- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
PC北桥端高速采集存储系统研究
录入:edatop.com 点击:
电子科技大学自动化工程学院 李京桓 黄建国 王志刚
引言
由于现在的PCI、CPCI、VME等系统的持续传输速度很难超越400MB/s,因此要完成实时、长时间的采集存储功能,本设计选择实现一种基于PCI-E的系统,PCI-E是第三代接口通信协议(3GPIO)。传统的PC主机北桥只有一个高速的PCI-E X16接口,本文使用带G31北桥的芯片组的技嘉主板GA-G31M-ES2C为例来进行讨论,虽然G31-ICH7芯片组在南桥上可提供4个PCI-E ×1接口,但是由于其他I/O端口资源的占用,该主板在北桥上仅提供了一个PCI-E ×16的插槽,南桥也只提供一个PCI-E ×1插槽。因此如果只采用G31/ICH7芯片组的电脑建立一个PCI-E采集存储系统,它只能实现PCI-E 1.0 单通道的采集存储系统,带宽就被限制在200MB/s内。而这种格局主要是由于计算机北桥只提供一个PCI-E插槽,不能同时满足高速采集和存储的连接需要,因此扩展主机北桥上的PCI-E接口,将整个采集存储都建立在北桥上变得至关重要。
系统结构分析
Intel(英特尔)公司最新的双通道DDR3内存以及下一代双×16 PCI-E 2.0的计算机芯片组技术提供了一种更新的个人电脑的架构,这些技术被应用到X38、X48和X58等计算机芯片组中。本文以X58为例,图1为X58芯片组的系统架构。
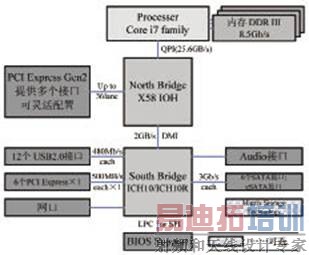
图1 X58芯片组的系统架构
X58芯片组搭配新南桥ICH10或ICH10R,可支持四条PCI-E ×16插槽(其中两条符合PCI-E 2.0规范),根据通道数的要求可组成四种不同模式,当然它只支持双图形处理器(GPU)协同运行的技术CrossFire,仍不支持Scalable Link Interface(SLI)技术。SLI技术是主板能够同时使用两块同型号PCI-E显卡的一种技术,同时芯片间通信通过类似AMD HyperTransport总线技术的QPI总线技术完成,借助PCI-E通道可带来最高25.6GB/s的双向带宽,而现在的前端总线Front Side Bus(FSB)则被彻底弃用。我们可以直接运用X58芯片组构建一个高速实时的系统,但由于现阶段很少有能够完全利用PCI-E ×16带宽的采集卡,因此将资源进行分割,利用多块采集模块组成一个采集系统,通过PCI-E Switch扩展接口的方法可以将X58芯片组扩展成为一个更高速、兼容更多模块的采集存储系统。
DMI(Direct Media Interface)直接媒体接口是Intel公司开发用于连接主板南北桥的总线,取代了以前的Hub-Link总线。DMI采用点对点的连接方式,时钟频率为100MHz,由于它基于PCI-E总线,因此具有PCI-E总线的优势。DMI实现了上行与下行各1GB/s的数据传输率,总带宽达到2GB/s,但DMI还要与其他I/O设备进行通信,因此如果选择南桥的PCI-E端口进行传输,传输速度将受到很大的限制,理想情况下至多只能实现1GB/s的传输存储速度。因此,本系统在计算机中DMI以上的结构中完成数据的传输和存储。我们可以将连接在芯片G31 GMCH的PCI-E ×16端口通过一个PCI-E Switch进行扩展,扩展后的结构相当于主机北桥提供了多个高速的PCI-E接口,形成一个类似于图1中的X58架构,从而使整个传输存储过程不受DMI双向2GB/s速度的影响。
利用北桥PCI-E扩展技术,将所有的采集卡和存储卡都连接到主机的北桥端,可使整个数据传输不受主机DMI等的速度瓶颈限制,如果只是使用PCI-E ×4对系统进行扩展,理想的有效数据传输速度也可达800MB/s,而且由于PCI-E协议是双向同时传输的,因此将采集卡和存储卡同时连接到一个端口并不会影响其传输和存储的效率。
