- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
基于数据挖掘技术的入侵检测系统
录入:edatop.com 点击:
1 引言
随着计算机网络不断发展,各种问题也随之产生,网络安全问题尤为突出。传统的入侵检测技术包括滥用检测和异常检测。其中,滥用检测是分析各种类型的攻击手段,找出可能的“攻击特征”集合,可有效检测到已知攻击,产生误报较少,但只能检测到已知的入侵类型,而对未知的入侵类型无能为力,需要不断更新攻击特征库;而异常检测的假设条件是通过观察当前活动与系统历史正常活动情况之间的差异可实现攻击行为的检测。其优点是可检测到未知攻击,缺点是误报和漏报较多。针对现有网络入侵检测系统的一些不足,将数据挖掘技术应用于网络入侵检测,以Snort入侵检测系统模型为基础,提出一种新的基于数据挖掘的网络入侵检测系统模型。
2 数据挖掘在入侵检测系统中的应用
数据挖掘技术在入侵检测系统(IDS)中的应用,主要是通过挖掘审计数据以获得行为模式,从中分离出入侵行为,有效实现入侵检测规则。审计数据由经预处理、带有时间戳的审计记录组成。每条审计记录都包含一些属性(也称为特征),例如,一个典型的审计日志文件包括源IP地址、目的IP地址、服务类型、连接状态等属性。挖掘审计数据是一项重要任务,直接影响入侵检测的精确性和可用性,常用的挖掘方法有关联性分析、分类、序列分析等。
(1)关联性分析关联分析就是要发现关联规则,找出数据库中满足最小支持度与最小确信度约束的规则,即给定一组Item和一个记录集合,通过分析记录集合推导出Item间的相关性。一般用信任度(confidence)和支持度(support)描述关联规则的属性。关联分析的目的是从已知的事务集W中产生数据集之间的关联规则,即同一条审计记录中不同字段之间存在的关系,同时保证规则的支持度和信任度大于用户预先指定的最小支持度和最小信任度。
(2)分类映射一个数据项到其中一个预定义的分类集中,它输出“分类器”,表现形式是决策树或规则。在入侵检测中一个典型的应用就是,收集足够多的审计数据送交用户或程序,然后应用分类算法去学习分类器,标记或预测新的正常或异常的不可见审计数据。分类算法要解决的重点是规则学习问题。
(3)序列分析用于构建序列模式,以发现审计事件中经常存在的时间序列。这些经常发生的事件模式有助于将时间统计方法应用于入侵检测模型。例如,如果审计数据中包含基于网络的拒绝服务攻击DOS(Denial of Service Attack)行为.由此得到的模式就要对在这一时间段内工作的每个主机和每项服务进行检测。[next]
3 基于数据挖掘的入侵检测系统模型
针对现有入侵检测系统挖掘速度慢和挖掘准确度不高的缺点,提出基于数据挖掘技术的入侵检测系统模型.该模型的结构如图1所示。

3.1 模块功能简述
(1)嗅探器主要进行数据收集,它只是一个简单的抓取信息的接口。嗅探器所在位置决定入侵检测的局部处理程度。
(2)解码器解码分析捕获的数据包。并把分析结果存到一个指定的数据结构中。
(3)数据预处理 负责将网络数据、连接数据转换为挖掘方法所需的数据格式,包括:进一步的过滤、噪声的消除、第三方检测工具检测到的已知攻击。利用误用检测方法对已知的入侵行为与规则库的入侵规则进行匹配,直接找到入侵行为,进行报警。
(4)异常分析器通过使用关联分析和序列分析找到新的攻击,利用异常检测方法将这些异常行为送往规则库。
(5)日志记录保存2种记录:未知网络正常行为产生的数据包信息和未知入侵行为产生的数据包信息。
(6)规则库 保存入侵检测规则,为误用检测提供依据。
(7)报警器 当偏离分析器报告有异常行为时,报警器通过人机界面向管理员发出通知,其形式可以是E-mail。控制台报警、日志条目、可视化的工具。
(8)特征提取器对日志中的数据记录进行关联分析,得出关联规则,添加到规则库中。
3.2 异常分析器
异常分析器使用聚类分析模型产生的网络或主机正常模型检测数据包。它采用K-Means算法作为聚类分析算法。图2为异常分析的流程。

异常分析器的检测过程为:(1)网络或主机数据包标准化;(2)计算网络数据包与主类链表中聚类中心的相似度:(3)若该网络数据包与某一主类的相似度小于聚类半径R,则表明其是正常的网络数据包,将其丢弃;(4)若该网络数据包与所有主类的相似度大于聚类半径R,则表明其是异常的网络数据包。
