- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
提高能效/扩大频宽 DRAM朝3D堆叠架构迈进
录入:edatop.com 点击:
动态随机存取记忆体(DRAM)设计正走向立体(3D)堆叠架构。电子产品对尺寸及效能要求日益严苛,促使DRAM制造商积极采纳3D堆叠与Wide I/O设计架构,以在晶片尺寸微缩同时,提高记忆体密度与频宽效能,并降低传输每位元所需的功耗。
动态随机存取记忆体(DRAM)产业已形成三巨头的态势。2013年7月31日,美国的美光(Micron)完成了对日本尔必达(Elpida)与台湾瑞晶的购并,并且取得华亚的营运主导权后,现在台面上所谓的DRAM三大公司(The Big Three),系包括韩国三星(Samsung)与海力士(SK Hynix),加上扩张之后的美光。DRAM产业积极整并的趋势,可以由图1三大业者合计的市场占有率变化一窥端倪--从2007年第一季的约69%,一路上升至2013年第四季的约92%。
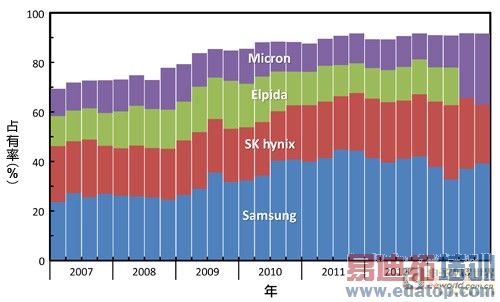
图1 三大DRAM公司市占率分析 资料来源:DRAMeXchange
三巨头垄断DRAM市场 台DRAM业者拚转型
过去PC当道时,大部分产能聚集于标准型DRAM。一旦PC市场蓬勃,易造成DRAM短缺,单价开始升高;此时,厂商也会开始增加产能,使得供给追上需求,但也容易导致供给失衡,使价格崩跌。随着PC市场衰退,标准型DRAM景况愈来愈严峻,但是由于三大公司的寡占,供给得以控制,并维持价格的稳定与上扬。以结果而言,确实让存活的业者受惠,却是留给台湾剩下不到10%的市场。台湾的DRAM厂商纷纷退出标准型DRAM。在历经茂德转型为无晶圆厂(Fabless)、华邦转型为轻晶圆厂(Fab-lite)、力晶转型为晶圆代工厂、南亚转攻利基型市场之后,现在台湾的DRAM产业处于无力扩张产能,同时制程技术又落后一至一点五个世代的窘境。
台湾的DRAM厂商虽然在利基型DRAM市场耕耘许久,但是大多着力于特殊型DRAM,出货又以低容量产品为主。低容量记忆体的核心阵列(Core Array)在面积上所占据的比重较低,周边电路得以沿袭旧有的设计或进行微幅的修改。长久以来,台湾的DRAM厂商依循摩尔定律(Moore's Law),透过导入更先进的制程技术,增加每片晶圆上的晶片数,降低单位的生产成本。只不过,先进制程的取得几乎都是经由外部技术移转。台湾的DRAM厂商在低功率的制程发展与高能效的规格设计等附加价值,与三大公司相比仍有一段落差。
台湾的DRAM产业转型造就了独特的DRAM无晶圆厂与晶圆代工的经营模式。因为无论制造、封装、测试皆委由第三方,无晶圆厂的资本密集程度较低。又因为台湾的半导体产业上、下游衔接完整,因此具有发展优势。不过,即便是利基型产品,售价仍旧随着时间的推移而下跌。为了维持收入,无晶圆厂必须提高现有产品的销量、取得相称的成本降幅,或导入利润较高的新产品,在总量上抵消或弥补预期的售价跌幅。若要提高产品的销量,第三方必须分配更大的产能或提高良率。DRAM晶圆代工厂因为无法自外于产业整并的影响,同时自身的财务状况也非十分健全,通常难以保证长期的产能;因此,投入改变传统架构的客制化DRAM的新产品开发似乎较为可行。
与终端产品应用紧密结合 客制化DRAM势力抬头
