- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
克服嵌入式CPU性能瓶颈
录入:edatop.com 点击:
作者:Julio Diez Ruiz
过去几年,采用多线程或多内核CPU的微处理器架构有了长足的发展。现在它们已经成为台式电脑的标准配置,并且在高端嵌入式市场的CPU中也已非常普及。这种发展是想要获得更高性能的处理器设计师推动的结果。但硅片技术已经达到性能极限。满足不断提高的处理能力需求的解决方案,高度依赖于像在基于微处理器的系统级芯片(SoC)中复制内核处理器这样的架构化解决方案。
戈登·摩尔在1965年提出的摩尔定律指出,随着晶体管尺寸的缩小,每平方英寸硅片面积上可以集成的晶体管数量每两年会翻一番。当然,这个“定律”并不是一种物理规律,而是根据60年代和70年代对技术的观察经验得出的一个猜想。但它从第一次被提出到现在都非常准确——并且至少在下一个十年中有望延续其正确性。
摩尔定律一直能保持正确性的原因是,缩小芯片上元件尺寸的能力使得设计师能够不断提高处理器、存储器等器件中的晶体管密度。由于晶体管越来越小,设计师可以在处理器中增加更多的功能单元,并在相同面积上实现更加复杂的架构。
由于这种更高的密度,像分支预测或乱序执行等技术在现代处理器中已经很普及,虽然它们非常耗用资源。这些技术提高了每周期执行指令数(IPC),即提高了指令吞吐量,这是影响处理器总体性能的两大基本根源之一。更小的晶体管尺寸还可以支持更高的时钟速率。当晶体管的栅极长度缩短1/k时,电路延时也可以减少同样的量。随着电路延时的减少,晶体管开关时间也相应缩短,因此时钟速率可以提高k倍。处理器工作在更高频率可以提供更高的性能,但需要付出一定的代价。
然而,现在设计遇到了一些实际的限制。随着晶体管尺寸的进一步缩小,晶体管密度和芯片频率的提高显得非常有限,而影响越来越大。其中更高的功耗和更大的传输延时是最令人担心的两大因素,也是影响进一步发展的主要障碍。
芯片功耗
芯片功耗和相关的散热问题正在成为硬件设计师面临的一个巨大障碍。随着晶体管数量的不断增加,当前处理器在很小的面积上就需要相当大的能量。这意味着需要散发很高的功率密度。问题不仅在于晶体管的数量,高的工作频率对功耗也有很大的影响,下面还会讨论到。
为了对过去几十年中这些参数的演变有一个印象,图1显示了在20年时间内Intel的x86架构中晶体管数量和工作频率的增加情况,最早的数据来自80386架构——第一个32位x86处理器。
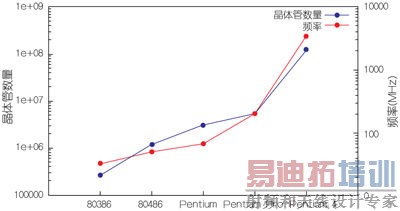
图1:X86架构中的晶体管数量和频率演变。
注意,上述两个参数都是用对数刻度标示的,这也表明了它们进步幅度之大。在功耗方面,图2显示了这些处理器的典型功耗演变情况,这次采用的是线性刻度。
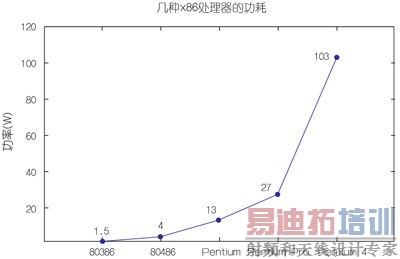
图2:不同代X86处理器的功耗演变。
晶体管数量在持续增加,一些最新的Intel Core i7处理器中的晶体管数量已经超过22亿个。功耗也在缓慢增加,高的可达130W,当然这取决于具体型号。然而,这些新处理器的时钟频率却不再增加,保持在3.5GHz左右。
时钟频率停滞不前的原因之一是目前的集成电路已经达到功率密度的物理极限,产生的热量已经达到芯片封装能够散发的极限,因此硬件设计师必须限制频率的提高。Intel的确从未为功效而牺牲性能,但如今的物理限制使得他们只能在功耗上面做文章。
一些公式可以更好地展示频率和晶体管数量是如何影响芯片功耗的。一些简单的数学关系可以让我们清楚地看出为什么这些参数在当前设计中是如此重要。
下列公式显示了芯片功耗与工作频率和其它系数的关系。
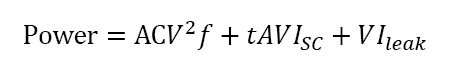
[p]
这是用于当前集成电路的主流半导体技术——CMOS技术的功耗表达式。公式的第一部分(加数)是芯片的动态功耗(也就是晶体管开关时由容性负载充放电引起的功耗),代表芯片执行的有用工作。A是活跃系数,代表每个时钟周期中进行开关的晶体管比例(因为每个时钟周期中并不是所有晶体管都必须开关);C是晶体管的容性负载;V是电压;f是频率。
公式中的第2个加数是由于短时间短路电流(ISC)引起的少量动态功耗,这个电流是在有限的上升或下降时间t内从晶体管电压源流到地的电流。最后一个加数是静态功耗,即由于漏电流(Ileak)引起的功耗,这也是唯一在加电,但不活动的电路中存在的功耗。这种功耗适用于整个电路,与晶体管状态无关,因此该项中没有活跃系数。
从公式的第一项可以看出为何功耗只是呈线性增加,而频率呈对数增加,这是因为电压是二次方的关系。
