- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
从ANSI/ISO标准C语言自动化产生具有直接记忆体存取功能的硬件加速器
录入:edatop.com 点击:
从C/C++架构的语言来合成独立式硬件模组的法则,已经获得嵌入式系统设计的採用,也已经成为增进效能、复杂度与及时上市需求的必要方式,然而使用C语言来产生独立式区块,并无法真正无缝式地结合嵌入式软件与硬件发展流程。
简介
在摩尔定律发表的四十年之后,摩尔定律持续地以低成本提供设计师更高的容量,让系统可以有更大的尺寸与复杂度。设计师企图想要使用暂存器转化层(Register-Transfer-Level;RTL)的硬件描述语言这种传统的方式来建构电路,但是想要实行这样规模的系统已经变得越来越具有挑战性。这个问题常被称为"设计落差"-在元件密度与开发者生产力之间的差异,由于当前摩尔定律的快速发展,已经在设计工具与法则上大幅超前旧有的技术,落差正逐渐在加大之中。
支援的工具
在这篇文章中描述的方法,相当仰赖用于整合联结处理器与硬件加速器,以及在整个嵌入式系统中所有其他週边装置的工具链,这个章节将提供一些关于这些工具的背景资讯,在后续的章节中将会更深入地讨论他们在支援C2H编译器上所扮演的角色。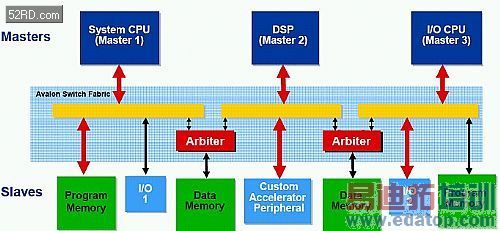
图1. Avalon交换架构在系统中连接主控埠与从属埠
设计流程
C2H的设计流程开始于在软件IDE中的C/C++专案、包含已经写好以供进行加速的ANSI C功能,或在既有的程式码找出瓶颈所在,并选择以进行加速。处理流程如下所示:
1 在软件IDE中进行原型与除错设计。
2 在IDE中为所选择目标进行加速功能。
3 在加速的功能上执行C2H分析,以产生包含有所使用的资源、效能资讯、C2H无法进行最佳化的部份程式码警告,以及关键的资料路径(像是在两个指标器之间做为输入参数的迴路承载附属)等细节报告档案。这个过程将依据功能的复杂度,以及一般软件编译的顺序,大约耗费数秒到几分钟的时间。
4 最佳化与叠代运算。
5 启用IDE选项以产生更新的元件程式档,执行系统产生工具来为整个系统产生逻辑,并在设计中执行合成与佈局佈线。
6 编程硬件影像档到元件中。
7 执行软件专案来确认效能,目前是使用在IDE中的硬件加速器。
这个设计流程描绘了使用者从软件IDE驱动整个软件/硬件分割过程的能力,连接硬件区块到系统的实行细节,以及与处理器、记忆体与其他週边通信以进行萃取的过程。
图2. C2H整合硬件编译过程到软上的建构流程之中
连接加速器介面到处理器
每个加速器都有从属埠,担任其与主要处理器之间的控制介面,从属埠包含一个START位元,以及STATUS位元,它也有一个暂存器库用来储存加速功能输入参数时的接受值,如果功能回覆一个数值,从属埠包含的唯读暂存器便会将数值保存起来。因为硬件模组是SOPC Builder的零组件,处理器可以在自己的所在位置上,轻易地存取这些暂存器,进行读取与写入的操作。图3显示在一个简易系统中,处理器主控加速器来控制从属埠。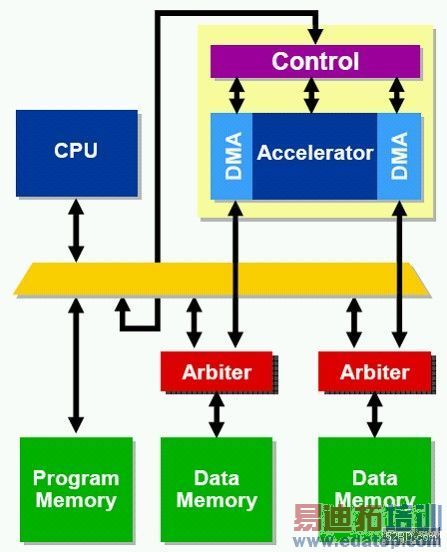
图3. 连接加速器介面到处理器与系统记忆体
直接记忆体存取
想要完整、精緻的C语言到闸阵列解决方案,管理指标器是其中一项最令人畏惧的挑战。在软件中,指标器与间接(indirection)操作可以很明确地定义,每个变数都可以被宣告(静态或动态)一个位址,并可解除指标器的管制使其不仅可在它们的位址上进行载入或储存操作。不过在独立式的硬件区块之中,定义将会变的模煳不清,在此没有原本的位址空间,且单个变数可以被映射到许多不同的暂存器中,并透过流水线与预测性运作来传送。根据在1999年De Micheli的说明,转换到硬件架构有其困难之处,在这个领域的许多研究者都避免使用指标器,以减少对程式语言的约束[7]。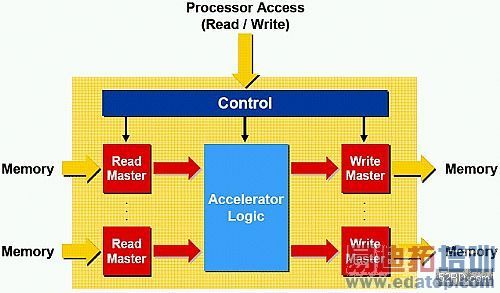
