- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
用FPGA构建PCI Express端点器件的平台
录入:edatop.com 点击:
| PCI Express是一种使用时钟数据恢复(CDR)技术的高速串行I/O互连机制。PCI Express Gen1规范规定的线速率为每通道2.5Gbps,可以让您建立具备单通道(x1)链路2Gbps(经8B/10B编码)直至32通道64Gbps吞吐量的应用。这样,就能在保持或改进吞吐量的同时,显著减少引脚数量。另外,还可以减小PCB的尺寸、降低迹线和层的数量并简化布局和设计。引脚数量减少,也就意味着噪声和电磁干扰(EMI)降低。CDR消除了宽并行总线中普遍存在的时钟-数据歪斜问题,简化了互连实现。 PCI Express互连架构主要针对基于台式/膝上(PC)的系统。但就像PCI一样,PCI Express也很快转移到其他系统类型,如嵌入式系统。它规定了三种类型器件:根联合体(root complex)、交换器件和端点(图1)。根联合体大致等同于PCI主机,CPU、系统存储器和图形控制器与之相连接。由于PCI Express的点对点特性,必须使用交换器件来增加系统功能的数量。PCI Express交换器件将上游端的根联合体器件连接到下游端的端点。 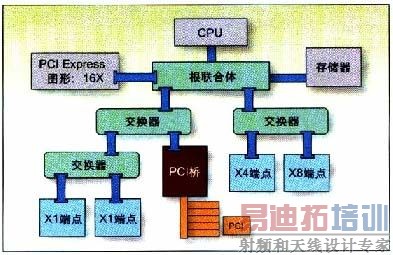 图1:PCI Express拓扑。 端点功能类似于PCI/PCI-X器件。最常用的端点器件有以太网控制器或存储HBA(主机总线适配器)。FPGA最常用于数据处理和桥接功能,所以其最大目标功能就是端点。FPGA实现非常适合于视频、医疗影像、工业、测试和测量、数据采集和存储应用。 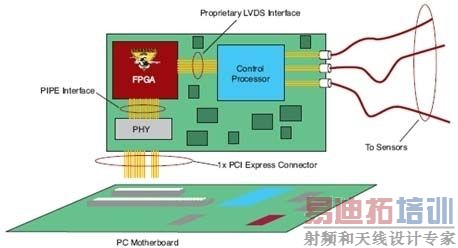 图2:基于Spartan-3 FPGA的数据采集卡。 PCI特别兴趣小组(PCI-SIG)采用的PCI Express规范规定每个PCI Express器件使用三个不同的协议层:物理层、数据链路层和事务层。您可以使用单芯片或双芯片解决方案来构建PCI Express端点。例如,使用Xilinx Spartan-3器件之类的低成本FPGA,您可以用商用离散PCI Express PHY(图2)来构建数据链路和事务层。此选项最适合于x1通道应用,如:总线控制器、数据采集卡和提高性能的PCI 32/33器件。或者,您可以使用类似Virtex-5 LXT或SXT FPGA的单芯片解决方案,它们具备集成的PCI Express PHY。此选项最适合于通讯或高清晰度音频/视频端点器件(图3),它们对性能的要求更高:x4(8Gbps吞吐量)链路或x8(16Gbps吞吐量)链路。 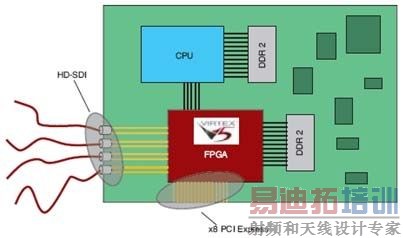 图3:基于Virtex-5 LXT FPGA的视频应用。 在选择一种技术来实现PCI Express设计之前,必须仔细考虑应用的IP选择、链路效率、兼容性测试及资源可用性。本文中,我们将简要介绍使用最新的FPGA技术构建单芯片x4和x8通道PCI Express设计的一些因素。 IP的选择 作为设计人员,您可以选择构建自己的软IP或者向第三方或FPGA供应商购买IP。构建自己的IP的难题在于,您不光得从零开始创建设计,还得担心验证、批准、兼容性和硬件评估等环节。向第三方或FPGA供应商购买的IP,已经过所有严格的兼容性测试和硬件评估,可以即插即用。如果使用商用的、已验证的兼容性PCI Express接口,您可以把精力集中在设计中最有附加值的部分:用户应用。使用软IP的难题在于应用的资源可用性。软IP核的PCI Express MAC层、数据链路层和事务层通过可编程架构实现,因此您必须特别注意剩余Block RAM、查找表和架构资源的数量。 另一选择是使用最新技术的FPGA。Virtex-5 LXT和SXT的专用门电路(图4)中实现了集成x8通道PCI Express控制器。这种实现极具优势,因为设计是在硬硅片中实现的,所以需要的FPGA逻辑资源数量达到了最小。例如,在Virtex-5 LXT FPGA中,一个x8通道软IP核可占用多达10,000个逻辑单元,而硬实现只需要大约500个逻辑单元,多数用于接口。这样的资源节省有时候能允许您选择更小的器件,而器件越小通常就会越便宜。集成实现通常具有更高的性能、更宽的数据通路,并且可通过软件配置。 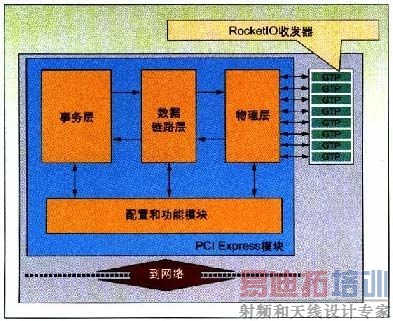 图4:Virtex-5 LXT FPGA PCI Express端点框图。 软IP实现的另一难题是功能的数量。通常,此类核仅实现满足性能或兼容性目标规范所要求的最少功能。相反,硬IP可以支持基于客户要求的全面功能列表,并提供完全的兼容性(表1),且不存在严重的性能或资源相关的问题。 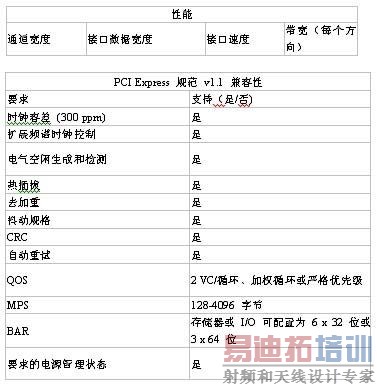 表1:Virtex-5 LXT FPGA PCI Express功能。 |