系统设计
PCI-E Switch
PCI-E Switch为整个系统提供扩展端口,系统中所有的PCI-E接口都是通过PCI-E Switch芯片扩展出来的,类似的可以看成将多个PCI-E插槽直接连接到主机的北桥上。图2为含PCI-E的拓扑结构图,通过Switch可以将一个上游设备口扩展多个下游端口,此外PCI-E Switch还可以级联。通过一个多通道的PCI-E Switch可扩展构建一个多采集卡多存储设备的实时高速采集存储系统。
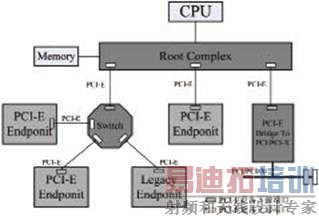
图2 含PCI-E Switch的拓扑结构图
本方案采用的是PLX公司的一块PCI-E Switch芯片PEX8616,它是一款可以设置4个接口并拥有16个通道的PCI-E Switch芯片,并可设置每个接口的通道数。其支持透明桥(TB)、非透明桥(NTB)两种方式,即可以支持两个及以上的多主机系统和多智能I/O端口的模块。PEX8616每个通道含有两个虚拟端口,且支持热插拔。由于主要目的是将北桥上的PCI-E ×16插槽扩展成为多个PCI-E接口。因此,本系统中将其分为四个PCI-E ×4的接口。端口号为0、1、5和6,将与主机连接的端口0设置为上游端口,其余三个端口则为下游端口,连接采集卡和RAID存储卡。
PCI-E数据传输方式包含地址路由和ID路由等方式,PCI-E设备在系统中都有一个ID,根据所处的PCI总线号、设备号和功能号来确定。一个PCI-E Switch可以看成多个P2P桥的集合,并且在上游设备和下游设备之前还虚拟了一条总线。
系统与桥
透明桥系统是指整个系统中只含一个主机设备,其余所有设备都是以端点设备的形式出现。所有下游设备不能自发进行数据传输,只有在上位机引导下进行数据传输。采集卡可以通过DMA等方式将数据传输到上位机的内存中的某个区域,然后再将内存中的数据存储到磁盘阵列中。由于存储和读取同一块内存,因此在软件上可以多开辟几块内存,利用多线程规避系统顺序执行所带来的延迟,提高传输和存储的速度。
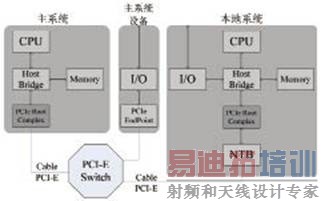
图3 基于PCI-E Switch的非透明桥系统
PEX8616提供非透明桥,非透明端口保持处理器的电气及逻辑隔离,可以防止主机列举端口后面的设备,从而隔离其后的处理器及内存空间。非透明端口允许打开窗口以交换数据,通过地址转换,数据从端口的一侧中传输另外一侧。每个处理器把非透明端口的另一端当作一个下游设备,并把它映射到自己的地址空间。利用非透明端口的地址翻译能力,处理器之间可以通过PCI-E总线进行通信。因此系统构建可以考虑引入非透明桥,在上位机存在的情况下,让采集卡或者存储卡也作为一个主机端,数据在采集存储过程中可以直接绕开PC主机进行,当数据进行反演时,上位机再作为上游,对磁盘阵列进行操作和控制。
图3为一种非透明桥的系统,其中包含两个Host Bridge和PCI-E Root Complex,其中本地设备系统中的Root Complex连接到PCI-E Switch的一个NT端口上,从而在主系统的PCI结构中把它作为一个下游设备。PCI-E Switch连接两个独立的处理器域,本地设备的资源和地址对主系统是不可见的。允许本地处理器独立地配置和控制其子系统。主系统和本地系统的时钟完全独立。主系统和本地系统的地址完全独立,在主系统和本地系统之间可以进行地址翻译。增加了隔离主系统、本地系统总线之间地址域的功能。
在构建采集存储系统的过程中可以将采集模块或者存储模块以构建本地系统的方式实现,从而可以在采集数据后直接对数据进行预处理然后再送到PCI-E总线进行存储或者可以在存储之后直接在本地系统进行回放或者提供网口访问存储数据等功能。