图4. 加速器主控埠(并控制从属埠)
加速器编译流程
C2H编译器以四个主要的阶段运作:(1) 控制/资料流图形分析;(2) 指标器分析;(3) 排程与流水线;以及 (4) 产生HDL。在这个章节中会对每个阶段进行讨论。
图5. 读取操作的延迟时间察觉排程为两个週期的延迟

图6. 迴路叠代流水线会隐藏记忆体读取操作的延迟时间
结果
想要测试C2H编译器的效果,一些嵌入式软件/硬件工程师会提供一些在嵌入式运算中常见的演算法,他们的目标是在进行8-24个小时除错与最佳化之后,尽可能达到最佳的效能。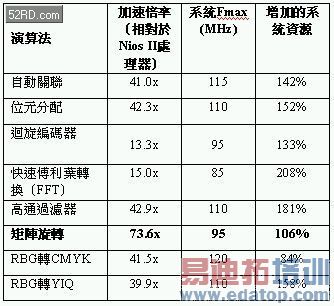
表1 使用者的测试结果
结论
在这篇文章中,我们描述了转换ANSI/ISO标准C语言功能到客制化硬件加速器的方法,它与一般用途的软式处理器紧密结合,当以处理器整合式开发环境的外挂程式来执行时,可将软件与硬件的设计流程结合在一起,并允许进行快速地除错与最佳化叠代的过程。
这篇文章将描述紧密地与软式RISC处理器、工具链与记忆体系统相结合,以产生硬件加速器模组的方法,这种组合拥有以下几点显着的进展:
(1) 具备真正的在原始软件与硬件加速实行之间,进行按钮式切换的整体开发环境;
(2) 从加速器模组中直接存取到记忆体;
(3) 完全支援指标器与阵列;
(4) 记忆体处理的延迟时间察觉流水线技术。
本文也将讲述实行的成果─C2H编译器,在几天内共有八个常见嵌入式应用的使用者测试案例中,显示达到了13~73倍的加速效果。
简介
在摩尔定律发表的四十年之后,摩尔定律持续地以低成本提供设计师更高的容量,让系统可以有更大的尺寸与复杂度。设计师企图想要使用暂存器转化层(Register-Transfer-Level;RTL)的硬件描述语言这种传统的方式来建构电路,但是想要实行这样规模的系统已经变得越来越具有挑战性。这个问题常被称为"设计落差"-在元件密度与开发者生产力之间的差异,由于当前摩尔定律的快速发展,已经在设计工具与法则上大幅超前旧有的技术,落差正逐渐在加大之中。
然而,新的元件日渐提高的容量与效能,允许着更高层次能力的提升,设计师不再能接受停留在低层次的电路实行细节,EDA(电子设计自动化)产业也感受到这个需求,从高层次语言来进行逻辑合成所需的许多工具与法则,在过去的十年间逐渐出现,企图满足设计师的各项需求。
其中一个引人注目的早期法则(Page与Luk)使用occam程式语言做为设计输入的方法,主要是因为它是由指定的顺序式与平行方程式列表的评估方式所组成[13],虽然它的作者具备前瞻性的想法,occam可以被用在传统微处理器与FPGA的辅助运算器进行无缝式软件开发,occam仍然主要用于密集平行运算的应用中,是较少为人知的语言。
因为考量简单性与普遍性,产业与研发组织选择C程式语言做为设计输入的基础,大量的C语言与硬件合成法则已经使用了超过15年的时间。Page与Luk的解决方案逐渐发展为Handel-C,这是一种具备类似occam描述平行机制延伸的C语言子集(subset)[5],Catapult C则使用了结合C++的子集[11],Impulse C延伸了具备形式、功能与函式库的语言[14]。SystemC用等级函式库来提供硬体导向的组成,进一步扩大了C++语言[12]。Transmogrifier C则限制了语言并在位元层级的形式上增加了一个延伸[8]。除此之外还有许多这类的语言出现。
