- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
基于TMS320DM3730的H.264编码器移植与优化方法研
录入:edatop.com 点击:
摘要:提出了一种在TI公司高性能数字信号处理器TMS320DM3730上进行H.264编码器(即x264编码器)移植与优化的方法,详细描述了在CCS4.2开发平台上进行x264编码器移植工作的基本原理和需要注意的问题。为了提高编码速度,针对DM3730处理器的结构特点,对x264编码器进行了优化,主要方法包括编译器优化、内存优化、C语言代码优化及汇编代码优化。对x264编码器进行的CIF格式编码测试结果表明,在均值信噪比略微降低的前提下,编码速度得到了显著提高,因此获得了更优的编码效率。
关键词:TMS320DM3730;H.264标准;x264编码器;移植与优化
H.264/AVC是ISO/IEC和ITU-T联合推出的新一代的视频编码标准。其具有高压缩率、高图像质量、良好的网络亲和性等优点,被广泛的应用于各个视频相关产业中。在相同的图像质量的前提下,和传统的视频标准MPEG-4相比,H.264的码率只有MPEG-4的1/3。但是,H.2 64算法非常复杂,要实现实时编码是比较困难的。因此,如何将H.264编码器进行移植和优化,使其用于实际产品中成为了研究的热点。
DSP芯片技术的快速发展为实现嵌入式多媒体技术提供了可能。TMS320DM3730(简称DM3730)作为TI公司2010年推出的高性能芯片,以其ARM+DSP结构体系、运算速度快、众多多媒体接口等优点成为进行嵌入式系统开发首选平台之一。
常用的H.264编码器有JM编码器、x264编码器,T264编码器,x264编码器作为其中应用最广,效率最好的编码器,是进行嵌入式开发的首选H.264编码器。故本文在DM3730数字媒体处理器上进行x264编码器的移植与优化。本文首先介绍了DM3730的基本的结构和特点;然后结合DM3730的DSP,介绍了x264编码器的移植和优化;最后进行编码测试,结果表明编码器移植的正确性,编码速度得到了极大提高。
1 DM3730简单介绍
DM3730数字媒体处理器是美国德州仪器(TI)推出的一款高性能达芬奇(DaVinci)芯片,由1 GHz的ARM Coretex—A8和800 MHz的TMS320 C64x+DSP Core两部分组成,并集成了包括3D图像处理器,图像采集,USB2.0等模块。其整体结构如图1所示。
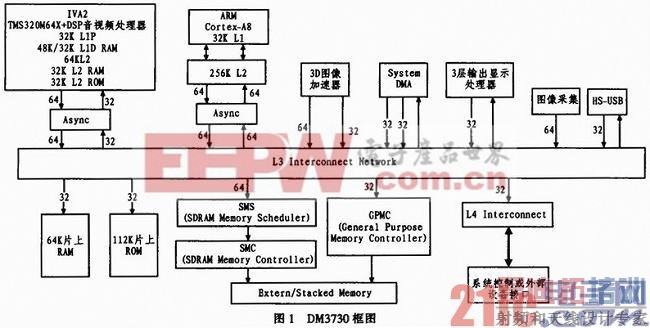
DM3730中ARM核作为主控制部分,负责整个芯片部分的设备的配置和控制、内存的分配、同外部接口的数据的交换;DSP核主要进行数据的处理和计算,其主频高达800MHz,采用VLIW(超长指令字)体系结构,包含8个独立的功能单元,每个功能单元在每个时钟周期执行一条指令,最高运算速度高达6 400 MMACS(百万乘法累加周期每秒)。同时拥有A、B两个通用寄存器组。每个都有32个32-bits寄存器组成,每个通用寄存器都可以存放数据、地址和指针。
2 x264的移植
CCS(Code Composer Stdio)是TI公司提供的用于C语言开发的开发平台,该平台可以使用C语言进行DSP程序的开发。本文基于CCS4.2平台进行x264编码器的移植,具体流程如图2所示。
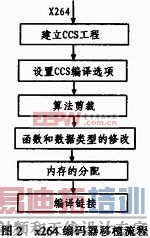
[p]
2.1 CCS工程的建立