利基型与标准型的差异是其客制化的程度较高,因而与终端产品的结合也更紧密。譬如,行动型DRAM是按季议价接单制造,使得供给符合需求,生产行动型DRAM的厂商就能够产生利润。受惠于智慧型手机应用的拓展,单机搭载的行动型DRAM位元量也随之攀升,但是三大公司在行动型DRAM的市场占有率接近100%,台湾的DRAM厂商的影响力几乎无足轻重。
无论是标准型或行动型DRAM,很自然地成为寡占市场上少数决定的游戏。最明显的例子是,三大公司可以在标准正式公布之前,就开始试产与送样,而且总能为他们所认可的标准找到客户,并提前在其产品上的使用做设计。即便如此,三大公司也认知DRAM产业正逐渐走向客制化。换言之,DRAM厂商现在要与客户共同开发,提供记忆体的解决方案。客制化的程度可以小到修改标准型DRAM某一个对特定应用相对重要的时序参数,大到使用矽穿孔(Through Silicon Via, TSV)的异质晶片堆叠架构,打造新的利基型DRAM。
超越摩尔定律 厂商竞逐3D DRAM技术
半导体产业在预期成长趋缓、产能扩充受限、制程微缩接近极限等考量之下,超越摩尔定律,让元件朝垂直方向整合,就变成追求的目标。
所谓的「三维(3D)整合」在形成多层的主动元件时产生许多不同的方法,这里或许可以简单地以制作顺序区分为循序式(Sequential)与并行式(Parallel)两种。前者意指上、下层主动元件的形成是在同一晶片上循序渐进,层层累积;后者则意指上、下层主动元件的形成是各属不同晶片分别并行,片片堆叠。它们的差异可以用上、下层主动元件的垂直距离加以区别--循序式三维整合的垂直距离小于1微米(μm),并行式三维整合的垂直距离通常大于10微米。
循序式三维整合是单晶同质整合,因此追求装填密度的提升若非唯一也会是它最大的诉求。并行式三维整合允许不同的制程与技术节点的晶片堆叠,可以将各自的优点结合,也就是异质整合。异质整合依技术与设备到位的情况来看,由前段制程提供者(如晶圆代工厂)向后延伸,因为可以主动地开发载具,比较容易获得进展。由后段制程提供者(如封装测试厂)向前延伸,因为普遍缺乏设计能力,只能被动地取得载具,因此需要较长时间发展。
DRAM核心的记忆单元将储存电容器(Storage Capacitor)堆叠在存取电晶体(Access Transistor)之上,早已在同一晶片上朝垂直方向整合主动元件(电晶体)与被动元件(电容器),因此几乎都采取并行式三维整合,藉由晶片堆叠增加容量或频宽。混合记忆体立方(Hybrid Memory Cube, HMC)就是这种新型态利基型DRAM的一个范例。
[@B].利基型3D DRAM典范—HMC[@C] .利基型3D DRAM典范—HMC
HMC是DRAM与逻辑晶片的异质整合,以矽穿孔垂直连线,以微凸块(Micro Bump)接合,堆叠四或八颗做为资料储存的DRAM晶片在一颗做为管理与介面的逻辑晶片之上。它的进展是由美光主导,如图2所示:首先藉着第一代原型产品的概念验证,并且在2011年9月英特尔科技论坛(Intel Developer Forum)展示,引起广泛的注意;之后成立联盟共同发展,公布第二代量产产品的规格书,开始试产与送样;然后再有联盟成员的厂商配合以现有产品做系统呈现或未来产品做规画。

图2 DRAM晶片堆叠过去3年的发展
.标准型DRAM堆叠遇瓶颈