传统上,C语言到闸极的法则一直在寻找能够解决产生独立硬件模组问题的方法,我们透过非常不同的方式产生辅助运算器来卸载与增强微处理器在执行以C语言撰写软件的效能,这个方法解决了几个重要的问题:(1)紧密地整合软件设计流程,包括对关键的运算原型,或已经在传统的微处理器或数字信号处理器(DSP)上执行的C语言,进行真正的按钮式加速;(2)直接连接所产生的硬件加速器到处理器的记忆体映射中;(3)无缝式地支援指标器与阵列;(4)效率极高的延迟时间察觉排程与记忆体处理流水线。
这个法则的实行所支援的相关工具,这将会在这篇文章中进行说明。Altera的C语言到硬件加速编译器(C-to-Hardware Acceleration Compiler;C2H)是从纯正的ANSI/ISO标准C语言功能所衍生而来,它可直接存取在处理器系统中的记忆体与其他週边的硬件加速器。它使用既有的商用系统整合工具,来连接加速器与系统中任何其他的週边装置到处理器上。它可让加速器与处理器同样地直接存取到记忆体映射,当从软体转移到硬件时,则允许无缝式地支援指标器与阵列。
C2H编译器的控制核心是处理器的整合式软件开发环境,透过支援指标器与尚未延展的ANSI/ISO C语言,C2H允许开发者快速地在处理器上执行软件,以进行功能的原型设计,然后只需按下一个按钮,便可以切换到採用硬件加速功能来实现。
着名的分析师发现到在EDA产业中的最大问题,便是硬件与软件设计流程之间并不相容[9],Altera的方法可在一个语言与一个环境之下,透过启用嵌入式软件与嵌入式硬件的发展,不再需要在硬件/软件管理上妥协,解决了上述的问题。
在下个章节中,我们将提供关于支援C2H编译器一些工具的背景资讯,在第3-5节中将会讨论架构的议题:设计流程、连接到处理器的介面,以及直接记忆体存取。第6节中将描述编译流程,包括延迟察觉排程与流水线技术。最后,在第7节中将会展现使用者测试的成果,并在第8节中做总结。
支援的工具
在这篇文章中描述的方法,相当仰赖用于整合联结处理器与硬件加速器,以及在整个嵌入式系统中所有其他週边装置的工具链,这个章节将提供一些关于这些工具的背景资讯,在后续的章节中将会更深入地讨论他们在支援C2H编译器上所扮演的角色。
2.1 系统整合
C2H编译器使用SOPC Builder这个系统整合工具,它可允许设计师在图形使用者介面中,指派与连接像是处理器、记忆体与週边这些零组件。依据零组件列表与连接矩阵,SOPC Builder可以为系统中所有的零组件输出HDL,而且是包括自动产生互联与仲裁逻辑的高阶HDL设计档案[1],它也可以自动产生设置ModelSim的专案、脚本与测试台(testbench)。
SOPC Builder允许它的零组件函式库延伸具备客制化的使用者零组件,C2H加速器可以客制化、自动产生可以自动插入与连接到系统的SOPC Builder零组件。当系统产生HDL时,加速器便像其他系统零组件一样地连接起来,使用可编程产生的系统互联架构来连结系统。
2.2 系统互联
Avalon交换架构是用来收集连接零组件到记忆体映射暂存器系统的信号与逻辑,它的功能类似传统的共享系统匯流排,但其使用动态产生的线路、暂存器与从属埠仲裁器来替代,以增进系统的效能。透过Avalon主控与从属埠来连接到系统的零组件介面,结合由SOPC Builder所维护的主从架构连线矩阵,将整个系统互联整合起来。
任何主控或从属埠可以有一个连接的专属编号,举例来说,处理器的主控埠在系统中连接了八个从属装置,全部属于不同的记忆体与週边模组。同样地,在记忆体模组的从属埠也可以透过两个处理器、一个直接记忆体存取(DMA),以及两个硬件加速器来进行主控。Avalon交换架构可透过从属埠的仲裁,来同步地多重主控管理这些连线,它在每个从属埠的前方插入仲裁模组,来从不同的主控埠管理需求,并从主控埠萃取系统的互联细节,在从属埠中也是採用相同的作法[2]。图1显示Avalon交换架构在系统中连接多重的从属与主控埠。
