- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
先进纳米IC设计面临新的寄生电路提取挑战
录入:edatop.com 点击:
晶圆代工工艺技术的更新换代使IC设计密度、性能和节能特性得以不断提高, 但也为设计人员带来了更多挑战。FinFET晶体管等创新的新工艺特性要求大幅度提高寄生参数提取精度,以通过仿真和分析来验证实体设计的性能。本文将会介绍新的寄生电路提取挑战,并探讨工具技术是如何不断发展以满足新要求的。
提出新工具要求的原因
在IC采用了特定实体布局后,IC设计人员需要提取它的详细电气性能,以便进行静态分析和仿真,确保IC能正常运行并满足关键的性能要求。特别是针对16nm及以下的工艺,精确获取FinFET器件中的寄生电阻和寄生电容,以及器件间的交互作用和与互连线相关的寄生电路至关重要。此外,不同的晶圆代工厂制作FinFET器件的方法存在差异。例如,有些晶圆代工厂在设计好的 FinFET之间使用浮置器件,这样一来,捕获FinFET至浮置器件的耦合以及主要有源器件之间的耦合就非常重要。此外,FinFET中的寄生电阻也非常重要—随着鳍形通道和源漏区变窄,源漏电阻增大,器件性能会有所降低。
双重图案工艺使问题变得更加严重,因为制造期间任何掩模失准都会增加或缩短多重图案层上的特征图案间距, 从而影响寄生电容的可预测性。因此,设计人员需要执行多重图案角落(corner)的仿真来表征潜在的失准。在实践中,这通常会涉及到超过10 个考虑工艺、温度和双重图案(DP)角落。使用传统工具时,全芯片抽取的时间通常为8至10小时(通宵);而采用双重图案工艺时,为提取全部所需的角落,处理较大的全芯片设计,经常需要花费更长的时间。有时,为节省时间,设计人员不得不限制定时分析,只运行少量精选的角落,这就增加了漏掉关键角落组合的风险。
另一大挑战是先进工艺节点的大型设计所需金属填充不断增加,使寄生参数提取工具负荷剧增。提取工具必须读取和处理数千兆字节的数据,才能准确建模填充图案的密度和相邻导线寄生电容。快速处理这些数据并制作简化的填充模型,对维持工具产出及管理提取工具的内存使用而言非常重要。
处理节点到节点成指数式增加的器件数目和交互复杂性原本就很困难,而精度更高、模型更复杂、角落更多的要求使得挑战更加艰巨,需要针对先进工艺节点完成大量的提取计算任务。即便如此,设计团队还是希望周转时间与之前节点处理时间一样—确切来说,就是希望能够通宵完成全芯片提取工作,这样在第二天就可以继续做设计工作。
新的工具方法
面对这些新的挑战,EDA供应商不得不退而求其次,重新开始来创建全新的提取结构。Mentor Graphics公司希望可以提供具备以下功能的工具:
● 精度可媲美参考级提取工具(其缺陷是速度较慢)。
● 周转时间与基于规则(rule-based)的工具保持一致(其缺陷是精度较低)
● 提取详细的FinFET器件模型。
● 支持同步多角落提取。
● 将多重图案技术融入提取流程中。
● 采用极快并高效的提取算法。
● 提供兼顾全芯片签核和IP特征提取的协调一致的解决方案。
● 通过高级减缩技术提供快速的下游仿真。
● 支持大规模平行处理方法。
● 多个CPU内的SMP和网络配置具备高度可扩展性。
要达到上述所有要求,需要结合多个创新方法来实现期望的功能。首先,要获得最佳精度,就需要场求解器,其功能如名所示—以三个维度求解麦克斯韦偏微分方程。 Mentor Graphics公司采用了一些既高效又高度平行化的创新型计算方法,使场求解器引擎的运行速度比传统参考级场求解器快好几个数量级。这将实现所需的阿托法拉级(AF)的精度,同时不会导致严重的性能损失。这是一项确定性技术(与Monte Carlo概率算法相比),能够以接近零的平均误差和低标准差来提供可重复的结果。
基于网络的平行化和多CPU处理
为获得接近完美的可以大规模平行处理的线性缩放,Mentor Graphics引入了新的分解方法。与典型的片铺(Tiling) 方法—将网络划分为众多子网格来单独处理不同,MentorGraphics所采用的方法可以保持网络完整,并在专用CPU上处理各完整网络。这种基于网络的平行化方法消除了精度方面的限制和晕轮效应,提供了优于平铺方法的可扩展性,特别是对于对称多处理(SMP)机而言(图1、图2)。此外,基于网络的平行化可以避免片铺时由于CPU数量变化而引起的结果精度的差异。
