- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
TI 全新TMS320C66x 定点与浮点DSP内核成功挑战速度极限
录入:edatop.com 点击:
德州仪器 (TI) 全新 TMS320C66x 数字信号处理器 (DSP) 内核不仅为屡获殊荣的 C64x+™ 指令集架构 (ISA) 带来了显著的性能提升,同时还在同一处理内核中高度集成了针对浮点运算的支持。浮点处理技术首次能够用于传统上仅能满足定点处理运行速度要求的处理器中。该 C66x DSP 的 ISA 同时支持单精度和双精度浮点操作,并全面兼容 IEEE 754 标准。这一完美组合造就了无与伦比的DSP,能够在完全无损定点或浮点功能的情况下将浮点优势引入高速嵌入式架构中。与其它很多可提供浮点协作单元的嵌入式处理器不同,TI 最新 C66x DSP 内核直接将浮点指令集嵌入到C64x 定点指令集中。在C66x CPU上,用户可以选择逐条执行浮点、定点指令,因为在 C66x 中浮点与定点运算能力已经被完全集成在一起。正是由于这样,到底使用定点 DSP 还是浮点 DSP 已不再是设计上的挑战,因为 C66x DSP 做到了双全其美。
在同一 DSP 内核中集成定点与浮点功能将使嵌入式系统算法的开发与部署方式发生根本性变革。这听起来似乎有点夸大其辞,不过事实的确如此。在定点数字系统中实施算法所付51系列串口通讯例程出的艰辛是不可估量的。但充分满足对速度的需求又使这一工作势在必行,因为到目前为止市面上还没有任何可供使用的快速浮点DSP。我们能够轻松、便捷地将采用 Matlab 等浮点运算工具开发的算法移植到 DSP 中,而无需费力转换为定点方式处理。借助 TI 新型 C66x DSP 的浮点计算能力,大多数转换工作已显得没有任何必要。
对二进制数字表示的回顾
包含 TI DSP 等在内的所有数字处理器均采用带比特串(0 和 1 组成)的二进制形式表示数字。数字表示精度取决于所使用的比特位数和表示格式两个方面。
定点系统使用比特表示一个固定取值范围,这些值既可以是整数,也可以是具有固定数量的整数及小数位的数字。动态取值范围因而显得十分有限,而且超出设定范围的值必须达到端点。
定点处理器通常采用每秒乘法计算次数表示其 16 位运算性能。为了充分利用处理器的处理能力(例如,为获得其宣称的全部性能),为这些处理器开发的算法不得不在一系列预先确定范围的数字上进行操作。在定点实施过程中无法高效执行难以预知范围或变化幅度大的数据集。
浮点表示通过采用科学计数法来提供更广的动态范围,从而可使用尾数(或叫有效数字)及指数进行表示。C66x 内核可对 32 个比特位表示的数值实施单精度浮点运算,其采用的表示形式如下:(−1)5 × M × 2(N−127),其中 S 表示符号位,M 表示尾数或有效数字位,而 N 则表示指数。S 只有一个比特位,N 有 8 个比特位,而 M 以 23 个比特位表示。 这样,数字表示范围为 2−127 − 2128,并具有 24 比特精度的有效位。相比而言,16 比特位的定点算法仅能表示 216 个数值(从 0 到 65535),故其内在数字表示的可变范围要小很多。所以当数据集或工作在该数据集上的算法不可预知、动态变化幅度很大的情况下,浮点数字表示法更受青睐。另外很重要的一点是,有效数字始终以‘1’作为第一个数字,因此其数值始终保持 24 位精度。
TI 如何创造性地在同一内核中同时集成浮点与定点技术
最新 C66x DSP 内核 —— 图 1 显示的 C64x+ DSP 是 TI 最新 C66x DSP 的前代产品。该内核由两个对称的部分 (A & B) 组成,每部分具有四个功能单元。一个 .M 单元包含 4 个 16 位乘法器。