C2H利用了Avalon的精密功能组,包括位址解码、资料路径多路传输、等待状态插入、流水线、动态匯流排大小、从同步多重主控埠进行仲裁、强化管理、时钟领域跨越与晶片外介面等。
图1. Avalon交换架构在系统中连接主控埠与从属埠
主控埠
系统处理器(主控埠1)
数字信号处理器(主控埠2)
I/O处理器(主控埠3)
Avalon交换架构
仲裁者
仲裁者
从属埠
程式记忆体
输入/输出1
资料记忆体
客制化加速週边
资料记忆体
输入/输出2
程式记忆体
2.3 软式RISC处理器
C2H编译器整合了Nios II产品系列的软式嵌入微处理器,它是一种具有完整32位元指令集、资料路径与定址空间的一般用途RISC架构,能够以高达225 DMIPS的效能来执行[3]。
C2H加速器是一种辅助运算器,可以完全整合到Nios II与整个软件工具链之中。其中一个重要的区分必须在此说明-C2H加速器不是客制化指令(虽然处理器完全支援客制化指令功能)。客制化指令延伸了处理器的运算逻辑单元,可接受两个数量运算域,并回传一个数量值。C2H加速器是一个完整的辅助运算器,可以接受无限制的参数数量(可以是数值、阵列、结构等,传出数值或参考值),并具备运用系统中的记忆体与其他週边的能力,虽然它是用来从C语言描述来自动地产生客制化指令的理想建构工具,但在所选择的法则中,它在整体效能上可增进的范围与潜力比客制化指令还要大的更多。
虽然我们所实行的这个法则目前仅支援Nios II,但它其实并不专属于某个处理器,它可以套用在其他的环境,并整合到另一个微处理器的软件发展流程之中。无论如何,处理器採用Eclipse架构的IDE(整合发展环境),并与SOPC Builder整合,可以极方便地延伸产生硬件辅助运算器。
设计流程
C2H的设计流程开始于在软件IDE中的C/C++专案、包含已经写好以供进行加速的ANSI C功能,或在既有的程式码找出瓶颈所在,并选择以进行加速。处理流程如下所示:
1 在软件IDE中进行原型与除错设计。
2 在IDE中为所选择目标进行加速功能。
3 在加速的功能上执行C2H分析,以产生包含有所使用的资源、效能资讯、C2H无法进行最佳化的部份程式码警告,以及关键的资料路径(像是在两个指标器之间做为输入参数的迴路承载附属)等细节报告档案。这个过程将依据功能的复杂度,以及一般软件编译的顺序,大约耗费数秒到几分钟的时间。
4 最佳化与叠代运算。
5 启用IDE选项以产生更新的元件程式档,执行系统产生工具来为整个系统产生逻辑,并在设计中执行合成与佈局佈线。
6 编程硬件影像档到元件中。
7 执行软件专案来确认效能,目前是使用在IDE中的硬件加速器。
这个设计流程描绘了使用者从软件IDE驱动整个软件/硬件分割过程的能力,连接硬件区块到系统的实行细节,以及与处理器、记忆体与其他週边通信以进行萃取的过程。
此外,因为在软件与硬件开发中使用了相同的ANSI/ISO C语言,因此使用者可以随时切换到软件中来执行功能,快速地分析以进行加速,并执行完整的流程来产生更新的硬件影像档。这可提供使用者工具来快速地重复进行除错与最佳化功能,而不需经歷长时间进行合成与佈局所造成的延迟。
图2. C2H整合硬件编译过程到软上的建构流程之中
main.c
accelerator.c
软件
硬件
C处理器
语法分析
C2H编译器
系统描述
accelerator_driver.c
accelerator.v
系统产生器
C编译器
系统模组HDL
main.o
accelerator.o
accelerator_driver.o
否
是
使用者设定:使用加速器来替代原有的软件吗?