采集存储系统的实现
系统结构
系统由PC主机、PCI-E Switch背板、采集卡和RAID存储卡组成。在完成背板设计后,先利用一块PEX8311接口芯片的采集卡,Rocket RAID 2680磁盘阵列卡,实现一种高速采集存储的系统。然而因为普通的PC机箱的空间有限,如果将PCI-E Switch背板与上位机的接口直接以PCI-E金手指的形式,则当背板接入主机后,很难创造一个空间可以容纳其他板卡插到背板上。并且由于磁盘阵列是由多个Western Digest WD3200AAJS的硬盘构成,发热量也成为一个很显著的问题。
因此本方案考虑通过引入Cable PCI-E来改善系统。Cable PCI-E是基于PCI-E用于服务器、台式机和笔记本的下一代外围总线,它具有以下的优点:
• 成本较低,由于PCI-E广泛用于各种主机;
• 高带宽,Gen1 ×4 Cable的带宽即达到1GB/s;
• 低延迟,300ns~700ns;
• 兼容性强,系统软件上完全兼容PCI模式;
• Cable PCI-E至少由15种标准形成;
• 唯一可以同时应用于Chip-to-Chip、board-to-board和box-to-box的标准。
PCI-SIG标准组织将Cable PCI-E定义为一种基于PCI-E的基本规范的扩展,通过线缆化将PCI-E协议扩展到box-to-box应用和实现长距离的传输是产生Cable PCI-E标准的目的。Cable PCI-E提供一种简单而且具有高性能的总线,方便扩展PC以及测试I/O等设备。本方案就是利用Cable PCI-E方便扩展设备的特点,将整个采集存储系统完全分离到PC机箱外,最终可以独立构建成一个机箱形成一种box-to-box的模式,使得整个系统的可扩展性很强,PCI-E ×4及其以下的COST采集板卡和存储卡均可以很好的应用于本系统中。独立的机箱也为磁盘阵列中的硬盘提供足够的空间,系统的散热也能得到很好的保障。
系统的结构图如图4所示,整个系统围绕PCI-E Switch构建而成,通过两个Cable PCI-E将系统的各个模块独立开来。由于采集卡采用的为PEX8311,故采集卡与PCI-E Switch连接的通道数为1,在后续的研究中可以升级采集的采集和接口速度从而实现整个系统的升级。磁盘阵列卡是一款消费类产品,Rocket RAID 2680不能提供HOST功能,因此本案构建的是一个透明桥系统。
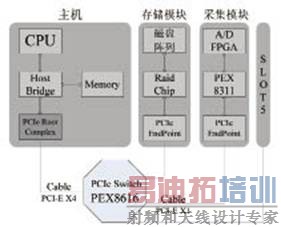
图4 PCI-E Switch采集存储系统结构图
数据的采集、传输和存储
数据采集
采集板AD采用TI ADS6145芯片,采样位数为14bit,最高采样频率为125Mbps。AD采集后的数据接入到Xilinx公司Spartan-3ADSP系列的FPGA芯片XC3SD3400A。因为PEX8311接口芯片可支持8位、16位、32位数据的传输,为了提高数据传输的效率,同时也为了使得数据采集速率获得相对提升。本设计中PEX8311中采用32位数据传输。所以在本方案FPGA数据流逻辑控制中,不仅要完成数据的缓存以及数据传输逻辑的控制,还要进行数据位的变换扩展,由14位数据扩展为32位数据。
数据传输和存储
数据传输是指的从PEX8311到主机内存的过程。本方案选择DMA方式进行,由于PEX8311内建两个DMA通道。本方案使用其中的一个,DMA通道0。在安装PLX提供的SDK以及驱动后,可以通过其提供的API开发包中的函数对PEX8311和PEX8616进行控制和访问。一般的DMA传输过程是无需CPU的参与的,但是含Burst的DMA操作还是要通过CPU的参与的,与单独的一次读写操作相比,Burst只需要提供一个起始地址就行了,以后的地址依次加1,而非Burst操作每次都要给出地址,以及需要中间的一些应答、等待状态等等。如果是对地址连续的读取,Burst效率高得多,但如果地址是跳跃的,则无法采用Burst操作。PEX8311的DMA传输支持Single Burst 、Burst-4LW和Infinite Burst三种突发方式,表1为三种突发方式在不同单次传输字节数的情况下的传输速度对比。
