- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
3G手机语音识别应用中DSP的选择策略
录入:edatop.com 点击:
随着DSP技术的进步,计算能力更强、功耗更低和体积更小的DSP已经出现,使3G手机上植入更精确更复杂的自动语音识别(ASR)功能成为可能。目前,基本ASR应用可以分成三大类:1. 语音-文本转换(语音输入);2. 讲者识别;3. 语音命令控制(语音控制)。
这三类功能包含了3G所需的众多ASR性能。语音-文本转换的典型实例是语音拨号和电子邮件听写。讲者识别功能可以通过语音识别安全地读出存储器中的个人数据,从而满足*定购和银行服务等保密性高的应用需要。语音命令控制功能包括连接语音扩展标记语言(VXML)网站内容的语音接口,它支持财经服务与目录助理等业务。目前VXML被用于规范网站内容的语音标签。
语音识别的两种方法
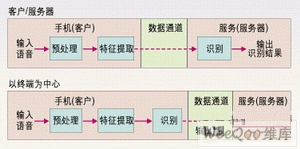
3G手机的ASR应用设计可分为两类,即以终端为中心和以客户/服务器为中心的应用。如图1所示为以终端为中心的设计方法,3G手机(终端)执行整个语音识别过程并送出识别结果。在图2所示的客户/服务器方法中,终端只是执行预处理特征提取,然后通过一个误码受保护的数据信道将这些参数发送给中心服务器,中心服务器最终完成语音识别。如果采用以客户/服务器为中心的设计方法,3G手机应使用数据信道而非移动信道来将语音发送给服务器进行识别,因为移动信道所用的低速率语音编码会严重影响语音识别的性能。
各种ASR系统的差异主要体现在词汇量上。一个简单的网络设备可能只需要16字的词库就能实现所要求的语音识别功能,而3G移动手机则需要更大的专业词库。这些词汇可以跟讲者相关(训练语音识别设备使之熟悉用户的声音特征)或跟讲者无关(语音识别设备可以识别任何人的声音),DSP的计算负荷就随着词汇量和训练数据的增加而增大。
例如,根据隐性马尔可夫模型(HMM)可以分析一个典型的跟讲者无关的100条命令识别的应用实例。假设HMM模型从左到右没有跳跃地顺序摆放,共有6个状态、5个具有对角协方差的混合高斯分布,包含39个特征(13唛-频率对数系数或MFCC,及其一阶和二阶差分),具有16位精度,那么,HMM声学模型的大小就是100×5×5×(39+2)×2=240kB。
为了实现输入语音样本差分、窗口截获、MFCC抽取、概率计算和维特比搜索等运算的实时性,典型情况下需要消耗DSP的1千万个乘法-累加周期(MMAC)。对于连续语音识别来说,上千个三音素模型和多种语法模型需要更多的存储空间,也需要更快的DSP处理速度。
因此,移动电话中ASR系统的成败很大程度上取决于DSP的功能和设计。第三代系统本身就需要比第二代系统更强性能的DSP,而增加ASR功能就对DSP提出了更高的要求。从结构角度看,对DSP性能的要求是处理速度快、功耗低和代码密度高。
采用高速DSP是关键
由于系统要实时对语音进行处理和取样,因此语音识别系统需要具有巨大的计算能力。下面的数字和计算假设采用的是围绕终端的设计方法。如果将DSP计算资源的20%分配给一个10MMAC的语音识别系统使用,那么就需要一个具有50MMAC的DSP才能满足这一功能需要,并可提供足够的空间执行3G手机所需的其它DSP任务,如处理软猫。如果采用较慢的DSP,如25MMAC的DSP,那么词汇表中的命令数量就要减半,或减少HMM参数,这样会降低整个系统性能。
DSP的速度决定了语音识别系统的复杂性和性能。举例来说,如果一个基本的跟讲者无关的连续语音识别系统需要100MMAC,DSP计算资源的50%用于满足3G手机的其它DSP任务的需求,那么DSP的处理速度就需要达到200MMAC。
成本、性能和效率的折衷
DSP的速度越快,就越便于利用现代的HMM技术,如信道匹配和声域匹配技术,因此,理论上讲,DSP速度越快,ASR系统的性能就越好。然而,并行处理方法在提高ASR系统吞吐量中也扮演着重要角色。例如,一个具有4 ALU(算术逻辑单元)的200MHz DSP比只有1 ALU但运行于400MHz的DSP具有更高的吞吐量。根据具体应用的不同,2到3个单ALU DSP提供的性能与一个具有4 ALU的DSP相仿。相对一个具有4 ALU的DSP处理器方案来说,多个单ALU的DSP会提高手机的成本,因此对于适销对路产品要充分权衡成本与性能之间的折衷。
总之,当比较一个600MHz的单ALU DSP和一个300MHz但有4 ALU的DSP时,设计工程师始终应把握的最终目标是高效的运算吞吐量,具有多个ALU的DSP也许是最好的解决方案。
性能与功耗
顶级性能的DSP采用并行结构来获得最佳的性能空间。有个著名的平衡型并行结构StarCore SC140就采用了指令级并行结构,它具有4个并行ALU以及一个称为变长执行集(VLES)的改进型甚长指令字模型。VLES的优点在于它支持在内存中完成高效的指令调度、执行和打包。它能通过一个指令队列对前端提供反馈,并通过调度器控制后端,因此除非需要执行计算,VLES处理一般不消耗功率。
在并行VLES结构中,一些特殊指令需要成组以避免空操作(Nop),由于减少了时钟周期,处理时间也相应减少了。比较而言,在甚长指令字计算中,所有执行步骤都必须按顺序排列,因此在一个8字节的执行集甚至是1字节数据时,系统就需要7个占位符(placeholder)或Nop。
