- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
基于动态可重构FPGA的容错技术研究
录入:edatop.com 点击:
摘要:针对重构文件的大小、动态容错时隙的长短、实现的复杂性、模块间通信方式、冗余资源的比例与布局等关键问题进行了分析。并对一些突出问题,提出了基于算法和资源多级分块的解决方法,阐述了新方法的性能,及其具有的高灵活性高、粒度等参数可选择、重构布线可靠性高、系统工作频率有保障的优点。
太空中存在大量的宇宙射线和高能带电粒子,它们对星载电子系统的照射会导致系统出错,甚至永久损坏。其所造成的辐射效应主要有位移损伤效应、电离辐射总剂量效应、瞬时电离辐射效应、单粒子效应等。而且由于器件集成度高,每个记忆单元的尺寸小,引起翻转所需的临界电荷也小,所以SEU的问题在空间器件上越来越严重。
现场可编程门阵列(FPGA,Field Programmable Gate Array)灵活、可重构的特性,对于克服器件设计错误和后天所导致的故障有效。基于可动态可重构FPGA,动态容错技术在理论上已得到发展,并出现了多种方法,其基本原理都是将备用的配置文件重新装载到FPGA上,以消除原有的暂态错误或者绕过故障区。
但在实际应用过程中涉及到许多问题。容错粒度的大小选择,是其中较突出的一个,这会影响到重构文件的大小、动态容错时隙的长短、资源利用率、实现的复杂度等方面。另外模块间通信方式、检错与定位的实现、冗余资源的比例与布局、暂态与永久错误的处理与分析都是有待深入研究的问题,很多方法过于复杂不容易实现或者过于简单而容错性能得不到保障,并且对以上这些问题分析不充分。
本文基于多种具体的实现方法,对这些问题进行了全面的分析与研究,并权衡各个方面,提出了基于算法和资源多级分块的方法,对其性能进行了分析。
这种方法中粒度、冗余资源比例等多项参数可以选择,重构时没有模块间布线的要求,能有效保障系统工作频率。
1 基于动态可重构FPGA的几种容错技术
1.1 基于Retiming理论的方法及分析
重定时(Retimg)技术的应用是建立在容错粒度较小的基础上的一种容错方法。它最初是针对静态电路以优化系统时钟为目的,且在整个电路设计过程中只使用一次。现在通过在FPGA中多次使用,改变触发器的位置以及增减触发器的数量可以达到重构的目的,并保证整个系统的功能稳定以及工作时序的协调。使用这种方法时,先根据约束条件生成一个Retiming矩阵,这个矩阵决定了触发器(FF)可能的各种布局。当电路出现故障时,通过调用矩阵的信息重新定位不同的FF以使电路恢复正常。
这种方法主要的特点就是不改变系统的功能而改变系统的结构特性,重构策略简单。如果结合可进化算法,处理器可以实时地计算得到有效的FF的重新布局。基于Retiming的实时重构可以有效地降低暂态故障的影响,尤其是SEU。同时这种方法配置文件量比较小,粒度水平高,重构过程系统开销小。
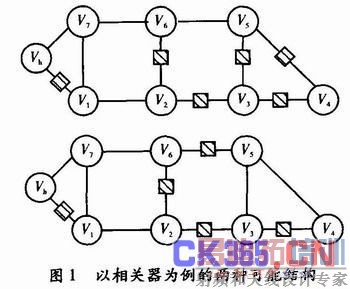
但是由于这种方法对电路的重构能力有限,所以容错能力得到一定的限制,尤其对于永久故障则容错率较低。其次,当完成FF的重新配置后,电路需要一个初始化时间,这个时间随着电路规模的增大而增大,当电路的规模和复杂度增大时这种方式的重构将导致较大的系统开销,这样电路规模受到限制并且对接口布线要求较高。图1所示给出了以相关器为例的两种可能的重构结构,其中小方块为FF。