表1 DMA传输在三种突发方式下的速度对比(MB/s)
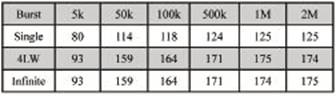
由表1数据可观察出,采用后两种突发方式进行DMA传输时,速度较普通DMA传输方式有明显的提高,因此本方案采用Infinite Burst突发方式进行DMA传输,使用连续的地址,以提高DMA传输的速度。
PLX公司SDK中提供的函数可对PEX8311和PEX8616进行一系列控制和操作,DMA通道的参数设置在打开DMA通道的时候一并完成,通过设置函数PlxPci_DeviceOpen()中的PLX_DMA_PROP结构体可以设置DMA传输的突发方式、本地总线带宽和传输方向等参数。在系统初始化过程中设置以上参数。当整个采集存储过程完成时,则需要进行对整个工程的关闭工作,同样是通过SDK中的函数PlxPci_DeviceClose()来关闭DMA通道。然后释放开辟的所有内存块空间,并将指针赋NULL值。系统连续存储的整个过程从开始到结束,虽然进行了很多个DMA传输的操作,但是只进行了一次DMA通道的打开和关闭,从而尽可能低的减小由于这部分时间带来的速度影响。软件流程如图5所示。
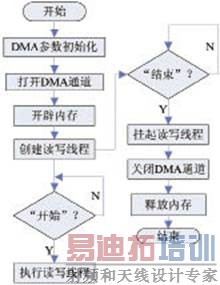
图5 采集存储系统软件流程图
根据图5可以观察到系统引入了多线程技术,多线程技术的实现是通过分别创建两个函数,一个控制DMA控制器进行连续的数据传输,另一个用于将内存中的数据快速的存储到磁盘阵列中,然后创建成为两个线程。当准备开始进行数据传输的时候,首先是设置DMA传输的参数并打开DMA通道。在此过程中还需要申请多块内存空间进行缓存数据,由于使用多线程技术,因此一块内存空间不能同时供两个函数同时读写,因此创建多个内存块,然后将两个线程同时打开,对开辟的多个内存块依次进行读写操作,但是由于整个过程只包含一个极短的时间延迟,因此完全可以将整个读写内存的过程近似的看成一个同时进行读写操作,因此达到提高存储的速度的目的。
传输速度分析
RAID 0又称为Stripe或Striping,它代表了所有RAID级别中最高的存储性能。RAID 0提高存储性能的原理是把连续的数据分散到多个磁盘上存取,这样,系统有数据请求就可以被多个磁盘并行的执行,每个磁盘执行属于它自己的那部分数据请求。这种数据上的并行操作可以充分利用总线的带宽,显著提高磁盘整体存取性能。
表2 RAID0方式下读写阵列速度比较(MB/s)
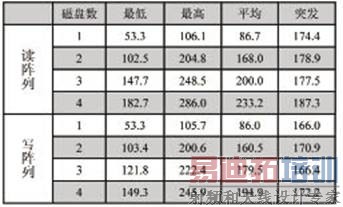
该系统在实际的采集存储过程中,连续存储的速度在135MB/s,因此用两块或者三块磁盘组成的RAID 0阵列就能完全满足设计要求。因为存储的速度仍明显高于采集卡DMA传输的速度,而且可以通过扩展RAID卡上的硬盘数进一步增加磁盘阵列存储速度。表2的实验数据使用四个Western Digest WD3200AAJS硬盘,因为使用同样大小或者规格的硬盘能够更好的使用所用的磁盘空间。由表中的数据可以看出,随着磁盘数目的增加,其存储的各项指标均有明显的提高,该磁盘阵列卡Rocket RAID 2680最多可提供8块SATA硬盘,随着采集卡采集传输的速度的提升,可以用更多的磁盘组建磁盘阵列,来匹配前端采集卡的带宽,所以整个系统只需更换一个更高速的PCI-E采集卡就可以实现更高存储速度的高速采集存储系统。

图6 高速采集存储系统照片
结论