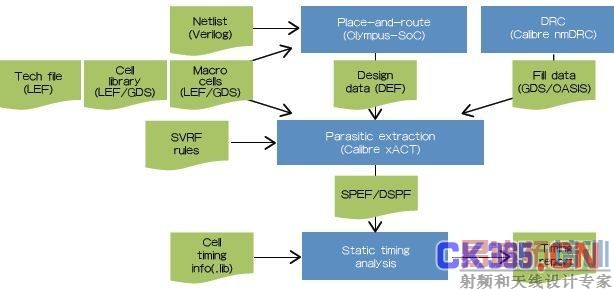
图1:新的Calibre xACT提取工具融入布局布线和静态时序分析(STA)步骤之间的数字流程,提供对STA工具非常关键的寄生和耦合效应的相关信息。
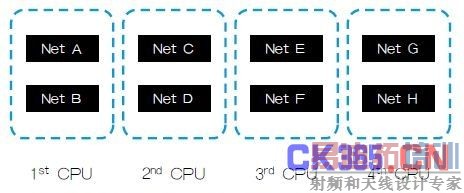
图2:采用基于网络的平行化,各个网络都发送至单一的CPU。由于各网络在处理时未经片铺、保持完整,该方法提供了一个高精度、可扩展性优异的解决方案。
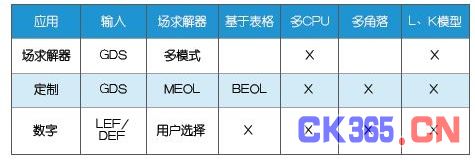
为进一步提高性能,新的架构针对精度要求较低的地方(例如上金属层)采用了具备高度可扩展性的基于规则的技术。表1展示了Calibre xACT如何针对不同的几何形状和层来自动挑选合适的提取技术。
表1:CALIbRe xACT平台针对特殊应用采取的最佳提取技术。
这些创新方法相结合能够将提取性能提高三倍,或实现8个CPU每小时4~8百万个网络的处理量,以及达到最尖端的晶圆代工厂签核要求的精度。通过新的 Calibre xACT架构,提取有1百万个台的IP仅需15分钟,而带2千万网络的全芯片提取也能在一夜之间完成。对于更大型的设计,可以通过增加额外的CPU来处理。
针对需要很多提取角落的设计,这款新平台执行同步多角落提取,各个角落的运行时间减少了15%~20%,而精度丝毫不受影响。由于该平台使用确定性技术,单一角落和多角落运行始终能够提供同样的结果,Monte Carlo方法则无法做到如此。
选择性网络处理和网表简化
加速周转时间并同时减少管理数据量的另一个方法是选择性网络处理技术。通过该技术,设计人员可以为各个网络选择特定的寄生模型,从而定制针对仿真而生成的数据量(图3)。设计人员可以按各个网络逐个选择分散RCC(带耦合电容)、 RC(不带耦合电容)、C或R,或依各层来控制提取。例如,为降低仿真时间,同时顾及大功率网络和地线网络的寄生效应,设计人员可以提取仅包含过孔电阻而排除金属层电阻的VDD和VSS网络。这个功能特别有用, 因为过孔对电源/地线网络形成的电阻最大。该功能可以加快仿真速度,同时维持所需的设计裕量。
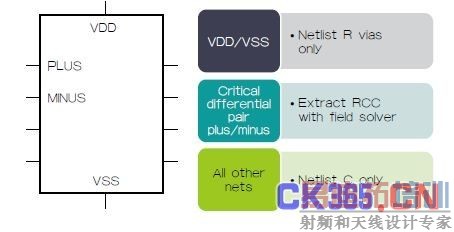
图3:Calibre xACT具备选择性处理功能。这个例子采用不同网络模型针对不同网络类型生成了网表。对于电源(VDD)网络和地线(VSS)网络,仅将过孔电阻提取到网表中。RCC模式提取了关键的差分对网络PLUS和MINUS,所有其他网络将只包含总电容值。
另一个节省时间的方法是从单个寄生参数提取数据库(或提取运行)生成多个网表。这个方法可用于生成多种网表格式和具备多寄生模式的网表,其可以根据各个网络进行控制。通过这种方法,设计人员无需在每次生成不同网络时运行提取,从而节省了时间;此外,还可以针对单个提取运行进行多个布局后分析。例如,设计人员可以在设计的所有网络上执行单个RCC提取运行;然后以RCC网络模型生成所有信号网络的SPICE网表,以进行时序分析;最后生成一个DSPF格式的仅包含电阻的网表,以用于电迁移分析。
仿真器性能在很大程度上取决于网表的大小,而寄生元件可能使网表尺寸成数量级增加。精度越高意味着寄生参数越多,但电路就会更加复杂,分析时间也会更长。这就是灵活的网表简化技术至关重要的原因—它可以尽可能地减少用于布线后仿真的寄生电路数据量,仅生成所需的寄生电路数据(图4)。这样不仅提高了仿真性能,还减少了分析时间和收敛性问题。
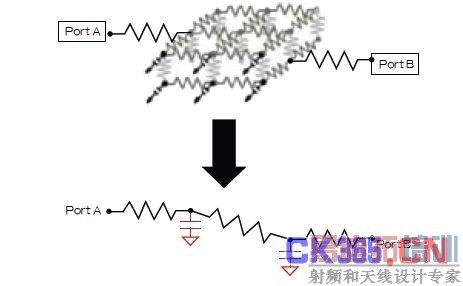
图4:设计人员可以微调网表简化设置,按照需要来控制精度水平和网表尺寸。在这个例子中,过孔阵列被极大地缩小,从而使仿真速度加快,同时又不影响精度。
总结
数字、定制、模拟或RF设计团队在处理任何节点,特别是16nm或更小的节点时,需要有比以往所有工具速度更快、精度更高、灵活性更强的提取工具。为应对挑战,EDA供应商需采用基于更高级架构和算法的新提取工具来获得所需功能。

