- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
自动化测试在动态文档发布系统中的应用
录入:edatop.com 点击:
0 引言
对于大多数人来说,都会有这样的客户体验:去银行或者保险公司办理业务,或者接收他们的保单宣传,我们所面对和接收的都是一张张一样的表单,然后上面有一些空白的表格或者下划线,然后将客户的信息填上去。这样的做法有以下两个缺点:
(1)客户体验差。所有客户拿到的都是一样的表单,因为考虑特殊的情况,表单里面的空白的地方都会比较大,所以一般会出现大片空白的区域。
(2)对于每种不同的客户或者不同的业务会需要不同的表单,对于客户信息变动的情况,需要人工完成,比较繁琐。
为了更好的客户体验,越来越多的公司倾向于采用动态打印技术。这样每个客户接收到的文档或者打印件都是定制化的,这样就能克服以上缺点而做到:
(1)客户体验优。所有客户拿到的文档都是定制化的,表单里没有需要填空的地方,客户的数据都会被程序动态地植入表格模板里,就好像专门为客户定做的文档。
(2)我们可以在模板中定义一些规则,然后根据客户数据来采用相应的规则。例如,美国各个州的法律是不一样的,我们可以在编辑文档的时候就定义规则:如果客户是A州的,就用A条文,如果是B州的,就用B条文。这样当生成文档的时候,程序会根据当前客户是属于哪个州的,动态地加入这一段条文,而不需要人工的判定。并且,当客户从A州搬到B州,我们只需要更新一下客户的数据,客户下次就能拿到更新的正确的文档。
1 动态文档发布系统
有了如上的需求,很多公司都加入了开发动态文档发布系统的行列。对于动态文档发布,简单说起来,一般的步骤是:1)建立文档模板,2)运行时,装载客户数据进入模板,3)拼接文档,4)排版,5)输出前处理,6)输出成不同格式的文档,7)发布和归档。
动态文档发布系统可以使客户高性能制作并发送设计精美、高度个性化的沟通材料,从合同、保险单、大批量的账户关系维护通知单,到定制的推广资料、商业信函等。客户可以在该系统平台上,运用自己熟悉的文档开发软件,如Word、Adobe Indesign、Dream Weaver,开发出文档模板,并根据系统提供的插件进行逻辑的设置。然后,该模板就能被送往系统,跟随提供的客户数据而批量地生成客户需要的定制文档。接着,生成的文件可以通过不同的途径,例如,邮件、e-mail、手机短信等方式发送到客户,使客户有良好的用户体验。
2 自动化测试的要求
对于这样一个复杂的系统,它的主要客户是一些保险公司和银行,而它的主要产出是保单和合同。同时,合同和保单都是很严肃和很严谨的文档。客户需要的是他们的客户在客户数据没有改变的情况下,得到的是一贯的体验。
但是同时,动态文档发布系统本身又是一个不断发展和改善的系统。它拥有非常复杂的排版逻辑,并且每个版本的升级都会有大量的新功能和新逻辑被引入,这样的逻辑改变如果哪怕有一点点的差错,原来客户的整个文档可能就会面目全非。如果老的客户需要升级这些新功能的话,我们需要保证客户得到一贯的体验。也就是说,他们用旧的版本系统生成的文档和在新的版本系统生成的文档要保持一致,除非新的版本生成的更好,并得到客户的同意。
这样,为了达到上面的目标,我们需要在新版本发布前,运行一些老客户的文档(挑选一些很典型的客户文档),并且一个个和老版本生产的文档进行比较。但是我们不能把这个过程推到新版本发布之前才做,因为那个时候整个项目已经积累了很多的不同点,很难追查到源头并加以改正。所以我们需要把这个过程提前,并且频繁地去检查。
由于需要频繁的检查,并且文档的比较是个很繁重的体力活,所以自动测试将会是很好的方法,它不仅能够节省绝对的人力,而且能够保证绝对的准确,不会被人为因素干扰。
我们可以把这个自动测试集成到日常的打包系统中,每次打包后就可以自动地完成运行,比较和生成报告。
但是,我们不能在打包服务器上每次都去部署新的系统,因为那样太笨重了,并且会让环境问题和我们系统本身的问题经常性地纠缠不清。所以,我们需要自己建立一套轻量级的架构去承载这个测试过程:
(1)我们的系统是建立在基于应用服务器的EJB架构上的,并且EJB的主要操作是基于对数据库的操作,但是我们对于该自动测试的系统的要求是,对外部的依赖越少越好,因为这样的话,我们就能很方便地在各个相关程序员和测试人员以及配置人员之间进行部署和实施,所以我们希望他不要依赖应用服务器和数据库。