链结器
合成、佈局/佈线
二进位可执行档
元件编程档案
图2显示了C2H编译器如何在IDE中整合到软件建构流程之中,左半边的流程图显示了main.c与accelerator.c的标准C语言编译过程,它会未经过加速来执行。右半边的流程图显示当accelerator.c的功能被C2H加速启动的硬件编译流程,它也显示出产生与选择加速器驱动程式的链结(将在以下的章节中讨论)到可执行档之中。当原型与最佳化加速器时,开发者不需要执行这个完整流程,在IDE中允许在以下的选项之间切换:(1) 只有软件建构过程,(2) 软件 + C2H 分析/报告,以及(3) 软件 + 完整的硬件(如流程图所示)。这便可允许在开发的前期阶段,进行快速除错与最佳化叠代,也可在最后阶段期间自动地整合整个硬件流程。
连接加速器介面到处理器
每个加速器都有从属埠,担任其与主要处理器之间的控制介面,从属埠包含一个START位元,以及STATUS位元,它也有一个暂存器库用来储存加速功能输入参数时的接受值,如果功能回覆一个数值,从属埠包含的唯读暂存器便会将数值保存起来。因为硬件模组是SOPC Builder的零组件,处理器可以在自己的所在位置上,轻易地存取这些暂存器,进行读取与写入的操作。图3显示在一个简易系统中,处理器主控加速器来控制从属埠。
对每个加速器而言,C2H编译器放出与具有相同特征的同一功能C语言驱动程式,这个驱动程式会编绎这个功能的原始码到软件专案之中,链结器会依据使用者在硬件中是否有选择要执行这个功能,来选择相对映的功能定义。这个过程完全自动化,使用者只需建立专案,然后工具链便会依据使用者的设定来处理。在此有两种加速器运作模式:投入(polled)与中断(interrupt)驱动,如果使用者指定使用投入模式,则驱动程式会由以下四个运作所组成:
1. 载入输入参数到加速器的暂存器库中。
2. 设定START位元。
3. 投入STATUS位元直到硬件信号传送完毕。
4. 读取回覆的值并退出。
图3. 连接加速器介面到处理器与系统记忆体
控制
处理器
DMA(直接记忆体存取)
加速器
DMA(直接记忆体存取)
仲裁器
仲裁器
程式记忆体
资料记忆体
资料记忆体
如果功能只是用软件来执行,在驱动程式功能退出之后,随后处理器便会回復程式的执行。
如果使用者指定为中断模式,初始与启动加速器的过程仍然相同,但是投入迴路与所取得的回覆值将会被移除。编译器会在完毕之后增加硬件中断埠到加速器中,并发出包含有对这个功能进行清除中断与读取回覆值的巨集程式的档头,使用这些巨集程式时,设计师可以写入中断服务副程式,以允许处理器同步运作并结合硬件加速器。此外,硬件也可以被整合,以便用于即时作业系统之中。
直接记忆体存取
想要完整、精緻的C语言到闸阵列解决方案,管理指标器是其中一项最令人畏惧的挑战。在软件中,指标器与间接(indirection)操作可以很明确地定义,每个变数都可以被宣告(静态或动态)一个位址,并可解除指标器的管制使其不仅可在它们的位址上进行载入或储存操作。不过在独立式的硬件区块之中,定义将会变的模煳不清,在此没有原本的位址空间,且单个变数可以被映射到许多不同的暂存器中,并透过流水线与预测性运作来传送。根据在1999年De Micheli的说明,转换到硬件架构有其困难之处,在这个领域的许多研究者都避免使用指标器,以减少对程式语言的约束[7]。
由于在支援指标器上的限制,程式语言的效用便大幅的降低,大多数重要的演算法都会使用阵列与指标器来运作在记忆体上的资料结构,这迫使了使用者必须花费时间去修改原始码,使其成为不使用任何未支援结构的可接受格式。
为了让指标器运作更有意义,并可无缝地转移为硬件,加速功能必须与使用软年来执行时存取同一个记忆体映射,此外,在加速器与处理器以及系统的週边之间,能够轻易地进行资料转换也是必要的要求。
Callahan、Hauser与Wawrzynek体认出硬件辅助运算器的需求,在使用Garp架构与C语言编译器来进行开发时,必须能够拥有存取处理器记忆体系统的直接路径[4]。他们的解决方案结合了具备能够重新设置硬件的单一MIPS处理器核心,以将其做为加速器使用。可设置的硬件拥有四个记忆体匯流排,其中一个做为随机存取之用,另外三个则供作循序存取之用,所有硬件都共享一个位址匯流排。这些匯流排可以透过快取记忆体来存取到主处理器的记忆体,但有一个限制便是每个週期只能有一个随机性要求,此外,可重新设置硬件仅在被允许进行控制时才会主控匯流排,这意味着当加速器执行时处理器将无法执行作业。