设计一个基于PC主机北桥的长时间不间断高速采集和存储的系统。利用PC北桥PCI-E扩展技术,将采集卡和存储都连接到计算机北桥,此法可以用于后续通道进一步扩大的应用中。本文最后介绍了利用PC主机、PCI-E接口芯片PEX8311、Switch芯片PEX8616和RAID磁盘阵列卡,构建一个PCI-E架构的实时海量存储系统的案例。数据通过PC机的北桥芯片,实现采集卡到磁盘阵列存储卡的数据高速传输。虽然在采集卡采用PCI-E X1的情况下并不能完全体现将整个系统都集中在主机北桥的优势,但是它将会在更进一步的设计和研究中体现出来。
引言
由于现在的PCI、CPCI、VME等系统的持续传输速度很难超越400MB/s,因此要完成实时、长时间的采集存储功能,本设计选择实现一种基于PCI-E的系统,PCI-E是第三代接口通信协议(3GPIO)。传统的PC主机北桥只有一个高速的PCI-E X16接口,本文使用带G31北桥的芯片组的技嘉主板GA-G31M-ES2C为例来进行讨论,虽然G31-ICH7芯片组在南桥上可提供4个PCI-E ×1接口,但是由于其他I/O端口资源的占用,该主板在北桥上仅提供了一个PCI-E ×16的插槽,南桥也只提供一个PCI-E ×1插槽。因此如果只采用G31/ICH7芯片组的电脑建立一个PCI-E采集存储系统,它只能实现PCI-E 1.0 单通道的采集存储系统,带宽就被限制在200MB/s内。而这种格局主要是由于计算机北桥只提供一个PCI-E插槽,不能同时满足高速采集和存储的连接需要,因此扩展主机北桥上的PCI-E接口,将整个采集存储都建立在北桥上变得至关重要。
系统结构分析
Intel(英特尔)公司最新的双通道DDR3内存以及下一代双×16 PCI-E 2.0的计算机芯片组技术提供了一种更新的个人电脑的架构,这些技术被应用到X38、X48和X58等计算机芯片组中。本文以X58为例,图1为X58芯片组的系统架构。
图1 X58芯片组的系统架构
X58芯片组搭配新南桥ICH10或ICH10R,可支持四条PCI-E ×16插槽(其中两条符合PCI-E 2.0规范),根据通道数的要求可组成四种不同模式,当然它只支持双图形处理器(GPU)协同运行的技术CrossFire,仍不支持Scalable Link Interface(SLI)技术。SLI技术是主板能够同时使用两块同型号PCI-E显卡的一种技术,同时芯片间通信通过类似AMD HyperTransport总线技术的QPI总线技术完成,借助PCI-E通道可带来最高25.6GB/s的双向带宽,而现在的前端总线Front Side Bus(FSB)则被彻底弃用。我们可以直接运用X58芯片组构建一个高速实时的系统,但由于现阶段很少有能够完全利用PCI-E ×16带宽的采集卡,因此将资源进行分割,利用多块采集模块组成一个采集系统,通过PCI-E Switch扩展接口的方法可以将X58芯片组扩展成为一个更高速、兼容更多模块的采集存储系统。
DMI(Direct Media Interface)直接媒体接口是Intel公司开发用于连接主板南北桥的总线,取代了以前的Hub-Link总线。DMI采用点对点的连接方式,时钟频率为100MHz,由于它基于PCI-E总线,因此具有PCI-E总线的优势。DMI实现了上行与下行各1GB/s的数据传输率,总带宽达到2GB/s,但DMI还要与其他I/O设备进行通信,因此如果选择南桥的PCI-E端口进行传输,传输速度将受到很大的限制,理想情况下至多只能实现1GB/s的传输存储速度。因此,本系统在计算机中DMI以上的结构中完成数据的传输和存储。我们可以将连接在芯片G31 GMCH的PCI-E ×16端口通过一个PCI-E Switch进行扩展,扩展后的结构相当于主机北桥提供了多个高速的PCI-E接口,形成一个类似于图1中的X58架构,从而使整个传输存储过程不受DMI双向2GB/s速度的影响。
