- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
基于DM642的X.264编码器优化
录入:edatop.com 点击:
摘要:X.264编码器注重实效性,在不明显降低编码性能的前提下,降低编码的计算复杂度,摒弃了JM中一些耗时相对较大但对性能的提升影响很小的模块,因此嵌入式系统中常选用X.264编码器。移植到DSP平台的X.264编码器,编码效率不佳,平均只有0.7 f/s。为了能够在DSP平台上进行高效率的鳊码,采用了代码优化以及DM642优化2种优化方式来优化移植到DM642平台的X.264编码器。对优化过后的X.264编码器在DM642平台上进行了实验。实验结果表明,优化过后的X.264编码器对CIF格式视频序列的编码时间大幅度的降低。
关键词:X.264;DM642;软件流水;函数合并;EDMA
0 引言
H.264标准的全称为“H.264/MPEG-4 part 10”,是由ITU-T和ISO/IEC共同成立的联合视频组(Joint Video Team,JVT)制定的新标准。H.264依然采用预测结合变换的混合编码方案,为了在相同的编码框架下得到更高的视频压缩编码性能和更广泛的适用性,H.264标准引入了许多新技术,如1/4,1/8像素精度的运动估计、多参考帧的帧间预测、帧内预测、环路滤波和自适应算术编码等。H.264视频编码标准在编码质量和压缩比上比原有的视频编码标准都有了明显的提高。
在相同的视觉感知质量上,编码效率比之前的编码方式提高了50%。H.264标准的编码性能超越了以往所有的视频编码标准,具有很好的应用前景,大量的应用于视频压缩和视频监控。
目前,H.264编解码标准的研究主要分为算法研究和硬件实现两大类,硬件实现的方案主要分为3种:
(1)基于PC平台的方案。此方案为纯软件实现编解码,利用MMX和SSE/SSE2等多媒体指令集来优化程序,具有开发成本低和周期短等优点。PC机的CPU体系结构并不适合处理数字信号,故CPU的有效利用率比较低。
(2)基于ASIC芯片的纯硬件方案。此方案将视频编解码算法固化成硬件,具有集成度高和开发周期短等优点,但是专用型比较强,产品不易升级。目前市场上已经出现了H.264的编解码芯片,如Fujitsu的MB86H51、Hisilcon的GOALTMHi3510和JVC公司的JCY0237 LSI等。
(3)基于DSP的软硬件结合方案。此方案利用DSP芯片和其它外围芯片来构成处理系统,具有开发灵活性高、处理能力强、开发周期低、功耗低和易升级等优点。随着DSP性价比的不断提高,该方案已经成为目前H.264编码器硬件实现的理想方案。
H.264编解码标准具有压缩比高、适应性广、容错能力强和图像恢复质量高等特点,在实时系统中具有很好的应用前景。TMS320DM642是TI公司推出的一款针对视频和图像处理领域应用的数字多媒体处理芯片,具有处理能力强和集成度高等特点,是目前实现H.264视频编码器的理想芯片之一。很多国内外公司都在开发或已经开发出了基于DM642开发视频监控系统。
1 X.264编码器移植
X.264是由法国巴黎中心学校的中心研究所于2004年6月发起,由许多视频爱好者共同完成的项目,它注重实效性,在不明显降低编码性能的前提下,努力降低编码的计算复杂度,摒弃了JM中一些耗时相对较大但对性能的提升影响很小的模块,如多参考帧、帧间预测中不必要的块模式、CABAC等。X.264编码器在程序结构上,利用了MMX/SSE/SSE2等基于X86构架的多媒体硬件加速指令。需要将相关的X86指令屏蔽,对部分函数进行精简,使其结构简单易于在DSP上执行。简单移植过后的X.264编码器,在DM642平台上的编码效率极低,表1为移植过后的X.264编码器在DM642平台上编码结果。