这篇文章所展现的解决方案在进出处理器的频宽利用上并没有约束,当C2H将功能编译成硬件时,它将会为指标器与阵列运算产生Avalon主控埠,也可以存取位于堆叠或堆积中的静态与整体变数的运算。这些主控埠允许存取在系统中的记忆体与其他週边,并且可以完全独立地、平行地运作。当有一个或超过一个主控埠从输入缓冲区存取资料,而另一个写入资料到输出缓冲区时,则都可以在同一个时钟週期下运行。图4显示一个具备多工读取与写入主控埠的加速器。
虽然C2H编译器的初始版本使用强制模式,大致会对每个外部记忆体运作产生一个主控埠,它目前使用指向资讯,而且排列资讯以消除不需要的主控埠。举例来说,如果有两个指标器同时企图存取同一个从属埠,则存取会重新编排顺序,并只会产生一个主控埠。同样地,如果有两个指标器决定相互排除控制路径(像是在分离的区块中的if/else呈述),或是在某种程度上在排列中排除同时执行的方式,则它们将会共享主控埠。
图4. 加速器主控埠(并控制从属埠)
处理器存取(读/写)
控制
记忆体
读取主控埠
加速器逻辑
写入主控埠
记忆体
记忆体
读取主控埠
写入主控埠
记忆体
在储存了关键迴路的分离式从属埠的系统模组中,可使用大型资料结构来达到最佳化加速器效能。在这种方式下,C2H可以使用特定的主控埠来连接每个从属埠,并同步地转换资料。使用嵌入在FPGA架构中的晶片内记忆体区块是一种比较容易达到的方式,可以用手动的方式来例化到系统中,或是在加速功能中宣告一个阵列来进行推论。
加速器编译流程
C2H编译器以四个主要的阶段运作:(1) 控制/资料流图形分析;(2) 指标器分析;(3) 排程与流水线;以及 (4) 产生HDL。在这个章节中会对每个阶段进行讨论。
6.1 控制/资料流图形分析
C2H透过对结构与控制及资料流图形进行分析,来从使用者的原始码萃取出指令层级对应。DFG边缘是使用与Coutinho、Jiang与Luk在2005年所描述的类似方法来进行分析[6],会执行一些编译器的最佳化,包括效能削减、迴路倒转、常数减半、常数增殖与常见的副方程式消除。
6.2 指标器分析
对平行架构的编译器的而言,指标器分析是影响效能最重要的因素。如果不能决定两个指标器的别名,将会牺牲掉大量的效能,因为两个运算必须被强制循序地执行,而不是平行方式,虽然在许多例子中,不可能用静态分析来萃取精确地指向资讯,大多数的指标器在编译时都可以被分解,这是Semeria与De Micheli在1998年所发现的现象[15]。
C2H编译器不会企图解决精确的位置或指标器参考的变数,只是简单地尝试是否要让两个指标器重叠,这个分析是透过对每个指标器运作的位置描述来执行萃取多项式分解,并进行两者之间的比较。如果两个方程式有非零值的常数补偿,则它们将不会重叠。这个分析会以迴路的方式叠代地执行,C2H会採用依序叠代式的流水线操作,因此必须考虑迴路携带边界的问题。
在许多的例子中,这个分析技术可以满足从常见的C程式码中萃取对应的需求,然而,C2H支援两种简单的模式,让开发者可以在他们的加速功能中,对指标器提供额外的资讯。
6.2.1 restrict指标器形式资格修饰词
restrict形式的资格修饰词是在ISO C99规范中发表,并提供使用者可以指示编译器忽略任何牵连到别名的指标器,并对其解除管制。它不是C2H语言的延伸,restrict广被理解为是从memmove所概括出memcpy,传送到memcpy的指标器参数是否会被restrict所保留,则是看指标器常数是否传送到memmove而定。
6.2.2 连接pragma
C2H发表了单一选项式pragma,用于指定在系统中的加速器主控埠与其他从属埠之间的连接。然而,这个pragma是一个位置保存器的更简洁解决方案,这是ISO TR18037技术报告中对C程式语言支援嵌入式处理器的延伸定义[10],这个技术报告提出对系统专用空间资格修饰词的支援,以宣告来连结记忆体空间。我们计划在TR18037获得广泛认同之后,便立即採用这些方法。
6.3 延迟时间察觉排程与流水线
在加速器执行运算是由阶层式有限状态机所控制,状态机是由包含在目标功能中的每个迴路与副程式所产生,因此排程与流水线取决于在阶层内的整理运算,以及根据最佳化的资料流图形来对其指派状态数值。
与其他的C语言到闸极的方法类似,大多数的指派工作会转换为结合逻辑表示的RHS方程式,然后对流水线进行暂存器登录。这个规则有两个例外状况,首先,像是乘法、除法、整体转移与指标器运算等复杂的运算法则,将会萃取到独立的流水线副方程式中,其次,在硬件中所执行的较简易运算,只需简单地用线路操作(像是常数距离转移、常数的AND/OR运算等)则不会登录到暂存器中。