(2)我们要明确输入源和输出源,并且能够提供一些简单并且方便的配置,而且在很小代价的前提下,能够在不同的输入源和输出源之间随意切换。
(3)结果必须是可以有办法鉴别的,并且鉴别结果是能够很容易取得和方便查阅的。
3 设计方案
根据上面提出的三个要求,我们将通过分析我们的系统来提出我们的解决方案。
3.1 分析
对于这个系统来说,我们首先需要解决对于应用服务器,也就是对于EJB的依赖。为了达到这个目的,我们必须对系统的主要模块进行分析,来想办法如何解除依赖。
3.1.1 系统主要模块介绍
我们可以看看此系统的一个特别简化同时又很典型的流程:
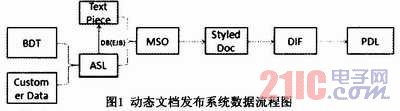
首先介绍一下每个术语:
BDT:Business document template,商业文档模板。在这里我们定义一些规则,然后会跟客户数据关联选择具体的规则。
Customer Data:客户数据。XML格式记录特定客户的数据,然后根据这些客户数据,动态产生不同文档。
ASL:Assembly List,装配列表。由BDT和客户数据装载生成,里面记录的是一个个根据规则而选出来的最终文档片段(text piece)。
Text Piece:文档片段。在客户端定义,并存储在数据库端的文档片段。
MSO:微软自己定义的HTML格式Microsoft HTML,然后我们在里面加入一些我们自己定义的标记。
Styled Doc:式样文档。我们定义的一个格式,其实就是一些结构类,会对文档的各个内容、样式、布局进行描述。
DIF:Document Independent Format,独立文档格式。StyledDoc经过CE(composition)排版的结果就是DIF。它是一个页面级别的概念,告诉你什么时候生成一个新页面,多大,在哪里用什么字体写些什么字,在哪里放一个什么样的图片。
PDL:Page Description Language,页面描述语言。我们需要生成的最终结果,就是那些用页面来表示文档的语言,例如,Word、PDF、AFP、Postscript等等。
从图1可以看出,我们的EJB主要用在对数据库的操作上。对于数据库的操作,主要是对数据模板(BDT)的提取,然后和本地客户数据进行整合,进而得出需要真正从数据库取出数据的组合(ASL),最后进行后面的排版(CE)、计算,生成各种不同类型的文档。
3.1.2 解耦数据库
既然我们要去除EJB和数据库的束缚,我们能不能绕过去呢?进一步分析,我们得到,数据模板在和客户数据装载(Assemble)后会在数据库里生成一个xml文件,用来描述最终会用到的具体的存在于数据库中间的文本片段。而这个xml文件,我们称之为ASL。我们试想,如果我们用一个办法,直接生成我们要用到的ASL文件,那么我们是不是就可以绕过EJB和数据库了呢?
答案是一半肯定,一半否定。首先,我们的确能绕过EJB的应用,它主要用于assemble这个阶段。但是光有ASL是没有用的,因为我们还需要通过ASL去数据库里取得所有的文本片段去做整合(Merge)。那么我们能不能把输入进一步地往后面推,推到Merge以后呢?答案是不能。首先来说Merge的输入也就是文本片段会有很多,他们之间的关系很复杂,这些都是记录在ASL里面,并且,Merge本身就是一个比较容易出问题的模块,是我们做这个Test Client要重点模拟和测试的模块,所以我们只能另想办法。
这里我们大概介绍一下通过ASL去数据库取文本片段的过程。这个过程其实比较简单,因为逻辑方面的运算已经在Assemble的过程中处理完成,这里的任务是根据ASL里面的一个个的文本片段ID去数据库里取出相应的数据来进行后续的流程。既然是这样的一个过程,我们决定尝试通过本地文件来模拟数据库记录。我们可以把数据从数据库里取出来,按照一定的规则,给它们命名为本地的一个个文件,然后在我们的测试框架中重载以前的去数据库取文本片段的方法为去本地的文件夹里取。这样的确是可行的,因为:
(1)我们的目的是验证我们的文档历史的保真度(Fidelity)的问题,那么我们的文档的文本片段是不会有所改变的。所以我们可以把它们放心转移到本地,而不用担心更新问题。
(2)文件放到本地,能减少传输上的消耗,并且如果把方法进行重载,是代价最小和最自然的一件事情,并且能最大限度地利用原来的代码。