在CCS环境下分别建立两个工程:静态库工程Libx264.pjt和可执行工程x264.pjt。静态库工程Libx264.pjt包含x.264编码所需要的绝大部分的函数,编译链接生成可进行调用的Libx264.lib文件。可执行工程x264.pjit工程是x264编码程序的主体的框架,包括编码参数的初始化、文件的输入输出以及图像的编码循环等主函数实现部分。该工程添加对Libx264.lib文件的引用,最终编译链接生成x264.out可执行文件。
2.2 CCS中编译选项的设置
在CCS4.2平台下必须对Libx264.pjt和x264.pjt工程设置合适编译选项:
1)DM3730的DSP核为C64x+版本,故目标处理器版本选项选择为-mv64004+
2)编译器默认的内存模式为Near模式,而在Near模式下要求.BSS段必须小于32 kB,.BSS段存取的是工程中的全局变量和静态变量,x264工程中的全局变量和静态变量已经远大于32 kB,故将Data access model和Const access model设置为Far。
3)在DM3730中使用的是小端模式的字节存储即低位字节先存储,故在CCS4.2中Device Endianess(设备字节存储次序)设置为little-endian。
2.3 算法的剪裁
1)MMX、SSE汇编指令的去除
在x264中有很多计算量大的函数例如DCT变换、运动估计、量化等都是使用MMX、SSE汇编指令进行实现的,但是这些汇编都是针对X86平台、AMD平台,在DSP的结构下不能用,需要删除这些汇编实现文件,并将宏定义_HAVE_MMX_进行删除。
2)精简代码
考虑到x264的编码的效率,采用了H.264中的baseline级别进行编码,去除了CABAC(基于内容的自适应二进制编码)和B帧(双向预测帧)这两个特性。这样虽然一定程度上增加了编码的码率,但是对编码速度的提高很明显。编码采用固定量化参数,不使用码率控制,保留所有帧内预测模式和帧间预测分块模式进行编码,同时去除x264的多余的打印信息和help信息以提高编码速度。
2. 4 函数、数据类型的修改
在编译过程中函数名为isfinite的函数会出现重定义的错误,原因是在CCS4.2包含的头文件中对该函数名有定义的,而x264中也有对其的定义,只需要将函数名进行修改一些即可。
同时由于硬件平台的差异,C语言中有些数据类型对应的字节长也会有差异的,为了让程序更好的兼容硬件平台,x264程序使用了通用的数据类型定义。通用数据类型一般在stdint.h中定义,VC++中并没有提供通用数据类型,而CCS中则提供了stdint.h,同时它包含于intty pe.h中,故移植到CCS中时应该包含#includeinttype.h>。
2.5 内存的分配
x264程序中存在很多使用malloc进行动态的内存分配,这样会大大提高占用堆栈的大小,应该尽量的将动态内存分配使用静态的数组进行替代。同时在嵌入式系统中,合理的分配堆栈的大小对一个程序也是相当重要的。由于x264中动态内存的申请、静态的表格数组和全局变量比较多,故在cmd文件中对堆栈的大小定义设为:
-stack 0x8000
-heap 0x400000
同时将x264程序中的代码和数据的段地址全部放置到外部寄存器中。
3 x264编码器的优化
x264成功移植后在DM3730上进行CIF(通用影像传输格式)格式图像编码测试,平均编码速度只有1fps(帧每秒)左右,离实时编码差距很大,需要对x264编码器进行优化工作。优化的方法包括编译器优化、内存优化、C语言优化和汇编优化。
3.1 编译器优化
在使用C编译器连接和生成最终DSP可执行代码时,CCS上的C编译器拥有非常出色的优化性能,可以通过设置编译优化选项进行编译器的自我优化。表1所示是CCS4.2中一些优化选项及其功能列表。

通过对程序速度性能的要求和代码结构的考虑,最终选择的编译选项为:-mv6400+ -pm -o3 -op3 -mf3 -mt。
3.2 内存优化