6.3.1 推测执行
当可行时,在控制区块中的运算是採用推测式方式来执行,以及在合併的控制路径上使用他们的条件方程式来进行多工,像是易消失与写入指标器的运算并不能採用推测式执行,且需在条件方程式中依其附属来进行排程。
6.3.2 记忆体延迟时间察觉流水线
当排程指标器运算时需要进行记忆体处理,C2H查询系统的描述以决定连接到从属埠时的读取延迟时间,依据记忆体的延迟,编译器可以对指标器操作增加运算时间,以便当处理器在读取资料以及进行回覆等待时,让其他非依赖式操作能够被评估。
举例来说,请参考以下的功能:
int foo(int *ptr_in,
int x,
int y,
int z)
{
int xy = x * y;
int xy_plus_z = xy + z;
int ptr_data = *ptr_in;
int prod = ptr_data * xy_plus_z;
return prod;
}
假定ptr_in用两个週期的读取延迟来连接到从属埠,当排程这个功能时,C2H编译器会平行地放置xy与xy_plus_z两者在读取操作时的计算结果,因为它在从记忆体读取资料之前便知道延迟将会有两个週期。图5描述了这个范例的附属与状态指派。
图5. 读取操作的延迟时间察觉排程为两个週期的延迟
状态0
状态1
状态2
延迟时间察觉排程与流水线操作是一个强大的功能,如果编译器不想要特定的记忆体延迟,加速器可以在资料尚未马上准备好时便放入流水线中,或是插入固定数量的等待状态,也许它们并不是所有的状况下都会被用到,我们将透过增加编译器可见常数到所连接週边执行行为的方法,几乎可把所有装置的流水线全部清除,以便将记忆体延迟解除。
在编译时间上,有两种记忆体架构的流水线装置方式,将无法预期是否会发生,它们会发生在: (1) 从属埠的延迟时间是变数值,或是 (2) 在加速器要求存取从属埠时,已经有另一个主控埠被允许存取从属埠。在这两种状况下,主控埠的互联架构信号必须等待,并且加速器会装置它的流水线。编译器通常会在以下的状况减少这些安装的形式: (1) 流水线操作的变数延迟是在从属埠上採用了最大量的读取操作,以及(2) 结合主控埠与相对应的排程记忆体操作,存取了同一个从属埠(因此两个加速器主控埠彼此间将无法结束争夺状况)。然而,透过这些最佳化来减少约束,并不是理想的解决方案,如果可能的话,设计师应该在关键的资料结构上放置在自己拥有从属埠模组上设定固定的延迟时间(较低的延迟时间较佳),这将可以最佳化延迟时间察觉排程,并减少在多重主控埠连接到同一个从属埠所造成的瓶颈。
6.3.3 叠代迴路流水线操作
C2H的流水线是透过同时启动允许多重状态的迴路状态机,来依序地执行叠代的迴路,新的叠代迴路可以进入流水线的频率,是由迴路携带附属分析来决定。举例来说,如果运算A发生在迴路的第一个状态,它是依据从前一个叠代迴路中所得到的运算B的结果,然后直到运算B的状态得到合理值时为止,新的叠代将无法再进入流水线。这个分析是在迴路中的运算都已经排程之后才会被执行(指定了状态值),它可能会分离这两个过程,因为状态值的指定与在同一个叠代迴路之间的两个运算附属有关,迴路叠代频率计算则是与不同叠代迴路之间的两个运算附属有关。
图6. 迴路叠代流水线会隐藏记忆体读取操作的延迟时间
时间 叠代0 叠代1 叠代N
(状态0)
(状态1)(清空延迟状态) (状态0)
(状态2) (状态1)(清空延迟状态)
(状态2)
每个迴路叠代是一个週期:记忆体延迟会被迴路流水线所隐藏
(状态0)
(状态1)(清空延迟状态)
(状态2)
迴路叠代流水线操作可以让加速器发佈多重的突出读取操作到延迟的从属埠中,在许多状况下都可以有效率地隐藏记忆体延迟,这将在以下的范例中描绘出来:
int sum_elements (int *list, int len)
{
int i;
int sum = 0;
for (i=0; i<len; i++)
sum += *list++;
}
再一次假设指标器已经用两个週期的读取延迟来连接到从属埠,读取操作将会在状态0的迴路中进行排程,并会在状态2中用sum加总来进行排程,然而,迴路的叠代可以透过每个週期来进入流水线一次,图6显示在这个迴路的多重叠代期间,两个运算的执行状况。在初始化三个时钟週期的延迟已经克服之后,加速器会在每个週期完成一个叠代,假设在迴路执行期间已经装置了加速器的状态机,编译器会在读取主控埠之后产生FIFO(先进先出),并收集进来读取资料值,直到它们被用于后续的操作为止。