标准型DRAM晶片堆叠,特别是第三代双倍资料率记忆体(DDR3),从2010年开始就有厂商陆续宣示已经准备就绪,但是进展却远不如利基型DRAM顺遂。其中一个原因,可能是因为对效能的提升通常与下世代产品预期相符,例如DDR3到DDR4。在成本、技术、产业链等考量下,客户宁可等待下世代产品,也不愿冒险使用。因此有些人认为标准型DRAM晶片堆叠也许要在现在DDR世代结束之后才会开始。
行动型DRAM使用的一种宽输出/入(Wide I/O)架构,系将四条独立的128位元200Mbit/s通道置于单一晶片上,并可以透过并行式三维整合堆叠至多四颗晶片,提高记忆容量。固态技术协会(JEDEC)在2011年9月28日颁布MO-305产品轮廓,2012年1月5日颁布JESD229规格书,确实将此一架构与介面标准化,但在少数实际产品应用却出现无法与JEDEC标准相容的介面,如图3所示。因为在系统上异质整合须要求DRAM晶片与逻辑晶片更密切的结合,前段的设计、制造与后段的封装与测试技术变得环环相扣,这些需求其实都与客制化无异,标准化扮演的角色似乎也随着DRAM产业整并而越来越弱。
图3 三星 Wide I/O DRAM与JEDEC规范的微凸块分配的差异
DRAM的发展趋势--大频宽、高能效
DRAM的发展可以从过去其资料传输的尖峰频宽,与传输每位元所需要的能源效率的改变观察(图4)。随着产品世代的更迭,DRAM为了符合效能需求提供更大的尖峰频宽,同时也提高能源效率以维持功率中立(Power Neutrality)。行动型DRAM的功率大约1瓦(W),绘图型DRAM的功率大约4瓦,高效能计算(High-performance Computing, HPC)用DRAM的功率则是15瓦或更大。可以预期这个趋势将继续,JEDEC商定中的Wide I/O 2与高频宽记忆体(High Bandwidth Memory, HBM)基本上都在这个能源效率挤压在小于5pJ/b的设计空间探索,使得传统的DRAM架构逐渐难以应付。
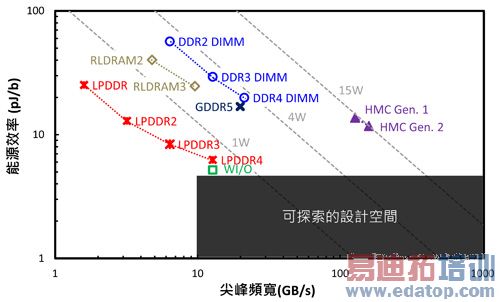
图4 DRAM频宽增加与能效提升趋势分析
只在意核心通量(Core Throughput)的设计,会将输出/入位元数与资料传送率当做折衷的参数,输出/入埠越宽或资料传送率越高,都将增加功率消耗与晶片面积。为了维持功率中立,就要减少输出/入电容、摆幅与资料转变,异质整合的晶片堆叠就有这些益处。
另一方面,过去20年间DRAM核心阵列的传播时延,受限于列线的RC时间常数,平均每年只减少不到5%。图5显示Wide I/O DRAM的列周期时间(Row Cycle Time, tRC),相较于各个DDR世代,并未出现太大的改变。随机列周期时间决定存取DRAM的潜伏(Latency),是记忆体阶层设计的重要参数。
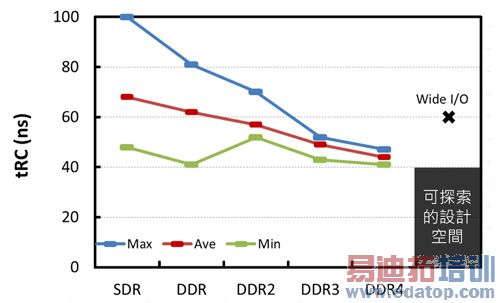
图5 Wide I/O DRAM与不同DDR世代的列周期时间比较
处理器晶片内嵌的最后一层快取记忆体(Last Level Cache, LLC),通常在记忆体阶层的第二或第三层,与外置的做为主记忆体的DRAM,不论是延迟或容量,在比值上都有明显的差异(图6)。换言之,大部分的资料被存放在速度很慢的主记忆体,这就是记忆墙(Memory Wall)的表征。近来处理器的核心数迅速增加,它们之间存在的鸿沟也越来越大。