由于VLES结构不需要Nop,VLES设计中的复杂性从硬件或编程器转移到了编译器。由于每个周期都充满了数据,因此每个周期就具有更高的效率,从而也提高了电源与内存的使用效率。
电源管理
由于ASR系统需要连续处理语音数据,会使DSP成为消耗电能的主要部件,因此高效利用电源对设备成功走向市场至关重要。
在高性能DSP中,选择16位指令集而非32位指令集能提高代码密度,进一步减少对内存、功耗和体积的需求,一部分原因是由于更短的16位指令集可以减少寄存器和数据线数量。例如在ASR应用中,存储的词汇量可能达到2.5MB(对于1024簇的三音素状态,5个合成和39个参数来说,声学HMM状态模型是400KB;一本有1万个三态三音素代码本是60KB;三音素状态转移概率矩阵是500KB;一个具有40个杂乱态2万字的双字母组是1.6MB)。如果DSP具有高的代码密度,能为ASR系统提供固定数量的存储器,那么就可以获得更好更大的声学和语言模型。
片上和片外存储器
对于ASR系统中使用的DSP来说,有效地利用片上和片外存储器是另外一个重要的课题。由于ASR系统需要大量的存储空间用于词汇与模式识别数据的存储,一个灵活的存储结构在这里将显得特别重要。例如,一个具备统一寻址存储器的DSP能使设计工程师很好地平衡程序和数据,还能平衡系统算法的复杂性与声学和语言模型的大小以获得最优化的性能。
例如,如果具有100条命令的识别系统模型只有100kB的片上系统内存,总共内存空间需求是240kB,那么采用二次识别方法能更有效地利用片上快速存储器。
第一次(原始识别阶段)只使用39个参数中的13个MFCC,因此模型大小为80kB,可以载入片上内存。原始识别阶段的候选命令数量要比原来的100个少,比方说是33个命令,但可信度高达99.9%。
第二次(精确识别阶段)把33个候选命令的39个参数作为模型使用,大小是80kB,因此又可以把该模型装载入片上内存。这种二次识别方法会引入一些延时,但延时非常小,大约只有10ms,说话人一般不会觉察到。
统一寻址存储器能够支持较大的词汇库或命令集,还能支持较大的HMM模型或神经网络系数,因此能简单化实时任务。例如为ASR系统的程序和数据准备100kB的存储器,设计工程师就能平衡好算法复杂性与词汇量或命令集大小之间的关系。如果程序要占50kB,那么数据只能是50kB。如果允许降低识别精度而将程序代码压缩到20kB,那么命令集就能用到80kB,也就是增加了词汇库容量。
在ASR系统中,高度并行化、高代码密度和有效利用存储器等优点还能使DSP完成语音识别以外的任务。在大多数情况下,设计工程师可以将部分计算资源分配给语音识别之用,而将剩余资源用来执行信道处理系统中所需的其它任务。
在选中最优化的DSP后,要想获得高性能的ASR用系统级芯片还需要增加一些功能,例如快速缓存或快速指令/数据存取以及实时操作系统(RTOS)才能使ASR系统真正完成实时性能。多任务RTOS能使系统同时运行多个应用如双通道语音识别,因此能极大地提高系统性能。
复杂SoC应用(如信道处理系统)设计工程师能从使用高效的高级语言编译器的DSP和SoC中获益,因为这些编译器允许设计工程师使用C或C++语言进行编程。采用增强的片上仿真和调试功能还可以进一步缩短设计时间。对于3G移动手机应用中各层次的元器件与系统设计来说,除了实时性能和简化设计流程外,功率管理控制同样非常重要。在设计SoC时,选择具有可调功率功能的内核将获益非浅。例如当移动用户在说话时,DSP需要全速运行(如300MHz)。当未使用ASR功能时,SoC电源管理电路可以逐步降低到较低的时钟速度(如100MHz),从而有效地降低漏电和功耗。
由于ASR系统对计算速度的需求会根据识别特征的差异产生很大变化,例如孤字识别或连续语音识别、词汇量和跟讲者无关的语音识别等,因此,能支持ASR功能的信道处理系统的复杂性变化也很大。
SoC非常适合于构造芯片的基础架构,因此在以客户/服务器系统为中心的设计中是非常理想的选择,但SoC器件由于功能太强大,因此并不非常适合于用户端以终端为中心的设计。然而,随着ASR系统的逐渐成熟以及3G手机支持越来越复杂的应用和复杂ASR,这类功能强大的SoC也能成功地运用到用户端。
在SoC上使用多个DSP能使系统在完成语音识别的同时更容易地执行其它任务。例如三个内核中的一个可以专门指定用来完成多信道的服务器端ASR,而其它二个内核用于执行像语音信道和互联网数据处理这样的任务。将来如果手机键盘不复存在的话,ASR将成为用户与手机之间的唯一接口,到时这一功能将占用大部分的工作时间。
采用多个DSP内核还能提供强大的计算能力,从而使执行非常复杂的ASR任务成为可能,如电子邮件听写中的连续语音识别、安全交易和VXML中的“口令+讲者验证”等。多个DSP再加上统一的大型片上存储器可以极大地缩短跟讲者无关的训练过程,因为在统计型ASR中训练过程的计算负载比识别处理过程的负载重得多。
本文小结
尽管3G手机要想赢得市场,人们对其功能和设计仍将拭目以待,但这些系统需要高性能的信号处理平台以满足多媒体任务需求是不容置疑的,而随着ASR系统的不断普及,3G手机肯定需要具备运行多任务能力的多DSP SoC作为解决方案。
如何成为一名优秀的射频工程师,敬请关注: 射频工程师养成培训
上一篇:无线通讯OFDM调制的实现
下一篇:TD-LTE微微蜂窝基站测试