利用北桥PCI-E扩展技术,将所有的采集卡和存储卡都连接到主机的北桥端,可使整个数据传输不受主机DMI等的速度瓶颈限制,如果只是使用PCI-E ×4对系统进行扩展,理想的有效数据传输速度也可达800MB/s,而且由于PCI-E协议是双向同时传输的,因此将采集卡和存储卡同时连接到一个端口并不会影响其传输和存储的效率。
系统设计
PCI-E Switch
PCI-E Switch为整个系统提供扩展端口,系统中所有的PCI-E接口都是通过PCI-E Switch芯片扩展出来的,类似的可以看成将多个PCI-E插槽直接连接到主机的北桥上。图2为含PCI-E的拓扑结构图,通过Switch可以将一个上游设备口扩展多个下游端口,此外PCI-E Switch还可以级联。通过一个多通道的PCI-E Switch可扩展构建一个多采集卡多存储设备的实时高速采集存储系统。
图2 含PCI-E Switch的拓扑结构图
本方案采用的是PLX公司的一块PCI-E Switch芯片PEX8616,它是一款可以设置4个接口并拥有16个通道的PCI-E Switch芯片,并可设置每个接口的通道数。其支持透明桥(TB)、非透明桥(NTB)两种方式,即可以支持两个及以上的多主机系统和多智能I/O端口的模块。PEX8616每个通道含有两个虚拟端口,且支持热插拔。由于主要目的是将北桥上的PCI-E ×16插槽扩展成为多个PCI-E接口。因此,本系统中将其分为四个PCI-E ×4的接口。端口号为0、1、5和6,将与主机连接的端口0设置为上游端口,其余三个端口则为下游端口,连接采集卡和RAID存储卡。
PCI-E数据传输方式包含地址路由和ID路由等方式,PCI-E设备在系统中都有一个ID,根据所处的PCI总线号、设备号和功能号来确定。一个PCI-E Switch可以看成多个P2P桥的集合,并且在上游设备和下游设备之前还虚拟了一条总线。
系统与桥
透明桥系统是指整个系统中只含一个主机设备,其余所有设备都是以端点设备的形式出现。所有下游设备不能自发进行数据传输,只有在上位机引导下进行数据传输。采集卡可以通过DMA等方式将数据传输到上位机的内存中的某个区域,然后再将内存中的数据存储到磁盘阵列中。由于存储和读取同一块内存,因此在软件上可以多开辟几块内存,利用多线程规避系统顺序执行所带来的延迟,提高传输和存储的速度。
图3 基于PCI-E Switch的非透明桥系统
PEX8616提供非透明桥,非透明端口保持处理器的电气及逻辑隔离,可以防止主机列举端口后面的设备,从而隔离其后的处理器及内存空间。非透明端口允许打开窗口以交换数据,通过地址转换,数据从端口的一侧中传输另外一侧。每个处理器把非透明端口的另一端当作一个下游设备,并把它映射到自己的地址空间。利用非透明端口的地址翻译能力,处理器之间可以通过PCI-E总线进行通信。因此系统构建可以考虑引入非透明桥,在上位机存在的情况下,让采集卡或者存储卡也作为一个主机端,数据在采集存储过程中可以直接绕开PC主机进行,当数据进行反演时,上位机再作为上游,对磁盘阵列进行操作和控制。
图3为一种非透明桥的系统,其中包含两个Host Bridge和PCI-E Root Complex,其中本地设备系统中的Root Complex连接到PCI-E Switch的一个NT端口上,从而在主系统的PCI结构中把它作为一个下游设备。PCI-E Switch连接两个独立的处理器域,本地设备的资源和地址对主系统是不可见的。允许本地处理器独立地配置和控制其子系统。主系统和本地系统的时钟完全独立。主系统和本地系统的地址完全独立,在主系统和本地系统之间可以进行地址翻译。增加了隔离主系统、本地系统总线之间地址域的功能。
在构建采集存储系统的过程中可以将采集模块或者存储模块以构建本地系统的方式实现,从而可以在采集数据后直接对数据进行预处理然后再送到PCI-E总线进行存储或者可以在存储之后直接在本地系统进行回放或者提供网口访问存储数据等功能。
采集存储系统的实现
系统结构