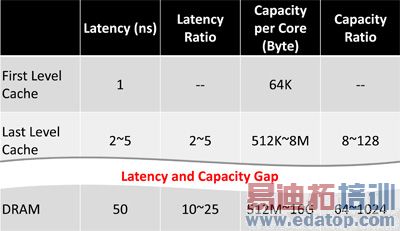
图6 存在目前记忆体阶层的延迟时间与储存容量鸿沟
以英特尔(Intel)的处理器为例,在短短的3年内,其最大核心数从8上升至15,因此再插入一层以分立DRAM晶片做成的快取记忆体似乎可行。这个新的快取DRAM的延迟约在10~25奈秒(ns),每核平均分配的容量约在16~512百万位元组,同样地在异质整合的晶片堆叠也能派得上用场。
动态随机存取记忆体(DRAM)产业已形成三巨头的态势。2013年7月31日,美国的美光(Micron)完成了对日本尔必达(Elpida)与台湾瑞晶的购并,并且取得华亚的营运主导权后,现在台面上所谓的DRAM三大公司(The Big Three),系包括韩国三星(Samsung)与海力士(SK Hynix),加上扩张之后的美光。DRAM产业积极整并的趋势,可以由图1三大业者合计的市场占有率变化一窥端倪--从2007年第一季的约69%,一路上升至2013年第四季的约92%。
图1 三大DRAM公司市占率分析 资料来源:DRAMeXchange
三巨头垄断DRAM市场 台DRAM业者拚转型
过去PC当道时,大部分产能聚集于标准型DRAM。一旦PC市场蓬勃,易造成DRAM短缺,单价开始升高;此时,厂商也会开始增加产能,使得供给追上需求,但也容易导致供给失衡,使价格崩跌。随着PC市场衰退,标准型DRAM景况愈来愈严峻,但是由于三大公司的寡占,供给得以控制,并维持价格的稳定与上扬。以结果而言,确实让存活的业者受惠,却是留给台湾剩下不到10%的市场。台湾的DRAM厂商纷纷退出标准型DRAM。在历经茂德转型为无晶圆厂(Fabless)、华邦转型为轻晶圆厂(Fab-lite)、力晶转型为晶圆代工厂、南亚转攻利基型市场之后,现在台湾的DRAM产业处于无力扩张产能,同时制程技术又落后一至一点五个世代的窘境。
台湾的DRAM厂商虽然在利基型DRAM市场耕耘许久,但是大多着力于特殊型DRAM,出货又以低容量产品为主。低容量记忆体的核心阵列(Core Array)在面积上所占据的比重较低,周边电路得以沿袭旧有的设计或进行微幅的修改。长久以来,台湾的DRAM厂商依循摩尔定律(Moore's Law),透过导入更先进的制程技术,增加每片晶圆上的晶片数,降低单位的生产成本。只不过,先进制程的取得几乎都是经由外部技术移转。台湾的DRAM厂商在低功率的制程发展与高能效的规格设计等附加价值,与三大公司相比仍有一段落差。
台湾的DRAM产业转型造就了独特的DRAM无晶圆厂与晶圆代工的经营模式。因为无论制造、封装、测试皆委由第三方,无晶圆厂的资本密集程度较低。又因为台湾的半导体产业上、下游衔接完整,因此具有发展优势。不过,即便是利基型产品,售价仍旧随着时间的推移而下跌。为了维持收入,无晶圆厂必须提高现有产品的销量、取得相称的成本降幅,或导入利润较高的新产品,在总量上抵消或弥补预期的售价跌幅。若要提高产品的销量,第三方必须分配更大的产能或提高良率。DRAM晶圆代工厂因为无法自外于产业整并的影响,同时自身的财务状况也非十分健全,通常难以保证长期的产能;因此,投入改变传统架构的客制化DRAM的新产品开发似乎较为可行。
与终端产品应用紧密结合 客制化DRAM势力抬头
