- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
基于龙芯3B的H.264解码器的向量化
录入:edatop.com 点击:
对于图2(a)中的运算,原始计算是P向量内部的运算,因而无法向量化,我们用向量指令将p向量转置为q,其中q0存放p中标号为1的数据,q1存放P中标号为2的数据,依此类推。转置得到的q向量就可以用图2(b)中的向量指令运算,得到的运算结果与原来的运算相同。
对于13~15号函数的优化,同样使用到了上面的转置方法。而4.1节的测试结果则说明了各个函数的优化效果。
4 实验结果
4.1 ffmpeg各函数加速比
本文分别对向量化后的各个函数进行了测试,并且与未向量化之前的函数进行了比较,各个函数向量化优化后的加速比如图3所示。其中图中横坐标所示函数序号与表2中的各个函数一一对应。
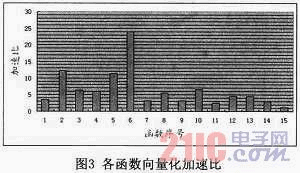
图3中的函数的加速比所跨越的范围较大,比如6号函数的加速比约有23.9左右,而最后一个函数的加速比只有1.2左右。之所以会出现上述情况,除了与改进后的函数所使用的向量指令的数量和修改代码的比重有关以外,也与运算所使用的操作数的类型有关。对于6号函数,其循环内的运算所使用的操作数的类型为字节类型,因而仅仅使用向量指令进行优化,理论加速比就可以达到32,不过本文仅仅对该函数的内层循环进行了向量化,而向量化后的内层循环一次仅仅处理了 16个字节类型的数据,即并未充分使用256位的向量寄存器。因而理论的加速比应该为16,但是由于结合了循环展开和指令调度等其他优化策略,因而实际的加速比可以达到23.9左右。同样,对4号、5号和6号这三个同类型的函数进行分析,我们也可以发现:后一个函数的加速比均约为前一个函数加速比的两倍。这是因为对于4号函数,内层循环向量化后一次可以同时计算4个字节类型的数据,而5号函数可以同时计算8个字节类型的数据,因而理论上的加速比也应该是两倍的等比数列形式,而实际结果与理论分析是一致的。
对于3.3.2小节中重点介绍的7号函数和8号函数,其原函数无法进行简单向量化,而本文使用了掩码以及矩阵转置等优化方法,使其能够使用龙芯3B的向量扩展指令,因而尽管性能提升不大,但是加速比也分别有3.2和5.5。
4.2 不同平台上的向量化比较
本文同样将ffmpeg解码器分别在不同的平台上进行了测试,使用的两个测试视频分别为是"问道武当002.mkv"(视频A)和"walk_vag_ 640x480_qp26.264"(视频B)。其中视频A是问道武当视频(720p)中截取的片段,而后者是通过x264对walk_vag.yuv(480p)编码生成的,编码时选用的qp值为26。而测试平台则分别选择了AMD和Intel处理器平台。

从表3的测试结果可以看出对于视频A,在龙芯3B上的性能提升比其他两个平台上都高很多;而对于视频B,在龙芯3B上的性能提升也与其它两个平台接近。实验结果表明:在龙芯3B上实现ffmpeg解码器的向量化,对性能提升有很大帮助,而且解码某些视频时,性能的提升甚至高于性能优越的商用处理器。而通过与表1中使用GCC向量化编译的结果进行比较,也可以看出:手工对ffmpeg解码器进行向量化比使用GCC进行向量化,性能有更大的提升。
5 总结和展望
本文实现了ffmpeg解码器到龙芯3B的移植,并针对龙芯3B实现了对向量扩展指令支持的特点,对ffmpeg解码器进行了手工向量化。实验结果表明:手工向量化后的ffmpeg解码器的性能比使用GCC向量化编译后的ffmpeg解码器性能要好很多,而且性能的提升也比Intel和 AMD平台更多。
本文仅仅从代码级实现了针对龙芯3B的ffmpeg解码器的向量化移植,为了进一步提高性能,还需要从整个算法层面上进行优化。另外,由于龙芯3B的多核特性,还可以考虑使用多核进行解码。
作者:裴晓航 何颂颂 中国科学技术大学 来源:现代电子技术