1.2 基于STARs的方法及分析
基于移动自检测区域(STARs)的动态容错技术,是一种基于FPGA的具有多种容错级别的在线容错技术。它不仅可以进行逻辑工作区域的容错,也可以进行布线区域的容错。
基于STARs的方法,FPGA被划分为系统工作区和检测区,在检测区中进行内建自测试。若当前的被检测区完成被检测后STAR和相邻工作区的Slice交换位置,这样依次进行,最终STAR可以覆盖整个FPGA。其优势是,检测诊断总是在STAR中进行,不影响系统的工作,可以有充足的时间来进行精确的诊断和生成针对故障区的配置文件,并实现冗余。
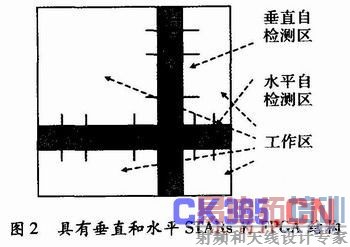
这种方法采用了动态系统时钟的概念。系统初始工作在最大时钟频率下,当部分重构使得某些部分的延时增加,那么根据布线的时序分析结果,通过周期可编程的时钟产生器降低时钟频率,以满足系统工作要求。这克服了一般容错方法中系统在整个寿命期工作在较低时钟频率下的缺点。
基于STARs的方法主要是针对永久性错误,包括配置存储器中的错误。STARs提供了一个相对于持续运行的工作区的离线区域。通过FPGA的边界检测接口可以使STAR中测试文件的配置动态进行而不影响系统工作。由于STARs的存在,工作区或者是连续的,或者是被STARs分割成不相连的区域,系统可以分别使用水平布线和垂直布线穿过V-STAR和H-STAR以实现通信。
这种方法采用了可编程逻辑块(PLB)重用技术。PLB重用是指以一种没有出错的模式来使用出错的PLB,即对在出故障的PLB中实现的功能来说这个PLB是没有出故障的。这有两种情况,一是故障PLB中的损坏部分并没有参与实现这个PLB内的功能单元,此时无需进行重新配置。第二种情况的一个简单例子是,当一个LUT的某个存储单元由于出错而固定置为0,且这个LUT用来实现一个组合逻辑,而此组合逻辑的这个存储单元恰要求被设置为0,那么这个错误就不需要进行冗余。由于PLBs的重用,冗余资源的利用率得到提高,容错量增大,系统寿命得到延长。另外这还使得损坏的PLB利用较远距离的冗余资源来重构而避开故障区的情况减少,所以,随着故障区增多,系统的时钟频率不会明显降低。
当STAR位置改变时,系统时钟必须停止以使STAR完成移动。系统时钟停止时,系统的工作状态必须被存储,并在系统时钟重新启动前被复制到新的工作区域。从STAR离开当前这个区域到下一次再检测这个区域的时间内,工作区电路可能出错,这个时间称为最坏的错误驻留时间。虽然基于STARs的方法,检测、诊断以及重构过程在理论上可以不影响系统工作,然而这也是它的缺点,不能对随时出现的错误进行容错。因此,必须考虑最坏的错误驻留时间,应该提高检测速度,而检测速度的提高会使STARs的移动速度提高。这导致检测区和工作区的交换频率增加,进而影响系统工作的连续性。
1.3 基于遗传算法及设计空间搜索的容错方法与分析
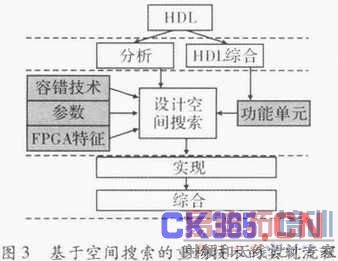
在重构容错的过程中,由于技术的多样性,同时会有多种可行的方案,而这很难通过人工来分析比较得到最优的解决方法。同时设计好的系统中必须有足够的存储量来存储针对不同故障的重构文件。因此文献提出了基于遗传算法的空间搜索技术。
