- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
处理器设计下一步——单芯片同步多处理技术
录入:edatop.com 点击:
在指定的组织管理技术下,要将个别处理器性能发挥到极限非但不容易,也没有效率。更快的时脉、更深的管线和更大的缓冲存储器会占用更大的芯片面积同时增加功耗成本,削弱了原本可提升10%性能的效益。有时候在没有选择的情况下,不得不将时脉速度提高并将电源和冷却子系统升级;倘若使用将负载划分到多个处理器的方式,不但可以增加最大整体性能限制,也可简化处理器设计使其更有效率。
目前有许多系统级芯片(SoC)设计利用多处理器的优势,但它们均针对特定应用或采用松散耦合方式。直到最近,针对软件多处理方案的SoC设计选项依然受到限制。但MIPS32 1004K同步处理系统(CPS) SoC组件的推出,意味着可在单一操作系统环境下实现芯片上对称式多重处理(SMP)。
虽然平行编程很容易让软件工程师理解,但并非所有现今的程序代码都是针对平行处理平台所编写,业界已有许多针对平行软件的范例,其中有一些对软件设计人员来说也相当熟悉。
数据平行算法
数据平行算法(Data-parallel algorithm)将数据组划分到多处理器,甚至到若干个CPU中。在教科书中,可将大型资料组看作一个大量输入文件或数据数组;但在嵌入式系统中,它可能意味着高I/O和事件服务频宽。在某些SoC架构中,多个输入数据来源(如网络接口端口)可以被静态地分配到针对自然平行数据、执行相同驱动程序/路由程序代码的多个处理器中。
当在单一资料数组或输入流中利用多处理器性能时,用于分割并管理资料的平行算法就很常见。这种算法对于单处理器来说通常不是最理想的,但由于具备了更灵活的频宽运算特性,因此可提供效率补偿。这些针对平行运算算法均具备灵活性,但要是将一个工作程序转换成一个平行资料算法也许不具任何意义,甚至是相当困难或是不可能实现的,而这完全取决于程序相依性这类因素。如果绝大部分的应用程序运算都仅采用很少的常规运算循环来实现,那么,为提高性能,系统设计师也许要明确地建置资料平行算法。
随着用于PC、工作站和服务器的多核心X86芯片问世,新的数据库和工具套件应运而生,使得平行算法得以轻易地在少量的处理器上实现。许多用于嵌入式架构的数据库和工具套件都是开放且可携的,如MIPS为GCC所做的C/C++以及Fortran扩展,也正逐渐成为标准GNU编译器的一部分。
平行控制编程
平行控制编程(Control-parallel programming)并非根据输入,而是根据任务分割工作。若将一个以100人制造一台汽车为单位的汽车制造工厂比喻为一个100信道平行数据算法,并将平行控制程序比喻为一个具有100人的组装线工作站,各工作站负责百分之一的工作量,通常组装线的效率会比较高,但组装一台车的工作量就只有这么多,这样的限制在科学程序代码扩充到几千个处理器时非常显著,然而对于平行SoC架构而言这并不是个问题。
软件工程师通常将程序划分成若干个阶段以易于编码、除错和维护,并减少指令内存和快取的工作量。通常,平行控制分解早已设在可见的操作系统(OS)任务层。在类似于Unix的系统中,单一命令‘cc’会依序呼叫C语言前置处理器、编译器、组译器和连结程序。它们之中的几个可以同时执行,每个连续程序利用前一个阶段的输出作为输入,在类似于Unix这样的OS内使用档案或软件管线。
当独立分解的执行任务尚未完成时,需进行一些软件工程,使应用程序在OS和底层硬件上是可见的,并能在任务间明确地传递资料。但是不应该需要对阶段算法进行重写。粗粒度的任务分解可透过档案、网络应用程序(socket)或管线的进程通讯来实现。而针对细粒度的控制,如Posix执行绪API——pthreads,可由许多OS支持,包括Linux、Windows以及许多实时操作系统。
复杂的、模块化的多任务嵌入式软件系统时常会展现出意外的同步。整体系统任务很可能涉及到对应不同输入的不同责任等多项任务。若没有一个时间共享的OS,各任务就必须在个别处理器上执行。在一个时间共享的单处理器上,它们在轮流时间中执行;在一个具有SMP操作系统的多核心处理器上,它们能在可利用的处理器上同步执行。
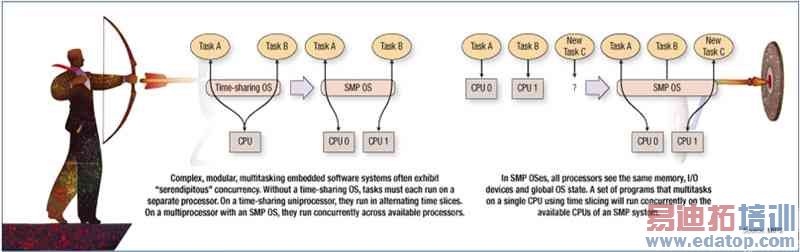
图1a:复杂的模块化多任务嵌入式软件系统时常会展现出意外的同步。有了一个时间共享的OS,各任务就必须在个别处理器上执行。在一个时间共享的单处理器上,它们在轮流时间中执行;在具有SMP操作系统的多处理器上,它们在可利用的处理器上同步执行。图1b:在SMP操作系统中,所有的处理器都面对相同的内存、I/O组件和全域OS状态。在单CPU上利用时间分段执行的多任务程序,将能同时在一个SMP系统中的CPU上执行。
分布式处理
分布式典型运算在网络客户服务器模式中很常见,它在某些时候不被认为是‘平行’的。客户端服务器程序设计基本上是一种控制流程分解的形式。程序任务并不是独自执行所有的运算,而是将工作请求发送到针对特定工作设计的特殊系统任务。客户端服务器程序设计大多都在LAN和WAN上完成,但SMP SoC也遵循相同的范例。未作修改的客户端服务器二进制数据可透过芯片上的TCP/IP或空回绕网络(loopback network)接口进行通讯,或者使用更有效率的方法,利用区域通讯协议在内存中传递缓冲资料。