6.4 产生HDL
在编译过程的最后阶段,C2H会为资料/控制路径、状态机与Avalon介面连接埠,产生可供合成的Verilog或VHDL。它也会更新具有Avalon介面资讯的SOPC Builder系统描述,并选择性执行系统产生以将硬件加速器连接到其他的模组。
结果
想要测试C2H编译器的效果,一些嵌入式软件/硬件工程师会提供一些在嵌入式运算中常见的演算法,他们的目标是在进行8-24个小时除错与最佳化之后,尽可能达到最佳的效能。
测试的使用者在对他们的C程式码执行最佳化之后,找到他们可以达到的整数加速倍率(3-7倍),像是套用restrict资格修饰词到指标器上,减少迴路携带的附属物,以及尽可能合併控制路径等。这三个技巧大量地增加了C2H编译器可以从目标功能萃取的平行量。
然而,尽管有这些效果绝佳的最佳化过程,但仍有一点限制住了运算速度所带来的效能,这便是资料的可用性。这个问题不再是与运算关系密切,而是与输入/输出密切相关,因为加速器企图在所有储存在处理器资料记忆体的多个资料缓冲区中运作,单一记忆体从属埠的频宽成为了效能的瓶颈。我们的使用者只需要在系统中增加晶片内记忆体缓冲区,并用来储存关键的资料结构,便可以轻易地克服这个限制。同样地,透过使用特定的记忆体模组做为输入与输出缓冲区,也可以让加速器同时地存取多个主控埠,以加快资料串流在缓冲区中进出的速度。
当结合了程式码最佳化技巧来减少附属物,以及移动关键的阵列到特定记忆体缓冲区这两种方法,可以成功地提高加速器的效能,这两种技巧针对两种型态的可能瓶颈-运算与输入/输出,我们的方法可以同时消除这两者的问题: (1) 有效率的排程与流水线操作,也可以针对运算效能得到关键路径的详细报告; (2) 产生特定的主控埠与缓冲区,来增进记忆体的频宽。
然而,并不是所有的演算法则与C语言功能都合适做为硬件加速,平行/推测式运算与迴路流水线是增进效能的两个关键方式,因此,如果演算法(或它的执行方式)做这两件事,便会限制住编译器的能力,然后只会产生较少量的加速成果。举例来说,程式码在分离的控制路径上包含了循序的附属操作(像是复杂的週边服务副程式),在硬件加速过程中将不会得到多大的效益,这些型态的工作比较适合在处理器上执行。相较之下,具有简单控制路径的功能,以及将关键运算与少量的内部迴路紧密结合,在许多叠代中不中断地执行,都是转换为硬件辅助运算器的理想选择,这意味着开发者在导入加速器到设计中时,必须恰当地进行管理软件/硬件之间的妥协,将循序性的工作留给处理器执行,对于重复性运算相当重视的工作则转移到硬件中执行。
表1展现出了在嵌入式运算中,八个常见的演算法在效能与面积上的结果,加速的计算方式是软件在Nios II上执行的整体演算法运算时间,除以在加速器上执行的整体运算时间。系统资源增加将佔用较多的逻辑单元数量,等同于在像是乘法器与记忆体在晶片内硬件区块中的成本,并会显示扩增加速器与缓冲区所需增加的成本。
这个调查结果显示了在一到三个人天的工作之后,採用C2H大幅地增加了13~73倍的效能,大约佔用了一倍到两倍的系统资源,此外,这个实验是在C2H编译器的开发早期阶段,在执行分析与报告功能之前进行,因此可以大幅地缩短设计时间。此外,还有许多最佳化过程可以被实行,因为编译器对资源的应用已经变的更有效率了。
表1 使用者的测试结果
在这个实验中最值得一提的成果是位元内容的矩阵旋转演算法,相较于在Nios II以95 MHz执行要快上73.6倍,若仅测量绝对的运算时间,这个数值将比MPC7447A Power PC在1.4 GHz下执行还要来的更快一些。
结论
在这篇文章中,我们描述了转换ANSI/ISO标准C语言功能到客制化硬件加速器的方法,它与一般用途的软式处理器紧密结合,当以处理器整合式开发环境的外挂程式来执行时,可将软件与硬件的设计流程结合在一起,并允许进行快速地除错与最佳化叠代的过程。
透过运用既有的基础架构来产生系统,我们证明了一种可以无缝式整合加速器到处理器的记忆体映射,以及萃取系统连线细节的方法,依据这次的整合,我们展现了提供完全支援指标器,以及记忆体的延迟时间察觉的流水线操作技巧。
我们也展示了我们实行C2H编译器这个方法的成果,它将会在2006年第二季由Altera推出,透过使用者测试来展现结果,在几个小时内,经过C2H加速之后,已经可以达到两个位数以上的效能增进。(本文作者任职于Altera)
上一篇:EMI滤波器的设计原理
下一篇:节省PCB空间的新一代音频子系统