首先用硬件设计语言描述系统功能,当设计完成后,对其实现功能进行分析并产生一个向量图,节点表示功能单元,有向线段代表他们之间的链接。同时,对源文件进行综合来识别其资源使用量(包括Slice数量,块RAN数量等)和各个功能单元的特征,最终形成一个功能单元库。这个库里面也包含一些标准器件和一些基本单元。另外在设计过程中还需要生成以下3个库:
器件特征库:存储对FPGA特征的描述,包括可用资源容量,基本重构单元大小,重构区域形状约束。
技术库:包含了部分重构技术的模型。
参数库:包含一些指导重构过程并衡量重构效果的参数。
系统工作时,先将原功能模块分成不同的组。然后根据参数要求在每一组内使用在技术库里选择的方法。遗传算法用来产生不同的可行的染色体,而染色体代表不同的处理方法。这种算法与TMR结合的例子如图4所示。
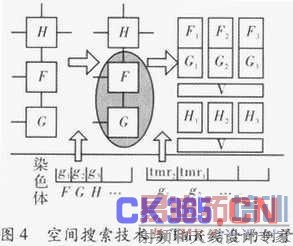
基于遗传算法的设计空间搜索方法需要设计者在前期作出大量工作,例如,遗传算法的设计,约束条件以及各库的形成。其中遗传算法的设计和参数设定是关键,同时系统需要较强的计算能力,系统开销较大。不过其所需配置文件存储量较小,解决方法多样,能产生出最优的解决方案。而且基于硬件遗传算法具有广阔的应用前景。
2 基于算法和资源多级分块的容错结构
2.1 方法的提出
动态容错粒度的选取是一个关键问题,如果粒度过小,则对错误的检测定位能力要求较高,而且配置文件复杂,如果在线生成配置文件,则需要较强的系统计算能力,这显然会增大系统的开销,破坏系统的连续性,而且布线复杂。如果粒度过大,那么冗余资源的利用率降低,配置文件增大,这削弱了系统的容错能力,且需要较大的存储资源。另外,对冗余资源比例的选择必须要考虑到系统布线难度,而布线所造成的延迟是不可预知的,所以系统工作频率也难以保证。上面这几种方法粒度水平不易改变,布线难度大,系统时钟性能不高,而且后两种实现难度较大。
现在采取算法和资源多级分块的方法进行系统的容错。可以在不更改方法的情况下,通过对算法和资源不同次数、不同大小的划分达到不同的粒度水平,进而满足容错需要。因为以算法模块为单位进行重构,且保证重构前后模块之间接口不变,那么模块外部无需重新布线,这样就削减了容错时系统开销,不会降低时钟频率。
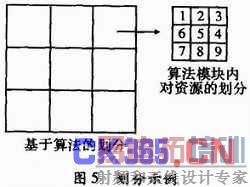
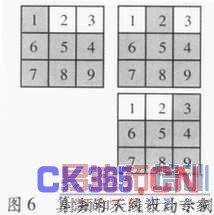
先将整个系统在减少模块间布线难度的情况下按照算法分块。然后将每个模块所使用的资源在有2/9以9等分为例,冗余资源的情况下进行9等分,这为第二级划分。如图5所示。现在需要解决的是配置文件的设计以及布局的问题。设计时,对实现相同功能的每—个算法模块进行多种不同的布局,每—个布局都留出其中2/9的冗余资源。当然其算秸结构可以不同,而实现相同功能的不同算法也可能会达到容错的效果,这将提高系统的容错能力。相同功能算法的不同布局结构如图6所示。
基于算法和资源两级分块的容错结构,在系统出现异常的情况下,首先采用相同的配置文件对电路进行重构。重构后如果异常消除,那么容错过程完成,而且出现的错误属于暂态错误。在系统工作的过程中,需要周期性地记录电路的状态,当出现故障然并进行重构后应该将记录的状态进行装载,以保持系统连续性及电路工作的正确性。如果这样的重构仍然没有解决问题,那么改变配置文件,利用布局不同的配置文件进行部分动态重构,用以解决永久性的故障。重构前后算法的功能应该保持不变,通过不同布局的重构使电路可以绕开硬件故障区,达到容错的目的。