3.3 特征提取器
特征提取器用于分析未知的异常数据包,挖掘网络异常数据包中潜在的入侵行为模式,产生相应的关联规则集.添加到规则库中。该模块采用Apriori算法进行关联规则的挖掘,其工作流程如图3所示。
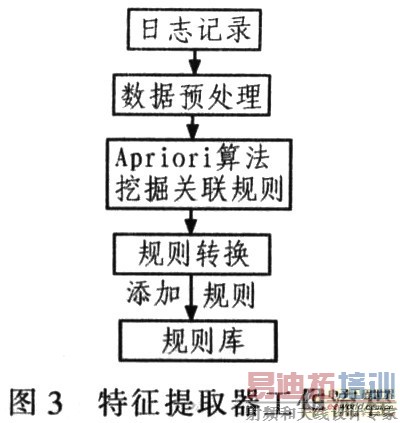
特征提取器的工作过程可分为数据预处理和产生关联规则。
(1)数据预处理 特征提取器的输入为日志记录.包含很多字段,但并非所有字段都适用于关联分析。在此仅选择和Snort规则相关的字段,如SrcIP,SrcPort,DstIP,DstPort,Protocol,Dsize,Flags和CID等。
[next]
(2)产生关联规则首先根据设定的支持度找出所有频繁项集,一般支持度设置得越低,产生的频繁项集就会越多;而设置得越高,产生的频繁项集就越少。接着由频繁项集产生关联规则,一般置信度设置得越低,产生的关联规则数目越多但准确度不高;反之置信度设置得越高。产生的关联规则数目越少但是准确度较高。3.4 系统模型特点
该系统在实际应用时,既可以事先存入已知入侵规则,以降低在开始操作时期的漏报率,也可以不需要预先的背景知识。虽然该系统有较强的自适应性,但在操作初期会有较高的误报率。因此该系统模型有如下特点:(1)利用数据挖掘技术进行入侵检测;(2)利用先进的挖掘算法,使操作接近实时;(3)具有自适应性,能根据当前的环境更新规则库;(4)不但可检测到已知的攻击,而且可检测到未知的攻击。
4 系统测试
以Snort为例,在规则匹配方面扩展系统保持Snort的工作原理,实验分析具有代表性,分析攻击模式数据库大小与匹配时间的关系。
实验环境:IP地址为192.168.1.2的主机配置为PIV1.8G,内存512 M,操作系统为Windows XP;3台分机的IP地址分别为192.168.1.23,192.168.1.32,192.168.1.45。实验方法:随机通过TcpDump抓取一组网络数据包,通过该系统记录约20 min传送来的数据包,3台分机分别对主机不同攻击类型的数据包进行测试。
异常分析器采用K-Means算法作为聚类分析算法,试验表明.误检率随阈值的增大而迅速增大,而随阈值的减小而逐渐减小。由于聚类半径R的增大会导致攻击数据包与正常数包被划分到同一个聚类,因此误检率必然会随着阈值的增大而增大。另一方面,当某一种新类型的攻击数据包数目达到阈值时,系统会将其判定为正常类,因此阈值越小必然导致误检率越高。当聚类半径R=6时,该系统比Snort原始版本检测的速度快,并且误检率也较低。
特征提取器采用关联分析的Apriori算法,置信度设置为100%,阈值设为1 000,支持度50%,最后自动生成以下3条新的入侵检测规则:
alert tcp 192.168.1.23 2450->192.168.1.2 80(msg:”poli-cy:externalnet attempt to access 192.168.1.2”;classtype:at-temptesd-recon;)
alert tcp 192.168.1.32 1850->192.168.1.2 21(msg:”poli-cy:extemalnet attempt to access 192.168.1.2”;classtype:at-tempted-recon;)
alert tcp 192.168.1.45 2678->192.168.1.2 1080(msg:”policy:extemalnet attempt to access 192.168.1.2”;classtype:at-tempted-reeon;)
该试验结果说明经采用特征提取器对异常日志进行分析,系统挖掘出检测新类型攻击的规,并具备检测新类型攻击的能力。
5 结束语
提出一种基于数据挖掘的入侵检测系统模型,借助数据挖掘技术在处理大量数据特征提取方面的优势,可使入侵检测更加自动化,提高检测效率和检测准确度。基于数据挖掘的入侵检测己得到快速发展,但离投入实际使用还有距离,尚未具备完善的理论体系。因此,解决数据挖掘的入侵检测实时性、正确检测率、误警率等方面问题是当前的主要任务,及丰富和发展现有理论,完善入侵检测系统使其投入实际应用。