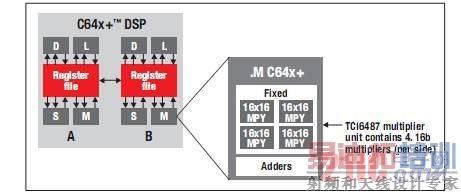
图 1 - TI C64x+ DSP [p]
图 2 所示的 TI 最新 C66x 内核具有同 C64x+ 内核相同的基本 A & B 结构。请注意,.M 单元的 16 位乘法器已增至每个功能单元 16 个,从而实现内核原始计算能力提升 4 倍。C66x DSP 实现的突破性创新使得由 4 个乘法器组成的各群集可协同工作以实施单精度浮点乘法运算。
图 2 - TI 最新 C66x DSP 内核
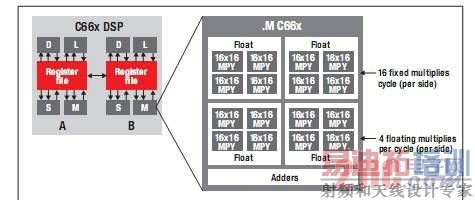
C66x DSP 内核可同时运行多达八项浮点乘法运算,加之高达 1.25 GHz 的时钟频率,使其当之无愧地成为市场上性能最高的浮点 DSP。将多个 C66x DSP 内核进行完美整合,即可创建出具有出众性能的多内核片上系统 (SoC) 设备。
浮点技术的成本 为使定点与浮点组件都能同时实现最佳性能,TI 专为该款最新的 C66x 内核开发了全新的浮点与定点指令,所有这些都对实现高效率的无线信号处理至关重要。由于采用浮点符号会带来额外的计算复杂度,从而导致了定点与浮点处理器“分庭抗礼”的局面。在定点运算情况下,加法、乘法等基本操作简单易行,但在浮点运算情况下,这些基本操作需要做更多工作量。比如两个浮点数相乘的情形:
请注意,指数需要相加操作,尾数则需要相乘操作。然后,最终 (M1×M2) 值需调整成 23 位的表示形式,这可能需要对指数的值也作更改。使用浮点技术进行所有基本运算时将需要很多额外的操作。
浮点计算带来的额外复杂度恰好说明了众多算法仅采用定点表示数和定点运算的原因。嵌入式处理器能够更快地运行定点运算,并且在众多情况下,只需要定点算法即可。例如,C66x DSP 内核在每个周期内都能执行 16 项定点乘法运算或者是 4 项浮点乘法运算。为使定点和浮点组件都能同时实现最佳性能,TI 为该款最新的 C66x DSP 内核开发了定点与浮点运算指令,所有这些都对实现高效率的无线基站信号处理至关重要。浮点指令 FPi 包括:
1. 单精度复数乘法
2. 矢量乘法
3. 单精度矢量加减法
4. 单精度浮点-整数之间的矢量变换
5. 支持双精度浮点算术运算(加、减、乘、除及与整数间的转换)并且完全为管线式
最新定点指令可实现最佳的矢量信号处理 (VSPi),其中包括:
1. 复数矢量和矩阵乘法,诸如针对矢量的 DCMPY,以及针对矩阵乘法的CMATMPYR1
2. 实矢量乘法
3. 增强型点积计算
4. 矢量加减法
5. 矢量位移
6. 矢量比较
7. 矢量打包与拆包 [p]
4
部分应用采用定点技术的隐性成本 尽管与浮点处理相比,DSP 能够实现更快的定点处理,但却不得不为特定算法在开发时间方面相付出代价。通信系统典型的设计流程是首先基于计算机模型开发相应算法,然后再将这些算法用在初始系统部署中。随着部署及应用范围的不断扩大,工程师便可将收集到的现实世界的数据带回实验室,以通过对算法的校正、调优提升系统性能。通常可使用 Matlab 或其他固有的浮点工具开发新的算法。接下来面临的挑战是如何在保持算法和系统性能的同时,将这些浮点算法转换为定点算法。复杂拙劣的算法会占用大量系统资源,从而导致系统的整体性能下降。在需要用到复杂处理的情况下,将 Matlab 中的代码移植到真实系统中就算耗费数周乃至数月的时间也不是什么罕见的现象。TI 最新架构具有原生浮点支持,从而使从浮点到定点的整个转换过程变得毫无必要。通过在 C66x DSP 上使用浮点指令,可轻松将代码从 Matlab 等工具中进行移植,并直接编译至 TI 的 DSP 中,如图 3 所示。