利基型与标准型的差异是其客制化的程度较高,因而与终端产品的结合也更紧密。譬如,行动型DRAM是按季议价接单制造,使得供给符合需求,生产行动型DRAM的厂商就能够产生利润。受惠于智慧型手机应用的拓展,单机搭载的行动型DRAM位元量也随之攀升,但是三大公司在行动型DRAM的市场占有率接近100%,台湾的DRAM厂商的影响力几乎无足轻重。
无论是标准型或行动型DRAM,很自然地成为寡占市场上少数决定的游戏。最明显的例子是,三大公司可以在标准正式公布之前,就开始试产与送样,而且总能为他们所认可的标准找到客户,并提前在其产品上的使用做设计。即便如此,三大公司也认知DRAM产业正逐渐走向客制化。换言之,DRAM厂商现在要与客户共同开发,提供记忆体的解决方案。客制化的程度可以小到修改标准型DRAM某一个对特定应用相对重要的时序参数,大到使用矽穿孔(Through Silicon Via, TSV)的异质晶片堆叠架构,打造新的利基型DRAM。
超越摩尔定律 厂商竞逐3D DRAM技术
半导体产业在预期成长趋缓、产能扩充受限、制程微缩接近极限等考量之下,超越摩尔定律,让元件朝垂直方向整合,就变成追求的目标。
所谓的「三维(3D)整合」在形成多层的主动元件时产生许多不同的方法,这里或许可以简单地以制作顺序区分为循序式(Sequential)与并行式(Parallel)两种。前者意指上、下层主动元件的形成是在同一晶片上循序渐进,层层累积;后者则意指上、下层主动元件的形成是各属不同晶片分别并行,片片堆叠。它们的差异可以用上、下层主动元件的垂直距离加以区别--循序式三维整合的垂直距离小于1微米(μm),并行式三维整合的垂直距离通常大于10微米。
循序式三维整合是单晶同质整合,因此追求装填密度的提升若非唯一也会是它最大的诉求。并行式三维整合允许不同的制程与技术节点的晶片堆叠,可以将各自的优点结合,也就是异质整合。异质整合依技术与设备到位的情况来看,由前段制程提供者(如晶圆代工厂)向后延伸,因为可以主动地开发载具,比较容易获得进展。由后段制程提供者(如封装测试厂)向前延伸,因为普遍缺乏设计能力,只能被动地取得载具,因此需要较长时间发展。
DRAM核心的记忆单元将储存电容器(Storage Capacitor)堆叠在存取电晶体(Access Transistor)之上,早已在同一晶片上朝垂直方向整合主动元件(电晶体)与被动元件(电容器),因此几乎都采取并行式三维整合,藉由晶片堆叠增加容量或频宽。混合记忆体立方(Hybrid Memory Cube, HMC)就是这种新型态利基型DRAM的一个范例。
[@B].利基型3D DRAM典范—HMC[@C] .利基型3D DRAM典范—HMC
HMC是DRAM与逻辑晶片的异质整合,以矽穿孔垂直连线,以微凸块(Micro Bump)接合,堆叠四或八颗做为资料储存的DRAM晶片在一颗做为管理与介面的逻辑晶片之上。它的进展是由美光主导,如图2所示:首先藉着第一代原型产品的概念验证,并且在2011年9月英特尔科技论坛(Intel Developer Forum)展示,引起广泛的注意;之后成立联盟共同发展,公布第二代量产产品的规格书,开始试产与送样;然后再有联盟成员的厂商配合以现有产品做系统呈现或未来产品做规画。
图2 DRAM晶片堆叠过去3年的发展
.标准型DRAM堆叠遇瓶颈
标准型DRAM晶片堆叠,特别是第三代双倍资料率记忆体(DDR3),从2010年开始就有厂商陆续宣示已经准备就绪,但是进展却远不如利基型DRAM顺遂。其中一个原因,可能是因为对效能的提升通常与下世代产品预期相符,例如DDR3到DDR4。在成本、技术、产业链等考量下,客户宁可等待下世代产品,也不愿冒险使用。因此有些人认为标准型DRAM晶片堆叠也许要在现在DDR世代结束之后才会开始。