延迟
尽管PCI Express控制器的延迟不会对总体系统延迟有很大的影响,但却会影响接口的性能。使用较窄的数据通路有助于减少延迟。
对PCI Express来说,延迟就是发送包并穿过物理层、逻辑层和事务层接收包所需的周期数。典型的x8通道PCI Express端点的延迟为20~25周期。250MHz下,转换为80~100ns。如果使用128位的数据通路实现接口来简化时序(如125MHz),延迟会加倍为160~200ns。在最新的Virtex-5 LXT和SXT器件中,无论是软IP实现还是硬IP实现,都采用250MHz下的64位数据通路进行x8实现。
链路效率
链路效率是延迟、用户应用设计、有效载荷大小和额外开销的函数。随着有效载荷大小(通常称为最大有效载荷)的增加,有效链路效率也会增加。这是由包的额外开销固定不变这一事实造成的;如果有效载荷大,效率就提高。一般情况下,256字节的有效载荷可提供93%的理论效率(256有效载荷字节+12头字节+8帧字节)。尽管PCI Express允许的包大小可达4KB,但如果有效载荷大小大于256或512字节,大多数系统的性能都无法提高。由于链路协议额外开销(ACK/NAK、重新发送包)和流程控制协议(授权报告),在Virtex-5 LXT FPGA中实现x4或x8 PCI Express的链路效率为88~89%。
利用FPGA实现可以更好地控制链路效率,因为它允许您选择与端点实现对应的接收缓冲器尺寸。如果链接双方不是采用相同的方式实现数据通路,则二者的内部延迟会不同。例如,如果一号链接方使用64位、250MHz实现,延迟为80ns,而二号链接方使用128位、125MHz实现,延迟为160ns,该链路的组合延迟即为240ns。现在,如果一号链接方的接收缓冲器设计成160ns的延迟(即期待其链接对方也是64位、250MHz实现),那么链路效率就会降低。如果采用ASIC实现,就不可能改变接收缓冲器的尺寸,效率损失将是实实在在的,而且是永久性的。
用户应用设计也会对链路效率有所影响。用户应用必须设计成定期排空PCI Express接口的接收缓冲器,并保持发送缓冲器时刻充满。如果用户应用不立即使用接收的包(或者不立即响应发送请求),无论接口的性能如何,总链路效率都会受到影响。
使用某些处理器设计时,如果处理器不能执行大于1DWORD的突发,则需要实现一个DMA控制器。这将造成链路利用不充分,效率不佳。大多数嵌入式CPU可以发送长于1DWORD的突发,所以通过良好的FIFO设计就可以有效地管理这些设计的链路效率。
PCI Express兼容性
兼容性是经常被遗漏和低估的重要细节。如果要构建必须与其他器件和应用结合使用的PCI Express应用,则必须确保设计的兼容性。
兼容性不只针对IP,而是针对整个解决方案,包括IP、用户应用、硅片器件和硬件板。如果整个解决方案已经过PCI-SIG PCI Express兼容性研讨会(别号“plug fest”)验证,就基本保证了您设计的PCI Express部分会一直有效。
本文小结
PCI Express已替代PCI成为事实上的系统互连标准,并且已从PC转移到其他系统市场,包括嵌入式系统设计。
FPGA非常适合于构建PCI Express端点器件,因为它允许您创建带有用户所需的附加定制功能的兼容性PCI Express器件。
类似Virtex-5 LXT和SXT系列的新65nm FPGA完全符合PCI Express规范v1.1,并为用户应用提供广泛的逻辑和器件资源。使用外部PHY的Spartan-3系列FPGA提供了低成本解决方案。这些因素,加上内在的可编程逻辑优势(灵活性、可再编程性和低风险)使FPGA成为PCI Express的最佳平台。
上一篇:英军迷你探测器千米之外秒杀敌方狙击手
下一篇:低压双绕组电流互感器设计及应用

