- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
基于802.16d的定时同步算法改进及FPGA实现
录入:edatop.com 点击:
利用这种改进的自相关算法和延时自相关算法进行联合估计的仿真曲线如图2所示。
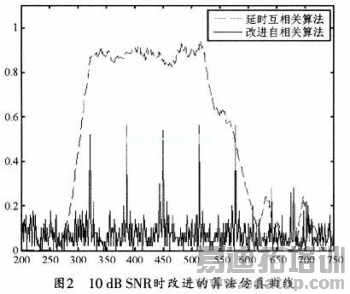
10dB SNR时改进的算法仿真曲线
将图1和图2进行对比可知,这种对接收数据二阶量化的方法会损耗算法的性能,但是,由于帧的大致位置已被限制在一定范围之内,因此,只需根据峰值就可以确定下一个OFDM符号的准确位置。这种方法既能保证估计精度,又能满足硬件资源利用率的要求。
4 基于FPGA的实现
4.1 自相关延时模块的FPGA实现
为了进一步简化运算,也可以不进行算法中的归一化运算,而直接计算R(n)的值,并将公式简化为:
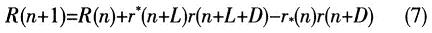
公式
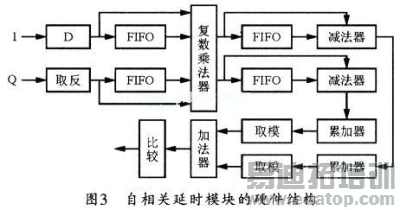
图3所示是自相关延时模块的硬件组成结构。它主要由FIFO延时单元、复数运算器、加法器、取模模块组成。其中复数乘法器可直接使用IP核来实现,这比直接使用四个实数乘法器和两个加法器更节省资源。
自相关延时模块的硬件组成结构
将接收端经过下变频的I路和Q路数据分为两路送入模块,I路比Q路数据应多延时一个时钟周期,这是为了和Q路数据保持相同的时延,此后再进入 FIFO经过64个时钟周期的延时。Q路数据首先进行取相反数运算。这是因为复数共轭运算相当于先取相反数再做复数乘法。把相减的结果送入FIFO进行延时,并将送入系统的复数与做减法和延时64个时钟周期的复数进行复数乘法运算。由于两路数据都是16位定点化整数,经过运算后会成为33位,为了节省资源,可将所得结果的高5位和低12位截去,而这并不会影响运算的精度。经过复数乘法运算的实部和虚部再分别经过64个时钟周期的FIFO延时,并将延时前后的数据做减法运算,然后对计算的结果做累加运算。累加器输出的结果经过取模模块后,即可得到实部和虚部的绝对值,然后将两部分结果相加,再将相加结果与门限值比较,超过门限则将标志位置高。但应注意门限值的选取会影响帧检测的范围,由于采用的是联合检测方法,应适当扩大门限范围,本设计设定的门限值为峰值的1/4。
4.2 互相关模块的FPGA实现
互相关模块主要由匹配运算单元、取模器和加法器组成。改进的算法只对输入数据的符号位与本地序列的符号位进行相关运算,并规定输入符号为正取值为1,输入符号为负取值为-1,接着根据输入数据的符号和本地序列的符号构成的16种输入做全排列,将所有可能的相关运算值算好存放在运算模块中,这样就可以根据输入数据的符号来选择相关运算的结果。这等效于把复数相关运算简化为数据选择器来实现。
图4所示为互相关模块的FPGA实现框图,其中I、Q两路数据进入模块后,可取出其最高位存入移位寄存器,然后与本地序列做匹配运算。匹配运算模块由64个数据选择器和126个加法器组成,加法运算采用6级流水线来实现,这样,可使系统的运算速率更高。
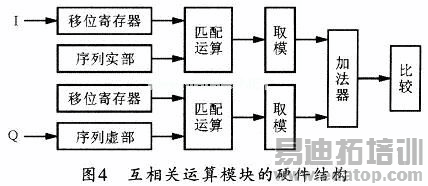
互相关模块的FPGA实现框图
4.3 仿真结果分析
系统中的各模块可采用Verilog HDL语言设计,并可使用Xilinx公司集成设计环境ISE中的ModelSim SE 6.0来完成仿真,仿真结果如图5所示。其中frame_re_dout和frame_im_dout为送入系统的实部和虚部数据,abs_out为延时自相关算法中取模相加的结果,frame_head为采用延时自相关算法使数据升高时得到的一个峰值平台,top_flag为改进自相关算法计算所得的峰值。图中的自相关平台内有5个峰值,这与MATLAB仿真结果相符。最后采用Xilinx公司VirtexⅡpro系列xc2vp30器件进行实现。总共逻辑单元使用率为8%,系统最高工作频率为236.373 MHz 。

仿真结果
5 结束语
本文在研究基于802.16d的OFDM定时同步算法的基础上提出了一种改进的算法,并在FPGA上完成了其硬件电路设计。仿真结果表明该算法在保持了原算法优秀性能的同时,可节省硬件资源,有利于把同步模块和接收部分其他模块集成在单芯片中。同时,该算法也可推广到具有相似前导字结构的 802.1 1a等协议中。
来源:电子设计技术论坛
