度能达到为384K字节/s。
另外,TCP/IP一般采用C语言或者混合汇编,而使用可重入函数和一般指针(generic pointer)使得程序代码增大,运行速度变慢。所以使用函数指针时,应手动重建调用树(Call tree),或将函数指针调用的函数设置为可重入函数,同时使用"指定存储类型"的指针(memory-specific pointer),防止数据包的不必要的拷贝以及优化计算校验和和内存拷贝函数。另外,Reentrant类型的函数比一般函数速度要慢很多,但是某些时候为了程序结构的需要必须使用Reentrant,这就需要在速度和结构之间作一个选择。
嵌入式TCP/IP的实现
TCP/IP的嵌入式实现一般通过以软件方式嵌入到ROM中,然后通过轻网络通讯技术与专用嵌入式网关连接,在嵌入式处理器中运行TCP/IP协议,提供TCP/IP到用户的轻型网络的连接和路由功能。
内存管理方法和无多余数据包拷贝的实现
嵌入式TCP/IP的内存管理可以用链表方法,即根据数据包大小分配相应大小的内存块。如图4所示,链表将内存块链接起来,used字段表示该内存块是否正在使用,pSstart和pEend则表示数据部分有效数据的开始地址和结束地址。
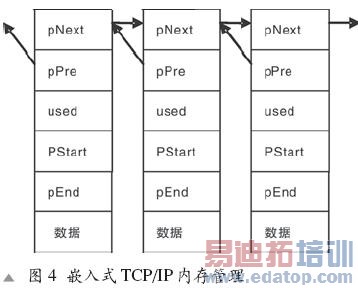
分配时,搜索内存链表找到一个没有分配的比所需空间大的内存块,截取所需的大小。该内存块被截取以后可能还有较多剩余,这时将剩余部分从原内存块中分离出来,成为一个新的内存块,并插入链表。释放时,将used值置为假,如果pNext或者pPre指向的链表单元也是空闲的,则将其和自己合并,以防止内存分片。在协议层之间传送数据包只需传送内存块的起始地址。这种内存管理方法空间浪费小但是运算量相对较大。
整序、重发和窗口控制的实现
对于嵌入式TCP/IP系统,可以使用队列缓存的方式来实现整序、重发和窗口控制。队列的一个元素指向一个数据包,队列的最大长度没有限制。
对于整序,使用ooSeq队列,如果发现接收的TCP包序号并不是期望的,但序号在接收窗口内,此时不能立刻接收这个包也不应丢弃,可先将这个包放入ooSeq队列。当期望TCP包被接收后,再查看ooSeq队列现在是否有TCP包成为了期望的数据包,如果有则将其取出并处理。
对于重发,使用unacked队列,每一个需要被应答的TCP数据包发送以后都要放入unacked队列,等到被应答以后才从队列中删除。TCP重发定时只针对unacked队列第一个TCP包,如果定时超出,重新发送,重发次数超出规定值,则报错。
对于窗口控制,使用unsend队列,如果发现对方的窗口过小无法接收这个数据包,则只发送部分数据,将多余部分放入unsend队列,等待对方发来TCP包通知新的窗口大小时,再次判断是否可以发送。如果在unsend队列不为空的情况下,需要发送的数据包都应插入unsend队列。
嵌入式TCP/IP的性能分析
图5给出了将优化设计后的TCP/IP移植到ARM9处理器、CS8900A网络控制器中,时钟频率为133MHz下,与Internet连接的情况。
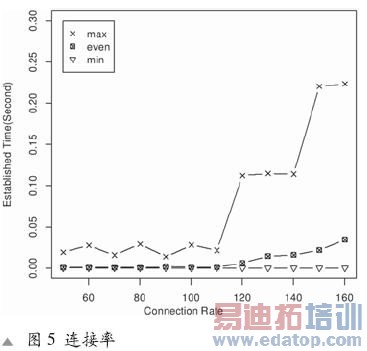
系统支持最大发起连接数约为380,最大并发连接率约为170cps。随着呼叫数的增加,平均分组到达也随之增加,导致网络传输数据的增加,从而最大建立时间变长。但最小的建立连接时间基本保持不变,说明系统具有良好的性能。
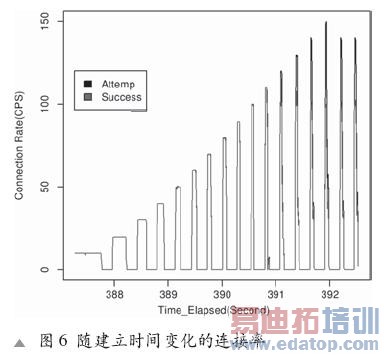
图6给出了随建立时间变化的接通率。图中存在一个临界点,成功的连接率随着TCP连接尝试数目增加而减少,直至为0,而响应时间也急剧上升,这是由嵌入式处理器的处理能力有限造成的。
结语
本文从实现相应的功能又节省系统资源角度出发,对嵌入式TCP/IP协议簇进行优化设计,可以在各种嵌入式处理器上实现Internet接入。
经过优化设计的嵌入式TCP/IP支持套接字形式的多个TCP连接、支持多个网络设备、支持通过网关发送数据包和数据包转发功能,以及支持TCP包的整序、重发和窗口控制流量控制。实践证明,这种设计方式灵活,能按用户需求实现复杂的功能。
作者:北京邮电大学 电信工程学院 廖日坤 纪越峰 来源:电子产品世界
上一篇:成熟领先、面向未来的全IP解决方案
下一篇:FPGA用做数字信号处理应用?