行动型DRAM使用的一种宽输出/入(Wide I/O)架构,系将四条独立的128位元200Mbit/s通道置于单一晶片上,并可以透过并行式三维整合堆叠至多四颗晶片,提高记忆容量。固态技术协会(JEDEC)在2011年9月28日颁布MO-305产品轮廓,2012年1月5日颁布JESD229规格书,确实将此一架构与介面标准化,但在少数实际产品应用却出现无法与JEDEC标准相容的介面,如图3所示。因为在系统上异质整合须要求DRAM晶片与逻辑晶片更密切的结合,前段的设计、制造与后段的封装与测试技术变得环环相扣,这些需求其实都与客制化无异,标准化扮演的角色似乎也随着DRAM产业整并而越来越弱。
图3 三星 Wide I/O DRAM与JEDEC规范的微凸块分配的差异
DRAM的发展趋势--大频宽、高能效
DRAM的发展可以从过去其资料传输的尖峰频宽,与传输每位元所需要的能源效率的改变观察(图4)。随着产品世代的更迭,DRAM为了符合效能需求提供更大的尖峰频宽,同时也提高能源效率以维持功率中立(Power Neutrality)。行动型DRAM的功率大约1瓦(W),绘图型DRAM的功率大约4瓦,高效能计算(High-performance Computing, HPC)用DRAM的功率则是15瓦或更大。可以预期这个趋势将继续,JEDEC商定中的Wide I/O 2与高频宽记忆体(High Bandwidth Memory, HBM)基本上都在这个能源效率挤压在小于5pJ/b的设计空间探索,使得传统的DRAM架构逐渐难以应付。
图4 DRAM频宽增加与能效提升趋势分析
只在意核心通量(Core Throughput)的设计,会将输出/入位元数与资料传送率当做折衷的参数,输出/入埠越宽或资料传送率越高,都将增加功率消耗与晶片面积。为了维持功率中立,就要减少输出/入电容、摆幅与资料转变,异质整合的晶片堆叠就有这些益处。
另一方面,过去20年间DRAM核心阵列的传播时延,受限于列线的RC时间常数,平均每年只减少不到5%。图5显示Wide I/O DRAM的列周期时间(Row Cycle Time, tRC),相较于各个DDR世代,并未出现太大的改变。随机列周期时间决定存取DRAM的潜伏(Latency),是记忆体阶层设计的重要参数。
图5 Wide I/O DRAM与不同DDR世代的列周期时间比较
处理器晶片内嵌的最后一层快取记忆体(Last Level Cache, LLC),通常在记忆体阶层的第二或第三层,与外置的做为主记忆体的DRAM,不论是延迟或容量,在比值上都有明显的差异(图6)。换言之,大部分的资料被存放在速度很慢的主记忆体,这就是记忆墙(Memory Wall)的表征。近来处理器的核心数迅速增加,它们之间存在的鸿沟也越来越大。
图6 存在目前记忆体阶层的延迟时间与储存容量鸿沟
以英特尔(Intel)的处理器为例,在短短的3年内,其最大核心数从8上升至15,因此再插入一层以分立DRAM晶片做成的快取记忆体似乎可行。这个新的快取DRAM的延迟约在10~25奈秒(ns),每核平均分配的容量约在16~512百万位元组,同样地在异质整合的晶片堆叠也能派得上用场。