系统由PC主机、PCI-E Switch背板、采集卡和RAID存储卡组成。在完成背板设计后,先利用一块PEX8311接口芯片的采集卡,Rocket RAID 2680磁盘阵列卡,实现一种高速采集存储的系统。然而因为普通的PC机箱的空间有限,如果将PCI-E Switch背板与上位机的接口直接以PCI-E金手指的形式,则当背板接入主机后,很难创造一个空间可以容纳其他板卡插到背板上。并且由于磁盘阵列是由多个Western Digest WD3200AAJS的硬盘构成,发热量也成为一个很显著的问题。
因此本方案考虑通过引入Cable PCI-E来改善系统。Cable PCI-E是基于PCI-E用于服务器、台式机和笔记本的下一代外围总线,它具有以下的优点:
• 成本较低,由于PCI-E广泛用于各种主机;
• 高带宽,Gen1 ×4 Cable的带宽即达到1GB/s;
• 低延迟,300ns~700ns;
• 兼容性强,系统软件上完全兼容PCI模式;
• Cable PCI-E至少由15种标准形成;
• 唯一可以同时应用于Chip-to-Chip、board-to-board和box-to-box的标准。
PCI-SIG标准组织将Cable PCI-E定义为一种基于PCI-E的基本规范的扩展,通过线缆化将PCI-E协议扩展到box-to-box应用和实现长距离的传输是产生Cable PCI-E标准的目的。Cable PCI-E提供一种简单而且具有高性能的总线,方便扩展PC以及测试I/O等设备。本方案就是利用Cable PCI-E方便扩展设备的特点,将整个采集存储系统完全分离到PC机箱外,最终可以独立构建成一个机箱形成一种box-to-box的模式,使得整个系统的可扩展性很强,PCI-E ×4及其以下的COST采集板卡和存储卡均可以很好的应用于本系统中。独立的机箱也为磁盘阵列中的硬盘提供足够的空间,系统的散热也能得到很好的保障。
系统的结构图如图4所示,整个系统围绕PCI-E Switch构建而成,通过两个Cable PCI-E将系统的各个模块独立开来。由于采集卡采用的为PEX8311,故采集卡与PCI-E Switch连接的通道数为1,在后续的研究中可以升级采集的采集和接口速度从而实现整个系统的升级。磁盘阵列卡是一款消费类产品,Rocket RAID 2680不能提供HOST功能,因此本案构建的是一个透明桥系统。
图4 PCI-E Switch采集存储系统结构图
数据的采集、传输和存储
数据采集
采集板AD采用TI ADS6145芯片,采样位数为14bit,最高采样频率为125Mbps。AD采集后的数据接入到Xilinx公司Spartan-3ADSP系列的FPGA芯片XC3SD3400A。因为PEX8311接口芯片可支持8位、16位、32位数据的传输,为了提高数据传输的效率,同时也为了使得数据采集速率获得相对提升。本设计中PEX8311中采用32位数据传输。所以在本方案FPGA数据流逻辑控制中,不仅要完成数据的缓存以及数据传输逻辑的控制,还要进行数据位的变换扩展,由14位数据扩展为32位数据。
数据传输和存储
数据传输是指的从PEX8311到主机内存的过程。本方案选择DMA方式进行,由于PEX8311内建两个DMA通道。本方案使用其中的一个,DMA通道0。在安装PLX提供的SDK以及驱动后,可以通过其提供的API开发包中的函数对PEX8311和PEX8616进行控制和访问。一般的DMA传输过程是无需CPU的参与的,但是含Burst的DMA操作还是要通过CPU的参与的,与单独的一次读写操作相比,Burst只需要提供一个起始地址就行了,以后的地址依次加1,而非Burst操作每次都要给出地址,以及需要中间的一些应答、等待状态等等。如果是对地址连续的读取,Burst效率高得多,但如果地址是跳跃的,则无法采用Burst操作。PEX8311的DMA传输支持Single Burst 、Burst-4LW和Infinite Burst三种突发方式,表1为三种突发方式在不同单次传输字节数的情况下的传输速度对比。