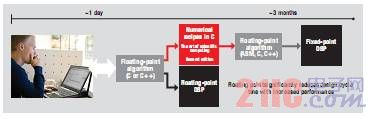
图 3 - 浮点功能可大幅加速产品上市进程
浮点技术在 4G 基站中的重要作用 无线电话正不断演进发展成为需要高数据量传输以支持视频流和其他高宽带应用的复杂媒体平台。为了充分满足这些需求,无线行业需要在基站中部署 WiMax 和 LTE 等最新的 4G 技术,力争为终端用户提供更高的数据吞吐量。这些 4G 基站利用多天线信号处理及 MIMO、Beamforming 等算法来提高其性能。通常情况下,这些算法会依赖本身易于量化和缩放与定点处理相关的问题的矩阵反演技术。采用浮点实施这些算法可进一步提高系统的速度及精确度,从而获得更高性能,并最终为移动电话用户带来更精彩的体验。
5
不断增长、层出不穷的高性能应用亟需浮点运算功能 之前我们已经讨论过,由于执行每个基本算术运算需要较长时间,所以浮点处理是很耗时的,但这种情况在当算法需要很大动态范围操作时则不然。在 4G 处理的矩阵反转操作中,由于没有简单可行的定点操作方法,因此算法虽然运行于定点处理器(无原生浮点支持)中,但基本还是被迫对浮点运算进行仿真。由于处理器没有获得定点功能的优势,因而在与使用支持浮点运算的处理器运行时,这些算法的运行速度要慢很多。C66x DSP 自身支持浮点功能,所以消除了这种性能瓶颈。例如,C66x DSP 内核运行 MIMO 及其他关键的多天线信号处理算法比在 C64x+ DSP 上运行定点功能的相同算法整整快 4 倍。
在国防、公共安全基础设施及航空电子设备等各种任务关键型应用领域,浮点功能不仅可简化开发,同时还能大幅提高性能。由于能够直接使用 MATLAB 中的代码,浮点不仅能够显著缩短开发周期,并且与大型 FFT 等定点代码相比,众多算法的浮点实施也会占用更少的执行周期。例如,雷达、导航与制导系统会处理通过传感器阵列获取的据量。众多传感器组件的各种不同能源模式可提供与目标的跟踪和定位相关的信息。这组数据必须通过线性方程组处理才能提取到所需信息。解决办法包括矩阵反演、分解与自适应滤波等数学函数。对更高输出精度与更大动态范围的需求促使这些功能在诸如C66x 等 1.25GHz 浮点引擎上实现出众的表现。另外,C66x 拥有的 SIMD 增强以及每周期定点能力高达 1.25GHz 32 MAC 的卓越性能,也为设计人员在选择适合其应用的浮点与定点组合方面提供了极大的灵活性。
除机器视觉、工业自动化应用外,超声波等用于医疗影像的影像识别也需要非常高的计算准确度,这些均可从浮点功能获益匪浅。在进行超声波检查时,必须对声源发出的信号进行定义和处理,才能创建可提供实用诊断信息的输出影像。对于用户而言,C66x ISA 提供的更高精度可使影像系统达到更高的分辨率和识别率。
浮点应用众所周知的领域便是语音处理,其不仅需要严格的时延,同时还需要超高的采样率,这些都会极度依赖浮点功能提供的更高计算精度和更大的动态可变范围来适应滤波及其他降噪算法。此外,机器人设计也会考虑宽动态范围。因为装配线上也许会发生难以预料的事件。浮点 DSP 的宽动态范围可确保机器人控制电路以可预知的形式处理不可预知的状况。
结论 TI 最新的 C66x 内核催生了基于 DSP 的嵌入式处理器及SoCs 的创新类别,因而您无需再在定点处理器还是浮点处理器之间进行利弊权衡。这一革命性的进步将从根本上改变实时系统算法的设计与开发方式,从而使得系统开发人员能够轻松而快速地构建极具差异化功能的全新解决方案。
射频工程师养成培训教程套装,助您快速成为一名优秀射频工程师...
射频和天线工程师培训课程详情>>