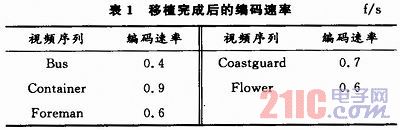
由结果可以看出,移植完成后的X.264在DM642平台上的编码效率非常低,只能达到平均0.6 f/s的编码速率,需要进一步针对X.264编码器和DM642的特性来优化以提高编码效率。
[p]
2 X.264编码器的优化
2.1 编码器参数设置
X.264编码器在VC下的优化使用了一些平台相关的硬件加速指令,所以在VC调试下的X.264编码器参数在DSP平台上执行将对编码速度产生很大的影响。在CCS中优化X.264编码器时,在不影响编码质量的情况下修改部分参数以提高编码的速度。
(1)关闭环路滤波:环路滤波器能使解码图像的主观质量有所提高,但环路滤波器只对提高压缩效率做出很小的贡献。如果采用环路滤波将降低1 ms的编码时间。不使用环路滤波对图像的解压本身没有太大影响,而DSP注重速率的情况下关闭环路滤波可以获得更高的编码速度。表2对有无环路滤波的编码图像的峰值信噪比进行了对比,从表中可以看出环路滤波对编码的质量影响有限。

(2)对P帧使用半像素搜索,不采用1/4像素搜索。表3列出了半像素搜索与1/4像素搜索的时钟周期对比图。从表中可以看到,采用P帧半像素搜索方式对编码速度提升30%以上,并且视觉上解压出来的图像没有明显失真。 [p]
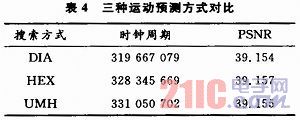
(3)对全像素块运动预测搜索的方式,X.264默认为HEX(正六边形搜索半径为2),在对比测试了DIA(菱形搜索,半径为1)和UMH(可变半径六边形搜索)后,对比了速率和峰值信噪比后,发现在峰值信噪比相差很小的情况下DIA搜索速率最快,本文选择DIA作为运动预测搜索方式。表4给出3种方式的对比结果:
2.2 X.264代码优化
X.264编码器需要有效的利用DM642的特性,如软件流水,芯片特性和指令集等,才能有效的提高X.264编码器在DM642平台的编码效率。为了X.264能够充分的利用起DM642的特性,需要结合DM642本身的特点对移植过后的X.264代码进行优化,才能够提高X.264在DM642上执行的效率。
TI公司的DSP开发软件CCS提供了功能非常强大的编译器,编译工具可以对代码进行各种优化,以提高代码的执行速度,减小代码尺寸。这些优化包括了简化循环、软件流水、语句和表达式的顺序重排和分配变量到寄存器。利用CCS编译器进行优化后,仍然不能满足视频压缩的需求,需要继续对DM642上的X.264编码器进行优化。
(1)内联函数。内联函数是指用函数本身来代替函数调用这一过程。当调用内联函数时,C/C++源代码把此函数插入到调用点,而不采用传统的跳转。将函数设定为内联函数后,可以去掉复杂的函数调用过程来提高函数的执行效率,而付出的代价是增加了代码所占用的空间。使用关键字inline定义内联函数,在X.264编码器中的预测部分对其中一个频繁调用的函数设置为内联。代码如下:
static inline inI clip_uint8(int a)
(2)restrict关键字。为了帮助编译器确定存储器相关性,可以使用关键字restrict来限定指针、引用或数组。使用restrict关键字是为了确保其限定的指针在声明的范围内,是指向特定对象的惟一指针。编译器在读取函数的指针,数据时,采取保守的办法,认为它们是相关的。这时编译出的代码必须执行完前次写操作,才能开始下次读取操作。加入restrict关键字后,编译器将认为指针和数组没有相关性,能够并行提取数据。
