- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
GPU通用计算渐成热点,众厂商逐鹿未来高并行性计算市场
录入:edatop.com 点击:
图形处理器(GPU)用于通用计算(GPGPU)及其相关方面的问题目前已成为一个热门话题。事实上,整个IT产业都已经敏锐地意识到了GPU通用计算将给PC带来革命性的变化,进而影响到CPU的发展。因此,无论NVIDIA、AMD,还是英特尔,都纷纷投身这一领域,从而拉开新一轮技术竞赛的序幕。
GPU流计算的关键障碍
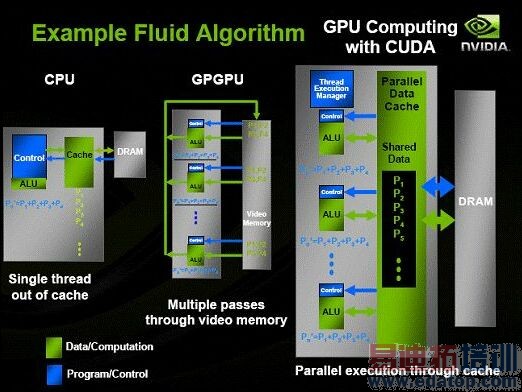
因为具备强大的并行处理能力和极高的存储器带宽,GPU如果用于处理诸如金融分析、地震预报、医学影像、流体模拟等需要大量重复数据集运算的应用程序,就有可能获得比CPU强大得多的计算能力。相比之下,由于CPU本身为顺序任务设计,浮点运算能力不足,即便采用多核架构,并行处理能力也是有限的。
GPGPU早在DirectX 9.0时代就已经初现雏形,但只有在DirectX 10时代,新的GPU才真正促进了GPGPU的成熟和高速发展。在硬件方面,以NVIDIA GeForce 8800 GTX为例,通过集成多达6.81亿枚晶体管,使之具备了万亿次浮点(Teraflops of floating point)处理能力,峰值带宽达到了86.4GBps。同时,8800采用统一着色器架构(Unified Shader),内含128个标量32位浮点精度流处理器,完全支持Shader Model 4.0,在可编程性上获得了很大的提高,因此也为GPGPU在新时代的应用带来了更多的可能性。
但实现基于GPU的通用计算并不仅仅是靠晶体管数量的堆砌竞赛就能实现的。从软件开发环境来看,GPU本身是为图形渲染而设计,只能处理图形渲染指令,而科学计算指令属于通用指令,两者之间存在显著差异,如果要让GPU来进行科学计算,就必须对科学计算程序进行改写。这就要求程序员必须熟悉GPU硬件架构,然后再进行编程。而且,GPGPU或基于GPU的通用计算,一直要求使用诸如OpenGL类的图形API,这种方案会在通用平行计算中遇到提取错误的问题。因此,传统的应用软件很难进行写入、纠错和优化操作。
NVIDIA CUDA 计算处理技术
为了降低开发难度,NVIDIA 推出了CUDA GPU计算处理技术。CUDA是一种全新的、用于开拓GPU运算性能的软件架构。它内含标准的FFT和BLAS(稀疏矩阵)数据库、一个NVIDIA GPU和一个独立运行驱动。该驱动可与OpenGL 和Microsoft、 DirectX以及NVIDIA 驱动进行相互操作。目前,Linux 和Microsoft Windows XP 操作系统均支持CUDA 技术。
赋予GPU多线程功能,是CUDA技术最为重要的创新举措之一,其运算速度远远超过了使用传统架构或使用有限图形API GPU计算方法。那么同样作为并行的数据处理模式,为什么选择CUDA而不是FPGA? NVIDIA GPU计算事业部总经理Andy Keane表示,以金融业分析证券为例,如果使用FPGA在发生变化时要重新设计,而CUDA则不需要,开发人员可以直接改变程序,这样更便于应用,而且增强了可编程性,这就是CUDA跟编程语言的区别。
随着使用者越来越多,NVIDIA公司还开设了一个专门为高性能计算(HPC)开发人员提供服务的资源社区——CUDA Zone。站点功能涵盖编程技术发布、客户聚焦、项目张贴和方法交流的论坛、CUDA工具的下载、代码实例、新闻事件等诸多内容。
正是基于G80和CUDA技术,NVIDIA迅速推出了自己的通用计算品牌Tesla,可以为普通PC机、大型集群服务器提供强大的计算处理能力。目前,NVIDIA一共推出三个Tesla产品系列,分别为Tesla GPU高并行计算处理器(C870)、Tesla桌边型超级计算机(D870)和Tesla计算服务器(S870)。
作为目前唯一可以买到、且技术相对成熟的GPU高并行性计算平台,NVIDIA理应引以为傲。但Andy Keane还是强调,目前CUDA仍然是基于NVIDIA的产品来进行推广,而在计算领域里,只有开放式的架构和技术才能够有生命力,所以CUDA会慢慢的把它放在CPU、或者其他的GPU上面运行。但公司并不会强调行业接受这个技术,而是希望推出一个平台,让业内人士共同开发。