这些方法可能会被单独或组合使用,以藉助SMP的性能优势。有人甚至可能会建构一个分布式SMP服务器的平行数据数组,且各数组均建置一个控制流程管线。
在SoC系统中,可以对处理器的静态实体分解任务进行平行处理,处理器的平行任务可于硬件中完成,这可以减少软件开销和实体尺寸,但却不能提供灵活性。
如果可以将一个嵌入式应用静态地分解成客户端和服务器,并通过芯片互连进行通讯,那么只需要使用信息传递程序代码建置一个共享协议,以便将系统互相连系。信息传递协议可提供一个抽象层,使或多或少的处理器配置都能执行一般的应用程序代码,但无论任何配置,处理器的负载平衡就如同硬件分割一样是静态的。要达到更灵活的平行系统程序设计,可利用具有共享资源多核心处理器系统上的软件任务分配来实现。
在SMP操作系统中,所有的处理器都面对相同的内存、I/O组件和全域OS状态,这使得处理器间的程序移转更简单、更有效率,也更容易平衡负载。不需要额外的编程或系统管理,在单CPU上利用时间分段执行的多任务程序,将能同时在一个SMP系统中的CPU上执行。如同Linux,一个SMP的排程器可切换处理器的程序。
执行多个处理程序的Linux应用程序不需要修改,就可以利用SMP平行特性,而且通常不需要进行重新编译。SMP Linux环境为可用处理器之间的调整提供了许多工具,如提高/降低任务的优先级,或是对于在处理器子集上执行任意任务加以限制。要使用不同的实时排程体制,必须要有适当的核心支持。
类似Unix的OS能为应用程序提供一些针对相关任务优先级排程的控制,甚至在单核心处理器时间共享系统中也是如此。传统的外部命令和系统呼叫指令在Linux系统中被强化,藉由更精致的机制排定任务优先级、任务组或特定系统使用者。另外,在多核心处理器配置中,任一Linux任务都具有一个参数,用来指定那一组处理器可排定任务。预设参数即为整个系统处理器组,但这种具有类似于CPU的系统处理器组却是可控制的。
SMP范例要求所有处理器找寻所有相同地址下的内存;对于低性能的处理器,必须透过将所有处理器的指令预取和加载/储存流通量,置放在一个共享的内存和I/O总线上来达成。然而这种模式随着处理器的增加而失去效用,因为总线会成为瓶颈。即使在单核心处理器系统中,高性能嵌入式核心的指令和数据频宽需求也支配了主存储器和处理器间的缓冲存储器。
在一个每颗处理器均具备独立快取的系统中,其本质上已不属于SMP,当一个处理器的快取保存了内存中唯一一个最近位置值的复制数据时,这时不对称就产生了,必须加入快取一致性协议来恢复对称。
在一个所有处理器都连接到一个公共总线的简单系统中,快取控制器可监控总线,以得知哪一个高速缓存保存了指定内存位置的最新版本。在更先进的系统中,是利用交换结构的点对点的连接将处理器连接到内存,因此快取一致性需要更高度的支持。一致性管理单元应该对内存执行施加全域指令,产生干涉讯号来维护处理器核心间的高速缓存一致性。
像Linux这样的SMP OS可自由地转移任务,动态地均衡处理器负载。在嵌入式SoC中,绝大部份的整体运算可以在中断服务中执行。好的负载均衡和性能调整必须对发生中断服务的地方进行控制。Linux OS具有一个类似于IRQ的控制接口,可让使用者和程序确认哪一个处理器负责指定的中断服务。
快取忆体一致性基础架构很实用,不仅在SMP的处理器间,在处理器和I/O DMA信道之间也相当有用。若是使用软件的方式,便需要在每个I/O DMA作业之前或之后利用CPU来处理DMA缓冲器,对于I/O密集的应用而言,性能将大受影响;而使用I/O一致性硬件将I/O DMA连接到内存的方式,可以对DMA串流进行排序,并与一致的加载/储存流程整合在一起,免除了软件的开销。
快取一致性管理单元应该对处理器、I/O和内存间的内存串流施加命令,这可增加处理器内存存取时间的周期,透过管线停滞产生处理器周期损失的结果。然而,一些如在单一核心上使用硬件多执行绪的方法,可允许单核心执行并行的指令串流,以增加管线的效率。
各核心的执行绪看起来就如同OS软件中完善的CPU,包括具有独立的中断输入。执行绪共享相同的缓冲存储器和功能单元并插入到它们的管线执行中。若一个执行绪停滞了,另一个可以继续执行,让一致性内存子系统延迟周期循环下去,否则将会遗失。管理多核心的相同SMP OS可以管理它们的硬件执行绪,针对SMP编写的软件可运用多执行绪处理,反之也然。
若两个执行绪同时争取一个管线,其性能相较于在许多独立核心上两个执行绪来得更低,应该对SMP Linux核心进行负载均衡最佳化。对于功耗最佳化,排程器可以将工作一次一个加载到一个核心的虚拟处理器上,使其它的处理器处于低功耗状态。在性能最佳化方面,可以将工作分配到许多核心上,然后将多执行绪加载到每个核心中,直到所有的核心都有一个进展中的任务为止。
利用芯片上多处理功能可实现高SoC性能。SMP平台和软件提供了一个具有灵活性的高性能运算平台,能大幅提升单一处理器的速度,而这通常只需要稍微、或者根本不需要修改应用程序代码。