DSP的内部存储器和外部存储器由于总线频率的限制所以存在较大的读取速度差异,DM3730中片上内存的访问频率为300 MHZ,而对SDRAM的访问频率最高为133 MHZ,若利用静态地址分配将一些使用频繁而比较大的结构体或数组指定到片上内存中,那样程序的运行速度将会得到很大的提高。故可以将一些使用频繁的动态内存分配改为静态内存分配,然后将静态分配的常用的数据结构比如帧存储区利用DATA_SECTION指定段地址,通过.cmd文件将指定的段放置到片上内存中。
3.3 C语富代码的优化
1)使用内联函数
CCS的C6000编译器提供了一些经过汇编优化的C内联函数,可以使用这些内联函数替换x264中的相应函数,提高程序的运行速度。在x264中使用的内联函数有:_abs()、_amem4()、_amem4_const()、_pack2()、_paek14()、_min2()、_max2()、_dotpu4()等。
2)使用数据对齐指令DATA_ALIGN
数据对齐指令的完整的语法是:
#pragma DATA_ALIGN(symbol,constant)[p]
该指令的作用是将对象symbol排列到constant指定的列边界上以方便读取。例如DM3730是支持对非对齐双字的一次性读取,但是如果内存地址对齐,同一个时钟周期内可以同时进行两组双字的读取,而如果不对齐则只能读取一组。因此在定义数组时使用DATA_ALIGN指令,可以大大减少数据读取时内存地址不对齐的情况,增加程序的并行性。
3)使用最小循环次数指令MUST_ITERATE
最小循环次数指令的完整语法是:
#pragma MUST_ITERATE(min,max,multiple)
其中min和max分别代表了循环的最小和最大迭代次数,multiple表明了循环次数是其倍数。使用最小循环次数程序指令可以通过通知编译器至少进行多少次循环,那样编译器可以将min次循环进行展开进行软件流水,进行循环之间并行处理,提高程序运行速度。
3.4 汇编代码的优化
C语言编译器通常只能完成大部分的工作,这个阶段的C语言代码在DSP端运行的效率并不是很高,为了进一步改善性能,对那些算法简单但计算量大且使用很频繁的函数使用汇编语言进行编写实现,可以大大提高程序运行速度。例如快速DCT变换、SAD、量化等算法过程可以考虑用汇编语言来编写。
线性汇编是TI公司简化C6000系列DSP的汇编语言而开发设计的,介于高级语言和机器语言之间。线性汇编语言的指令系统和普通的汇编语言的指令系统基本相同。在编写线性汇编语言的时候是不需要考虑到指令的延时、寄存器的使用和功能单元的分配,C6000编译器提供了汇编优化器进行汇编优化,会综合指令的延时、寄存器的使用和功能单元的分配进行优化,让线性汇编语言尽量的进行软件流水和指令的并行处理,提高汇编的运行速度。DM3730的DSP核为C64x+系列,线性汇编在上面是可以完美运行的。
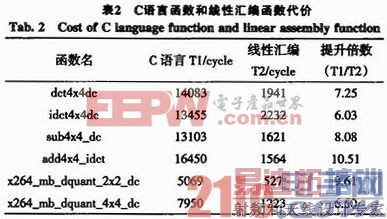
表2所示为使用CCS中的profile工具测量的一些函数的C语言函数和线性汇编函数在DM3730上运行时钟周期对比。
4 实验结果分析
x264编码器移植成功后,使用标准CIF格式视频序列对移植和优化后的x264编码器在DM3730上进行测试,测试结果如下表3所示。
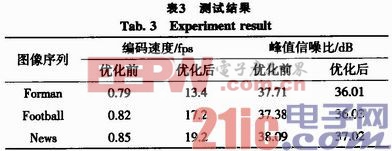
从表3可以看出,x264程序经过优化后,峰值信噪比有略微的下降,但该下降不影响整体视频效果,而编码速度得到了大大的提高。
5 结束语
文中基于DM3730平台,描述了进行x264编码器移植应该注意的主要问题,然后通过编译选项优化、内存优化、C语言代码的优化和汇编代码的优化等优化方法对x264编码器进行了优化。最后视频编码测试表明,优化的效果显著,且均值信噪比下降不多。

