- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
畅谈20 nm技术发展前景
录入:edatop.com 点击:
在一类产品发售之前,还没有一种半导体工艺像20 nm节点这样引起这么大的争议。争论在于,节点是否应该等待即将投产的EUV光刻法。它并没有:双模式的布板虽然昂贵而且有局限,但是满足了高分辨率掩膜层的需求。
在节点是否需要finFET晶体管上也有争论。Intel、IBM和UMC持赞成态度;三星、TSMC和GLOBALFOUNDRIES则反对。TSMC以前曾有些模棱两可,推进了16 nm finFET半节点计划。而影响最大的是,NVIDIA CEO Jen-Hsun Huang公开质疑整个20 nm节点的经济可行性,他认为,每个晶体管的成本永远不可能低于28 nm。
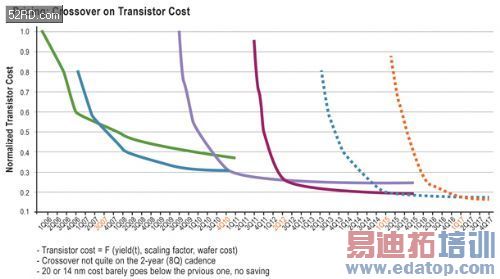
注释:数据基于NVIDIA的公开数
虽然有争论,但是,TSMC发布了其20 nm参考流程。已经着手开始芯片设计。客户已经开始试用测试硅片。现在需要提出的问题是,20 nm芯片系统(SoC)产品代对于系统供应商意味着什么。这一节点也仅仅只是摩尔定律发展的另一个台阶吗?对于SoC用户,它会带来很大的新挑战吗?有没有隐藏的风险?为找到答案,我们与20 nm硅片工程师进行了交流,查阅了最近的会议论文。
非常具有挑战性的工艺
20 nm节点的争论在于它非常难以进行投产,技术挑战还仅仅是一个小问题。但是,从系统设计人员的角度看,使用SoC而不是开发它,所有的都可以归结为5个关键点:成本、密度、速度、功耗和2.5D。系统设计人员的体验在很大程度上取决于芯片设计人员怎样处理好这5个关键点的相互关系。
成本是最主要的。NVIDIA的Huang先生的观点可能是正确的:随着成本的大幅攀升,对于同样数量的晶体管,20 nm一直要比28 nm昂贵得多。对于采用了大量非线性电路的SoC,例如,RF或者其他模拟晶体管,单片无源组件,以及静电放电保护结构等,成本差距要比仅采用高密度逻辑的SoC大得多。非常简单的是,对于SoC移植到20 nm,应该有一些优点——集成、性能、能效,以及IP应用等,要优于28 nm。否则,无法弥补额外的高成本。
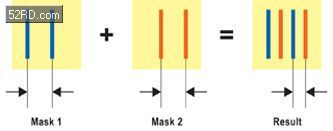
这就给我们带来了密度问题:在同样面积上,20 nm能否尽早完成工艺转换。与28 nm相比,由于模板相关的设计规则导致降低了封装效率,除此之外,20 nm每mm2的晶体管数量是其两倍。芯片规划人员通过几种方法来使用越来越多的晶体管。
最明显的方法是集成。如果您能够将两个28 nm SoC封装到一个20 nm管芯中,结果是减小了芯片间延时,降低了I/O功耗,以及电路板级成本,这说明单位晶体管成本的提高是有好处的。而不明显的是,规划人员通过使用晶体管来提高性能或者能效。
一个非常简单的例子:如果一片SoC在主要工作模式上是DRAM受限的,有时候扩大片内RAM能够有效地减少对DRAM的访问,这样能够极大地提高性能,大幅度降低I/O功耗。而晶体管更典型的应用是建立并行机制。在有大量线程、数据并行或者可以进行流水线工作的应用中,增加处理器要比提高时钟频率更有效。这一事实导致了从单核发展到多核SoC,在20 nm,将推动从多核到很多核的发展。
可能有些令人吃惊的是,晶体管问题也影响了模拟电路性能。例如,FPGA供应商Altera宣布,其28 nm工艺代芯片至芯片收发器最大速率从28 Gbps增加到20 nm FPGA的40 Gbps。这种增长的部分原因当然是来自更高的晶体管ft,以及杂散干扰的减小。Altera工程师说,而主要原因是更快、更复杂的数字均衡电路。此外,在很多其他应用中,与20 nm相比,设计人员能够使用更多的晶体管,通过数字化来增强模拟信号通路的性能。
增加晶体管也能够降低功耗,但这听起来可能有些相互矛盾。一个例子是,设计人员在20 nm继续采用了复杂的功耗管理策略。使用精细的状态机和控制电路,设计人员的时钟选通和电源选通策略的粒度更精细。当无法改变进入寄存器的数据时,常用的方法是减小周期时钟。当整个子系统空闲时,电源选通一般只用在模块级,而现在对于粒度越来越精细的结构,随着周期的缩短,更多的采用了电源选通。更精细的粒度增加了晶体管开销,但是,只要能够降低功耗,很多设计人员还是会做出这种选择。