(3)经过一些小小实验,我们发现经过很小的改动,我们可以把数据库的文件按照一定的规则改写到本地。这些都可以通过写一些小程序来实现。以后有新的文档,都可以用这个方法来实现,简单而易用。
3.1.3 输入和输出
在去除EJB和数据库的束缚的过程中,我们得到了我们的输入方式,那就是ASL+Text Pieces。输出文件当然很简单了,我们选择PDF,这个是我们主要的打印格式,当然,我们可以方便配置生成其它的格式文件,但是对于自动比较,由于我们现在的工具只支持PDF的比较,所以,对其它的格式文件输出,我们暂时不能提供自动比较。
3.2 框架方案
有了输入和输出,以及明确的需求,我们给出框架的解决方案:
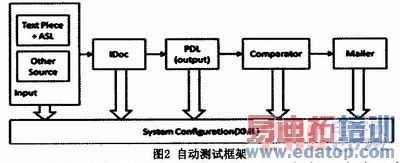
(1)把整个过程分为输入、过程中、输出、输出后。
(2)对于配置,采用XML,并且在XML里提供对输入、输出、以及中间的过程的配置。
(3)对于输入,我们定义一个接口,对于这个接口的实现将会是各个不同的输入方式,对于目前来说我们是支持ASL+Textpieces。但是我们以后会支持另外的输入方式。然后对于所有的输入接口,我们定义一个中心的中间输出,我们叫它IDoc。它实际上是输入和发布的中心,输入都要转成这个我们定义的中间结果,然后输出都需要从这个中间结果进行加工。
(4)对于输出,我们可以把它们同样配置在XML里面。并且对于最基本的输出例如PDF,我们可以把它作为默认的一个输出,而不需要每次进行配置。
(5)对于中间过程,我们配置了一些拦截器,这些拦截器以IDoc为中心,设置了publish前和publish后的拦截器,也就是说,在这里我们可以对publish前和publish后进行一些配置。比如,在开始前我们可以开始计时,结束后结束计时,这样我们可以测试一些效率方面的例子。
(6)对于输出,我们对于PDF输出,我们要实现它和自动比较工具的一个集成,也就是生成完PDF后,在配置要求进行比较的情况下,自动调用PDF比较工具对输出结果和标准进行比较,然后得出结果,并且生成HTML结果表格,然后通过Email给相关人员进行发送。
3.3 用例
当整个系统运行起来后,操作步骤如下:
首先,简单来说,我们会提供一些默认的XML配置,包括用例存放路径、输入方式、输出方式、发比较结果邮件会发给哪些人等等进行默认配置。因为这些东西会很少改动,当然改动的时候,我们重新配置就行。然后我们把需要运行的输入,即ASL+Text Pieces放到一个配置的路径里,然后用名字去区分不同的用例。然后我们通过XML配置我们的输入格式、输出格式,以及需不需要对结果进行比较、需不需要发邮件等等选项。当这些配置配完以后,我们给它起一个唯一的用例名,然后在程序里将这个用例名作为参数运行就能使整个过程自动完成。对于程序员,我们每次提交关键代码,都会先运行一下这个框架程序,然后查看自动生成的测试报告。如果发现问题,及时改正。而对于配置管理员来说,他们这个过程用ant工具配置在打包脚本中,然后我们就可以在每次打包时,自动地运行我们预先设置的用例。并且,生成文件后,程序会自动对生成的PDF文件进行比较,并将结果整理发出邮件。相关人员会通过Email收到比较结果,在上面可以通过超链接很方便地点选那些比较不对的文档,然后通知程序员进行改正。整个过程由于都是由机器在后台快速运行,少了人工的干扰,所以既提高了准确率,又提高了效率。
4 结论
由于文档发布系统的客户对于不同系统版本间文档一致性的高要求,使我们必须要提供一个长久的机制保证这个一致性。而要保证这个系统的一致性,我们提出了一个轻量级自动测试的方案。这里所说的轻量级,只是说该框架下运行方便,不需要受应用服务器和数据库的约束,但是理论它上提供了文档发布系统同样的功能和行为。实际上在整个过程中,我们尽量调用原先系统的程序,但是在解除对于服务器和数据库的依赖方面,我们通过仔细分析原来的动态文档发布系统各个模块的前提下,采用了用本地文件模拟数据库的方法,通过重载方法实现了对于数据库的解耦。该框架提供了强大的可配置功能,通过简单的XML设置,我们可以对整个过程进行配置,灵活实现不同的功能组合。
在未来,我们还会不断完善这个框架,例如会提供更多的输入选择,提供可视化的配置,提供尽量准确的诊断功能帮助程序员方便定位错误,并且根据动态文档发布系统的升级而相应提供更多的配置和功能。

