昨天在《学习LabVIEW(二)——操作.NET泛型类》给出的代码,实际上是有错误的。按照我们的设想,首先调用了Add,将Key-Value对“eleven”-11放入了Dictionary中,然后调用TryGetValue,查找Key: "eleven"对应的Value。所以查询必然应该是成功的。然而,反复执行昨天的代码,偶尔会出现查询失败的情况,如下图所示:
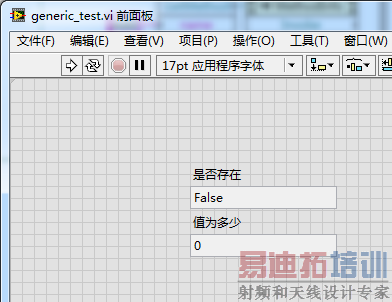
明明已经用Add添加了Key: "eleven",为什么有时候会查询失败呢?原因在于我们使用了错误的
观念编写
LabVIEW程序。
传统的计算机语言,本质上以指令的流动为核心编写代码,写出来的代码按照顺序被一条一条执行。但是像LabVIEW和Simulink这样的图形化编程语言,是以数据的流动为核心构造程序的。当程序以数据的流动为核心构造时,有时指令的执行先后顺序就不那么明显了,甚至在不知不觉中一些指令会自动的被并行化执行。关于这一点我曾经咨询过NI的客服,他们曾明确表示过,LabVIEW的运行时内部会自动利用多线程来处理可以并行执行的函数,无需用户的干预。这是一个非常好的特性,而且也是非常符合图形化编程这种以数据流动和核心的编程方式的特点的。
然而,当我们还是带着以前的以指令为核心编程的观念画LabVIEW程序时,就会不知不觉犯下错误。昨天写入和查询Dictionary的代码段如下图所示:
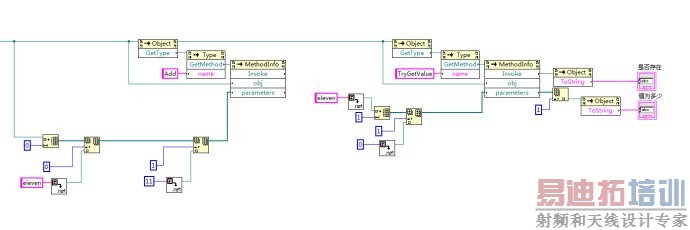
看起来,从左到右执行的话,似乎Add是先于TryGetValue的。这实际上是图形的绘制方式迷惑了我们。如果简单调整一下各个节点的位置,如下图所示:
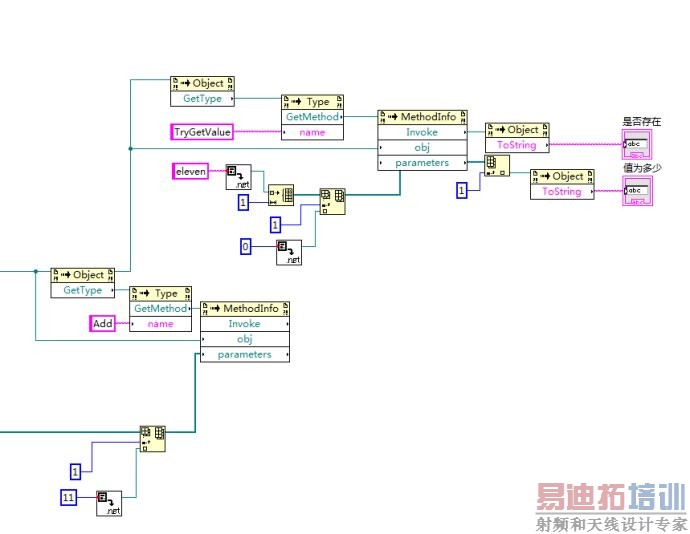
以数据流动为核心的LabVIEW就不一定会先执行哪一个函数了。如果先执行的是TryGetValue,就会出现查询失败的情况。
现在应该怎么解决这个问题呢?LabVIEW以数据流动为核心的编程思想,一方面使自动化的并行编程称为可能,另一方面,使“顺序执行”成了一种需要显示声明的结构;这与传统的语言是非常不同的,传统语言写代码,一行一行的码,一行一行的被执行,自然就是顺序结构。
我们在工具箱的编程这一栏中找到了用以表示顺序结构的工具:
用这个平铺式顺序结构将需要先于TryGetValue调用的部分框起来,如下图所示:
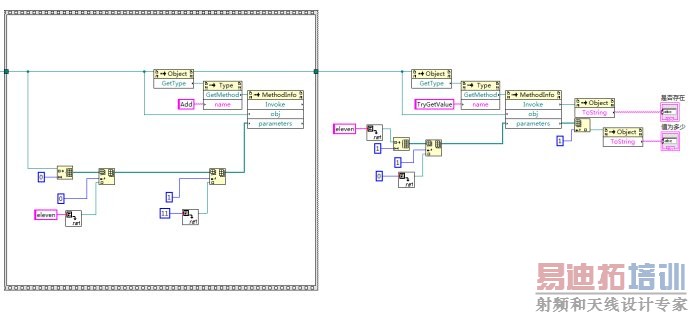
这样一来,只有框内所有的动作执行完成之后,数据才会继续往下流动,于是再也没有出现查询失败的情况了。