更明显的例子是ARM的big.LITTLE体系结构。除了主Cortex-A15,这一方法增加了第二个完整的CPU——Cortex-A7。当一个任务需要高性能时,系统启动A15。当系统要处理的任务对性能要求不高时,它关断A15,在功耗较低的A7上运行不关键的任务。结果是,大幅度降低了功耗,而且没有牺牲最大性能。
消除难点
通过使用晶体管来提高性能在20 nm SoC是非常关键的,原因在于:在模块级,20 nm芯片并不比相应的28 nm快很多。从公开的信息看,这还不是很明显。例如,TSMC宣称,其20 nm技术“…速度比28 nm技术高出30%…。”这并没有达到我们工艺代之间翻倍的预期,但并不说明这不重要。在整个模块上实现这么高的速率而不是在几个关键通路上,那么,可能会需要大量使用低Vt晶体管,而且有很大的泄漏电流,带来了更大的本地散热问题。即使没有散热问题,设计也很难在20 nm很多工艺、电压和温度角上达到时序收敛。一些工程师建议,考虑到功耗和其他变化因素,只是把模块导入到20 nm可能根本无法提高速率。
在20 nm更复杂的另一个问题是功耗。动态功耗——CV2f类,在原理上应该低于20 nm电路,前提条件是,尺寸更小的特性降低了杂散电容,工作电压保持不变,频率与28 nm的相似。虽然每个晶体管的动态功耗降低了,但是,平面工艺中,由于泄漏电流导致的静态功耗在不断增加。理论上,同样的Vt,finFET的亚阈值泄漏电流要比平面晶体管低得多,减小了单组件的最大泄漏。因此,采用finFET工艺,设计人员可以使用与28 nm相似的Vt和Vcc,同时提高了性能,降低了静态功耗,或者使用较低的Vt,支持更低的Vcc,同时降低了动态和静态功耗。最好的选择取决于电路以及最终系统的应用情况。
使用或者不使用finFET,功耗都是问题。静态和动态功耗之和不会像28 nm那样简单的加起来。而密度增加了两倍。计算表明,功耗密度,也就是本地散热,限制了某些20 nm模块的布板和时钟频率。
最后,是2.5D。20 nm工艺本质上更适合制造2.5D封装所需要的硅片直通孔(TSV)。时机上巧合的是,代工线在20 nm工艺节点开发他们的产品TSV技术。结果是,在20 nm工艺代,我们可能会看到大规模使用TSV来连接多个管芯的有源电路和无源硅片基底。
这一技术的前景非常广阔。对于面积或者焊盘受限的管芯,2.5D封装大幅度提高了资源利用率。通过采用封装内宽字I/O替换DDR3,极大的提高了DRAM带宽。它能够在一个很小的引脚布局中集成无法在一个管芯中制造实现的各种技术。但是,从技术和商业角度看,问题也很明显。
系统设计人员的观点
这对于系统设计人员而言意味着什么?首先,并不是所有的SoC产品线能够自动移植到20 nm。最早应用的器件晶体管数量加倍,能够有效的提高系统性能,降低功耗和成本。早期应用的例子包括,多核服务器CPU、CPU/GPU组合芯片、高端FPGA,以及某些ASIC SoC——可能会从移动市场开始。
其次,是可能会大量使用多处理任务的芯片。对于使用芯片供应商提供的完整参考设计的系统设计团队而言,可能体会不到这一点。正如我们在另一篇文章中所讨论的,如果设计团队涉及到编写应用程序代码、布线中断、管理DRAM数据流,或者对实时行为建模等,这可能会是很大的问题。
对于系统设计人员,更明显的是,这些芯片需要大量的功耗管理工作。芯片设计人员会用尽所有的方法来解决功耗以及工艺变化带来的问题,包括动态电压频率调整、动态电源选通,以及自适应电压调整等方法。对于系统设计人员,所有这些方法都很重要。更特别的是,他们能够完善电源网络设计,前两项会在实时行为分析中引入可变或者非确定性延时。
总之,20 nm会延续摩尔定律在集成上发展趋势,但是要付出成本代价。2.5D封装技术的发展,进一步提高了集成度,但是也增大了成本,部分解决了DRAM总线电源和带宽问题,在一个封装中集成了种类更多的IC。随着系统性能的提高,这一节点也增加了体系结构的复杂度。目前为止,它也是功耗管理最复杂的节点。
作者:Ron Wilson
