- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
28 nm时代系统设计面临的变化与挑战
录入:edatop.com 点击:
IC设计的新方向
28-nm工艺节点最大的好消息是显著增大了晶体管密度,也就是在给定区域中,能够容纳更多的逻辑门、寄存器和存储器。在很多应用中,前几代系统级IC已经集成了适合集成实现的大部分功能。那么,在28 nm,芯片设计人员很容易使用所有这些额外的晶体管来提高性能,降低功耗,而这是调整工艺无法实现的。或者,他们选择更小的管芯来降低成本。他们也可以选择组合使用这些方法,定制实现某些特殊的应用。
在很多情况下,芯片设计人员会选择尝试实现系统开发人员所期望的芯片级性能指标。他们可以通过使用晶体管来提高性能,在应用中,发挥内在的并行功能的优势。
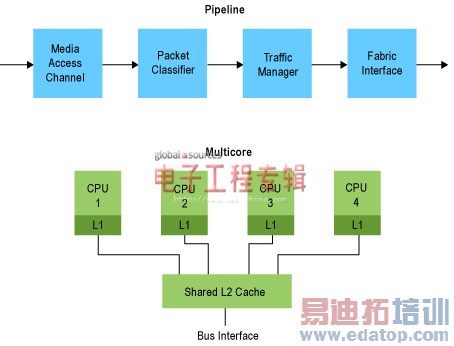
图2.两类并行体系结构
发挥并行功能的优势
有几种方式来实现并行功能。至少与应用相关的一种方式是简单延长设计中执行单元的流水线,在指令级一次执行多条指令。对于数字算法的内循环加速器等应用,例如,数字信号处理,这一方法特别有效。但是,在通常的计算中,研究表明,同时一次执行三条指令反而会降低性能。
一种密切相关的方法是建立功能级模块流水线,这是数据包处理应用中目前常用的方法。在这种方法中,数据通过处理器链,每一处理器都对数据进行某一特殊的功能处理。这类流水线与具体应用密切相关,如果功能与状态或者数据相关,在执行过程中,设计人员尝试改变流水线的工作时,设计会变得非常复杂。
目前在并行方面最流行的方法是多处理器,很多处理器从共享存储器中采集数据和任务,并行工作。在这方面有很多变化。数字加速器通常使用单指令多数据(SIMD)群,每一处理器单元装入不同的数据,但是,都使用公共的指令流。在处理器群中,每一处理器完成固定的任务,从输入序列中采集数据,在输出序列中产生结果,彼此相互独立。还有全动态多核设计,完全相同的处理器从工作序列中采集任务和数据,执行它们,除了内部任务通信之外,彼此独立工作。
所有这些方法都有效的提高了系统级IC的处理带宽。或者,芯片设计人员可以通过并行方法来维持性能不变,但是减小了每一独立处理单元的时钟速率,支持采用更低的工作电压,以及低泄漏晶体管和相似的低功耗方法。但是,只有具体应用有足够的并行功能,处理单元保持忙状态,不会中断时,这些方法才有效。但这是很大的挑战。
可能最明显的问题是以足够快的速度实现管芯数据的输入输出,以跟上处理能力的变化。芯片设计人员能够成功的使用越来越强的并行功能以提高芯片处理带宽。但是,I/O带宽和存储器带宽都没有及时跟进。越来越有可能设计系统级IC,但实际上无法很快的移动数据以支持自己的处理速度。
由于复杂的DRAM时序,采用并行功能进一步加剧了这一问题。如果DRAM必须支持不同处理单元或者高速缓存控制器存储器不同任务的存储器申请随机散射功能,那么,页缺失的频率会明显增大,影响总带宽和DRAM传送的预测能力。非常复杂的DRAM控制器能够解决这一问题,但是,代价是增大了每一处理操作的延时不确定性。类似的,芯片设计人员会采用基于收发器的高速串行总线,例如,PCI Express Gen3等,或者Interlaken等芯片至芯片连接技术以提升I/O带宽。但是,很多处理器单元不协调的申请会影响最佳突发或者流总线协议,降低了快速I/O的效率。
降低功耗
芯片设计人员可以使用28-nm工艺额外的晶体管再度提高性能指标,甚至可能利用晶体管来降低功耗。从一开始就选择应用最佳工艺来提高效率,选择晶体管阈值电压和工作电压的最佳组合。某些设计会在芯片的整个逻辑部分选择一个工作点。其他的在不同模块上采用不同的电压,只有很少的会根据特殊管芯的性能要求、温度以及固有速度来动态调整关键模块的工作电压。类似的,很多设计采用了具有不同阈值电压或者可调阈值电压的晶体管,选择足够快的晶体管,使模块甚至是某一时序通路达到时序收敛。某些设计还会关掉空闲模块的时钟或者电源。这类动态方法实际上非常有效,但是带来了晶体管成本问题,以及功耗开销,增大了延时,例如,时钟频率或者电压转换延时等。
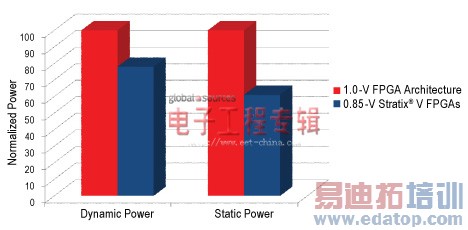
图3.相同工艺,相同体系结构在0.85 V和1.0 V时的静态和动态功耗对比
下一页:系统设计人员的任务