(3)软件流水。软件流水式编排循环指令是能够使循环的多次迭代并行执行的技术。编译器总是力争使用软件流水技术。软件流水是DSP的关键技术,它利用的是算法中存在的指令并行性的特点,使一个循环的多次迭代同时进行。总地来说,当使用编译器优化的情况下,代码尺寸小,程序性能更优。x.264代码含有很多循环操作,故提高循环体指令的并行度使循环能够软件流水是提高编码效率的有效途径之一。
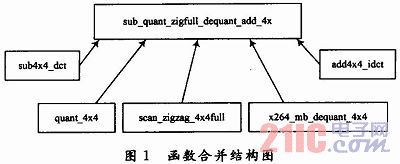
(4)函数合并。函数调用的过程中,要执行一些额外的寄存器。在编码过程中DCT、量化、zigzag、IDCT和反量化函数调用都非常频繁,但代码段都很短,部分代码只包含一个循环操作或者赋值操作。反复的调用会花费大量运行周期在函数调用上。为减少不必要的操作,提高速度,将DCT变换、量化、反量化和反DCT变化的整个过程进行优化,将几个函数合并到一个函数中。图1所示为合并结构。
2.3 DM642的优化
(1)CACHE优化。DM642采用了两级CACHE的存储器结构,两级CACHE主要用于对程序和数据的缓存。CPU直接和一级CACHE连接,一级CACHE包括L1P(程序)和L1D(数据),大小分别为16 KB,分别占用独立的存储;一级CACHE的存储速度与CPU处理速度相同。一级CACHE与二级CACHE相连,称为L2,大小为256 kB,可以对程序和数据进行统一存取,L2 CACHE作为L1CACHE和片外存储器之间的一个桥梁,可以由设计人员自行配置大小,分为SRAM和CACHE。L2CACHE的速度为CPU的一半。经过试验对比,将L2分为128 kBCACHE和128 kB SRAM。将部分调用比较频繁的函数和数据常量放在L2SRAM中,以提高读写速度。 [p]
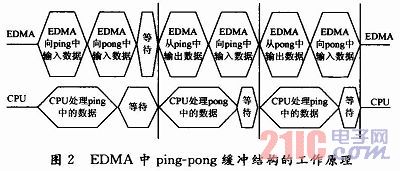
(2)EDMA。EDMA是增强的直接存储器访问,增加了高达64个传输通道,每个通道相互独立,且通道间的优先级可以设置。CIF格式的图像格式为352×288,一帧数据需要101 376 b,L2的CACHE容量有限,不能将所需要的参考帧和当前编码帧都放到片内CACHE中。X.264处理的最小模块为宏块16×16,将当前编码宏块保存到片内CACHE中来提速,DSP运行的同时将片外的下一编码宏块传输到片内。采用EDMA的ping-pong缓冲技术可以对X.264编码器的数据传输部分进行优化。这样既利用了DM642片内数据存储速度快的优点,又避免了使用较多的片内存储空间。ping-pong缓冲结构中EDMA与CPU的工作原理如图2所示。
3 优化结果
完成对代码的优化过后,通过CCS的编译将x264.out文件加载到DM642目标板上,使用了5个CIF实验序列来测试优化过后的编码速率。 CIF序列编码的帧数为100帧,量化系数为28。通过CCS所提供的clock工具记录测试序列中编码一帧图像所需要的CPU时钟数。实验测得的编码速率数据如表5所示。
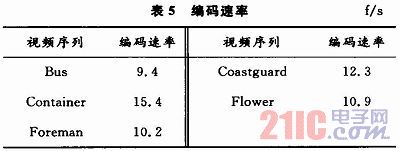
将X.264简单DSP代码化移植到DM642上,编码速率很低,只有平均0.6 f/s。对比表中所示的数据可知,对于纹理简单,运动不激烈的视频序列,编码帧数可达15 f/s左右,对于运动激烈,背景纹理较复杂的视频序列,则只有10 f/s左右。通过解压图片可以看出,解码后的图像没有发生明显的失真。
射频工程师养成培训教程套装,助您快速成为一名优秀射频工程师...
天线设计工程师培训课程套装,资深专家授课,让天线设计不再难...
上一篇:G.723标准数字录音系统设计
下一篇:小巧无触点电冰箱延时保护器
射频和天线工程师培训课程详情>>
