- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
硬知识:揭秘手机GPU各指标参数
录入:edatop.com 点击:
打开USC,您会发现用于分析数据并得出结果的是数个ALU流水线。我们并行设置这些流水线,每个USC设置16个流水线。这样设置的原因是,图像呈并行处理,其中多个相关的数据,通常是矢量或像素同时运行。事实上,高级像素着色的属性驱动相关像素是并行的,因此有必要同时运行这些高级像素。
标量SIMD执行和矢量低效
USC的关键属性是按照标量模式处理数据。也就是说对于给定的工作项目,例如一个象素,USC不是在同一时钟周期内的同一独立管道上同时执行红、绿、蓝和透明度的矢量。相反, USC在一个时钟周期内执行一个红色组件,接下来执行蓝色组件,以此类推,直到执行完所有组件。为实现矢量基准单位的峰值吞吐量,标量SIMD单元并行处理多个工作项目。例如,每个时钟周期内处理一个像素的4-wide矢量的峰值吞吐量相当于4-wide 标量SIMD单元,可在每个时钟周期内处理四个像素。
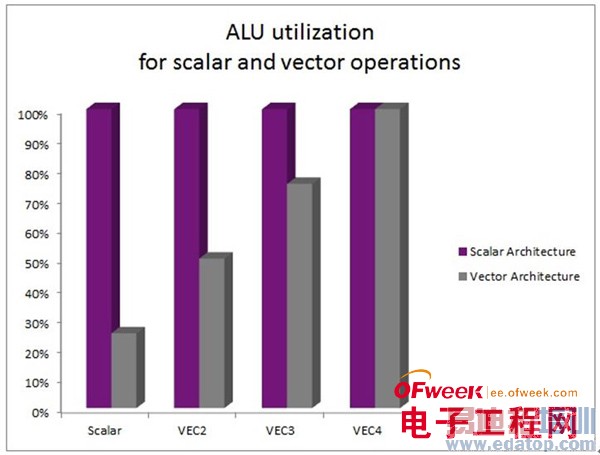
表面上看这两种方法的吞吐量相同。但是,高级GPU负载通常由使用许多不同数据宽度的数据组成。例如,通常颜色数据宽度为4 ( ARGB ),而纹理坐标的数据宽度通常为2 ( UV),还有许多标量实例( 1个组件)处理,如典型的光照计算一样。
在光照计算中,如果数据处理没有填满整个矢量宽度时,就会浪费矢量处理器宝贵的计算资源。在标量架构中,正执行的运算采用一种运算类型,在同一时间运行一个组件,并行处理同一任务。例如着色处理中完全由标量处理组成,在4-wide矢量架构中执行25%的任务,而在标量SIMD架构中本应执行100%的任务。
多个低功耗ALU!
我们再来说说USC并行任务中的独立流水线。共有16个流水线,每个流水线内部实际上存在数个执行任务的ALU。即2个FP32 ALU,2个FP16 ALU,以及1个专用函数ALU 。
为什么使用专用FP16 ALU?主要是为了节省功耗同时也是为了提高性能。与FP32 ALU相比,简化ALU逻辑复杂度可以较低功耗执行FP16指令组,同时可执行更多的运算,在每个时钟周期实现更高的吞吐量。稍后您就会明白。
在高级图像渲染中以较低精度计算可能需要耗费较多时间,而APIs Rogue力求在所有通用图形中支持混合精度运算,其中包括Direct3D 11,以及更常见的OpenGL ES2和ES3 APIs。在嵌入式图形运算中没有构建混合精度计算流水线是个错误,原因是执行混合精度工作量会造成功率放大。
上一篇:华为强悍
逐步瓦解小米优势
下一篇:大事件:华为中兴魅族围剿小米、英特尔深圳解困