需要承认的是,目前的CUDA技术并不完美。程序员在利用该项技术时,需面对不同的存储器和复杂的线程层次,很多任务编译器也都无法自动完成,从而增加了程序的开发难度。但是,随着CUDA技术的不断演进,相信类似问题会逐步得到解决。
NVIDIA CUDA计算流程
来自英特尔和AMD的狙击
面对NVIDIA咄咄逼人的气势,AMD和Intel自然不能无动于衷。在AMD宣布并购ATI成为一家平台厂商的时候,其力推的"CPU+GPU"概念就名声大噪;而Intel本身具有一定的图形开发能力,谋求开发高端独立图形产品也是明智之举,尽管这多少让人觉得有些迫于无奈。
AMD R700 其实,率先拉开GPGPU竞赛大幕的是AMD R580(即Radeon X1900)。根据AMD的构想,即将于2008年5月上市的R700将是一款真正意义上的多核架构,采用45纳米工艺,具备高效的多芯片协作能力,支持DX10.1、镶嵌式铺装技术(Tessellation),并有可能支持DisplayPort接口。通过多芯片的组合,一个R700 GPU芯片,就可以同时实现产品的多元化组合,实现了快速过渡和低成本。借助R700的力量,AMD可以构建起一套完善的协处理器加速平台,与英特尔和NVIDIA分庭抗争。
不过软件开发环境有可能会成为R700的软肋。AMD为客户提供CTM瘦硬件接口,允许开发者直接访问GPU的原生指令集和存储器,以便发挥出GPU的流计算能力。然而CTM仍然属于硬件接口之列,开发者必须深入了解硬件才能够开发出相应的计算程序,这项工作显然相当复杂。
英特尔Larrabee 在英特尔的规划中,高并行性计算能力已经被提高到了战略的高度。而Larrabee正是这一战略布局下出现的高并行计算处理器,是其Many Core超多核架构的第一代产品。NVIDIA Tesla目前所达到的成就是英特尔Larrabee项目所梦寐以求的。英特尔总是被业界称为产业大师,但Larrabee能否获得业内厂商的支持?一是要看软件开发是否简单易行;二是看硬件平台能否提供足够的吸引力。
在指令体系上,Larrabee最大的优点就是与IA架构(X86)处理器的互换性,它使用经过调整的X86指令,使现行X86计算程序可以直接被Larrabee运算执行。这样,开发者就能很容易的开发出针对Larrabee平台的计算软件,而不需要再去深入研究硬件细节,并且也同时保证了软件的兼容性。不难看出,英特尔是希望Larrabee能够重复当年X86市场的成功,即通过创建指令集标准来赢得领导权。
在硬件设计上,Larrabee采用微内核设计,内核逻辑采用顺序执行结构(In Order),可同时执行4个线程。英特尔透露,Larrabee采用512位宽环形内存总线,搭载1GB-2GB容量的高速显存,总带宽将达到128GBps,工作频率为1.7-2.5GHz,可获得每秒万亿次浮点计算能力。在3D图形方面,Larrebee支持JPEG纹理、物理加速、反锯齿、增强AI、光线追踪等特性,光线追踪特性更是它的一大卖点。
根据规划,英特尔将于2008年中期推出包含32个内核、45纳米的第一代Larrabee芯片,并同时搭配大容量缓存,功耗约为150瓦左右。为了满足多元化的需求,还将衍生出24内核的低端版本。大约在2009-2010年,英特尔还将推出具有48个内核、32纳米工艺的第二代Larrabee芯片。
针对此方案,AMD CTO Hester表示,X86指令集的通用性固然更好一些,但它的执行效率并不好,并不适合高性能的并行计算处理。AMD采用分离设计,将GPU指令集整合于CPU之内,作为CPU指令集的补充。NVIDIA首席科学家Kirk博士也似乎表达了同样的看法,他认为X86互换性会给流处理器设计带来难度,而NVIDIA则是针对GPU开发适合流计算的架构。很明显,NVIDIA/AMD未来都不可能轻易向英特尔的指令集妥协,彼此在未来高并行性计算领域的竞争是可以预见的。
几年来,GPU在通用计算上所开辟的应用及相关研究工作取得了非常大的进展,图形产业将进入新的时代,而终端用户也必将会从中获益。所谓"合久必分,分久必合",到时,显卡这一名词也许将会成为历史,取而代之的将会是具有图形加速功能的流处理器。
作者:邵乐峰