表1 DMA传输在三种突发方式下的速度对比(MB/s)
由表1数据可观察出,采用后两种突发方式进行DMA传输时,速度较普通DMA传输方式有明显的提高,因此本方案采用Infinite Burst突发方式进行DMA传输,使用连续的地址,以提高DMA传输的速度。
PLX公司SDK中提供的函数可对PEX8311和PEX8616进行一系列控制和操作,DMA通道的参数设置在打开DMA通道的时候一并完成,通过设置函数PlxPci_DeviceOpen()中的PLX_DMA_PROP结构体可以设置DMA传输的突发方式、本地总线带宽和传输方向等参数。在系统初始化过程中设置以上参数。当整个采集存储过程完成时,则需要进行对整个工程的关闭工作,同样是通过SDK中的函数PlxPci_DeviceClose()来关闭DMA通道。然后释放开辟的所有内存块空间,并将指针赋NULL值。系统连续存储的整个过程从开始到结束,虽然进行了很多个DMA传输的操作,但是只进行了一次DMA通道的打开和关闭,从而尽可能低的减小由于这部分时间带来的速度影响。软件流程如图5所示。
图5 采集存储系统软件流程图
根据图5可以观察到系统引入了多线程技术,多线程技术的实现是通过分别创建两个函数,一个控制DMA控制器进行连续的数据传输,另一个用于将内存中的数据快速的存储到磁盘阵列中,然后创建成为两个线程。当准备开始进行数据传输的时候,首先是设置DMA传输的参数并打开DMA通道。在此过程中还需要申请多块内存空间进行缓存数据,由于使用多线程技术,因此一块内存空间不能同时供两个函数同时读写,因此创建多个内存块,然后将两个线程同时打开,对开辟的多个内存块依次进行读写操作,但是由于整个过程只包含一个极短的时间延迟,因此完全可以将整个读写内存的过程近似的看成一个同时进行读写操作,因此达到提高存储的速度的目的。
传输速度分析
RAID 0又称为Stripe或Striping,它代表了所有RAID级别中最高的存储性能。RAID 0提高存储性能的原理是把连续的数据分散到多个磁盘上存取,这样,系统有数据请求就可以被多个磁盘并行的执行,每个磁盘执行属于它自己的那部分数据请求。这种数据上的并行操作可以充分利用总线的带宽,显著提高磁盘整体存取性能。
表2 RAID0方式下读写阵列速度比较(MB/s)
该系统在实际的采集存储过程中,连续存储的速度在135MB/s,因此用两块或者三块磁盘组成的RAID 0阵列就能完全满足设计要求。因为存储的速度仍明显高于采集卡DMA传输的速度,而且可以通过扩展RAID卡上的硬盘数进一步增加磁盘阵列存储速度。表2的实验数据使用四个Western Digest WD3200AAJS硬盘,因为使用同样大小或者规格的硬盘能够更好的使用所用的磁盘空间。由表中的数据可以看出,随着磁盘数目的增加,其存储的各项指标均有明显的提高,该磁盘阵列卡Rocket RAID 2680最多可提供8块SATA硬盘,随着采集卡采集传输的速度的提升,可以用更多的磁盘组建磁盘阵列,来匹配前端采集卡的带宽,所以整个系统只需更换一个更高速的PCI-E采集卡就可以实现更高存储速度的高速采集存储系统。
图6 高速采集存储系统照片
结论
设计一个基于PC主机北桥的长时间不间断高速采集和存储的系统。利用PC北桥PCI-E扩展技术,将采集卡和存储都连接到计算机北桥,此法可以用于后续通道进一步扩大的应用中。本文最后介绍了利用PC主机、PCI-E接口芯片PEX8311、Switch芯片PEX8616和RAID磁盘阵列卡,构建一个PCI-E架构的实时海量存储系统的案例。数据通过PC机的北桥芯片,实现采集卡到磁盘阵列存储卡的数据高速传输。虽然在采集卡采用PCI-E X1的情况下并不能完全体现将整个系统都集中在主机北桥的优势,但是它将会在更进一步的设计和研究中体现出来。