为解决重构前后的通信问题,采取类似总线宏(Bus Macro)的通信结构,保持模块间重构前后通信布线不变。而且每一次重构,必须保证4个方向的通信端口和内部模块连接也不变,重构后的电路都接在原有对外接口上。总线宏只能用于相邻的两个模块间的通信,对于不相邻的模块间的通信,采用称作可重构多路总线(Recongigurable Multiple Bus)的动态开关信号的通信结构。以一维结构为例,即现有模块分布在一条线上。当一个模块Mk需要和另一个不与自己相邻的模块通信时,它向与自己相邻的且与要通信的模块在相同方向上的模块Mk+1发出请求,Mk+1再向Mk+2发出请求,如是依次下去直到需要通信的模块Mk+i收到信号,接着它以相反的路径返回一个应答信号,当Mk收到应答信号后,两者开始通信。
2.2 方法分析
假设在第二级划分时将每一个模块所占用的资源分成N2等分,称N为等分数,冗余资源为N-1,每一个资源单位出错概率为P(N),则系统正常工作的概率为
![]()
由仿真结果可知,随着每一个模块所占资源等分数的增加,系统容错能力提高,而同时冗余资源所占的比例却下降。可以看到,基于算法和资源的两级分块容错结构,相对于以往基于模块的重构方法,进一步降低了系统的容错粒度,提高了系统的容错率和冗余资源的使用效率,而且在容错的同时起到了检错和定位的作用。省去了实际用于检错和定位的硬件或软件开销,而且系统也不需要在线计算配置文件等,提高了系统的连续性和可靠性。
由于重构前后模块对外功能接口都不变,相当于一个电路黑盒子,节省了外部布局布线的时间和计算时间,系统容错时开销降低。其他的一些冗余方法,例如以CLB为最小单元,每次利用冗余资源绕过故障区需要复杂的布局布线,而这样的布局布线所造成的延迟是难以避免的,只有通过降低芯片工作频率来保证系统时序的稳定。而现在所采取的结构虽然在布局上进行了两次划分,但是对于每一个模块的外部仍然是基于功能模块的容错,每次都是以经过测试的成熟的功能算法为单元的,不存在算法内部重新布线后造成延迟的问题,保证了系统的高速运行,这也是本方法的主要特点。
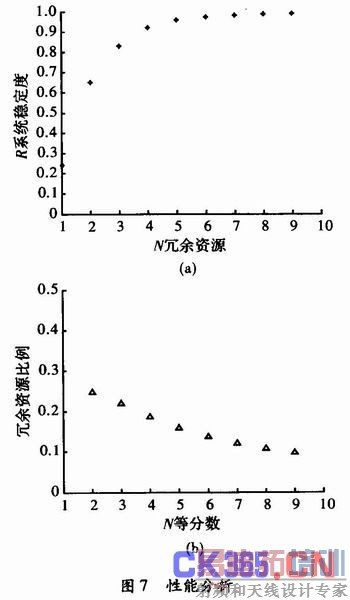
采用逐级划分的方法可以合理的选择所需的容错粒度,以及容错能力。可是随着级数和对每一个模块等分数目的增加,预编译的配置文件数量将增大,这样系统需要较多的存储资源来存储这些文件。如果采用遗传算法,根据硬件资源与工作模块的分级分块结构进行在线计算,那么这个问题将得到解决。
3 结束语
文章对基于FPGA的动态可重构技术在容错领域的应用进行了研究。针对重构文件的大小,动态容错时隙的长短、资源利用率、实现的复杂性、模块间通信方式、冗余资源的比例与布局等方面的问题分析了一些方法的优缺点,针对突出的问题,提出了一种基于算法和资源多级分块的容错方法,可以在不影响系统工作的情况下完成基于动态重构的容错。这种方法结构简单,多项参数可以选择,尤其是粒度的可变性。冗余资源比例较低,重构时没有对模块外进行布线的要求,不会因重构造成延迟而降低系统的工作频率。