工程师能够将这个电压从5V减小到1V以下,从而帮助他们控制住功耗同时不降低性能。遗憾的是,许多因素是相互影响的,工程师必须不断进行折衷。例如,想象一下我们想要通过降低最初设置在2V的电源电压来减小芯片的动态功耗(只考虑公式中的第一项)。如果我们能够将电源电压降低到1.7V,虽然电压只下降了15%,但功耗可以显著下降28%。然而,降低电源电压对电路的最大频率和晶体管的阈值电压(晶体管的导通电压)有副作用。
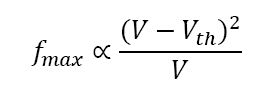
在我们这个例子中,如果阈值电压为0.5V,电路工作频率为4GHz,那么为了保持相同的工作频率,必须将阈值电压降低到大约0.32V。然而,这样做也许是不可行的,因为阈值电压依赖于一些技术参数,当超出一定的范围时,不改变半导体制造工艺是不可能继续减小的。如果不改变阈值电压,最大频率将降低到3GHz,降幅为25%。
另一方面,即使你能够降低电源电压和阈值电压并且不影响性能,但漏电流与阈值电压呈指数依赖关系:
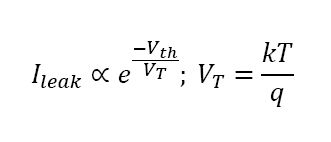
电压VT是热电压,取决于绝对温度T。k是玻尔兹曼常数,q是电子上的电荷量。在常温时热电压值大约为30mV。当相比于热电压有较大的阈值电压时,漏电流效应可以忽略,但当阈值电压较小——大约在100mV左右时,漏电流效应就变得突出了。
另外,不仅热电压与温度有关,阈值电压通常也随温度变化而变化,这两种变化将叠加在一起共同影响漏电流。漏电流增加意味着静态功耗的增加,因此对于低电压值而言,电压降低技术存在一定的实用性限制。
图3显示了两个不同温度下的这些效应。T=300K的第一条曲线显示了与阈值电压的指数关系。T=330K的第二条曲线是考虑了阈值电压随温度变化因素下的估计数据。这样,横坐标仍然代表标称阈值电压,但晶体管的实际阈值电压因温度效应而偏向更低的值,因此对漏电流有较大的影响。
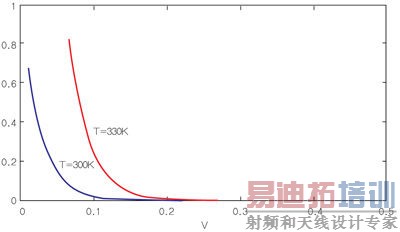
图3:阈值电压和温度对漏电流的影响。
漏电流还与绝缘栅厚度有关。当采用非常薄的栅极电介质时,电子可以穿过绝缘层形成隧道效应,进而形成隧道电流,导致高功耗。鉴于使用32nm及以下工艺时的实际栅极长度,这种效应在当前半导体技术工艺中是非常重要的。
[p]
当然,处理器内核并不是芯片中唯一耗能的器件。比如内存也消耗相当大的能量,现代处理器专门开辟了大块裸片区域来集成多级缓存。
工程师通常会应用多种设计技术来减少内存的漏电流或活动系数(功耗公式中的A系数),进而达到降低功耗的目的。
例如,缓存等级的层次化组织不仅可以改善数据访问时间,而且有助于降低消耗的功率,因为更小更近的缓存所需能量比更大更远的缓存要少。这种结构化解决方案在降低功耗的同时能保持性能不变。与这种想法类似,另外一个常用的解决方案是将内存组织成库的形式来提高效率。这种情况下可以只激活正在访问的库,从而节省能量。
然而,追求更高性能并不总是正确的做事方式。有时以一定的吞吐量代价来降低功耗就足够了。有些处理器专门用于特定的应用,它们总是做相同类型的运算,比如DSP。音频处理、数字滤波器或数据压缩算法是这些器件的典型应用,评估这些应用的指标是一次操作需要多少能量、这些处理器做这些运算需要花多长时间。
一个处理器如果在执行算法时一开始就比其它处理器花更多的时间但消耗更少的功率,那么最终就具有更高的能效值。衡量这种效率的一个指标是MIPS/W(每秒每瓦百万指令数)。虽然必须关注指标MIPS,但一般来说具有更高MIPS/W的器件被认为具有更高的效率,这对嵌入式设备特别是电池供电设备来说尤其让人感兴趣。事实上,如今在服务器和数据中心领域人们更乐意使用更高能效的处理器。
芯片的传输延时
限制晶体管密度提高和芯片工作频率增加的另外一个主要因素是走线的传输延时。现代处理器中使用的GHz数量级高频时钟意味着一个时钟周期不到一个纳秒。这么短的周期时间正在成为影响信号传播的一个问题。
减小芯片的特征尺寸将造成栅极长度和晶体管电容减小,从而有利于提高时钟速率,克服容量范围限制。但芯片上的走线由于更高的电阻和电容而变得越来越慢。走线的宽度和高度变小是走线面积缩小的根本原因,并导致更高的电阻。
由于走线表面积变小,与表面积有关的电容跟着降低,但相邻走线之间的距离也在缩小,最终形成更高的耦合电容。耦合电容增加的速度大于表面电容减小的速度,因此抵消了表面电容减少效应,并形成了更高总体走线电容的组合效应。
走线传输延时直接正比于电阻与电容的乘积:Rw×Cw,因此随着每一代缩小特征尺寸的新技术的推出,走线延时变得越来越长。随着时钟速率的加快和走线传输速度的变慢,信号可以传输的距离以及一个时钟周期内可以到达的芯片面积将变小,最终导致通信范围成为约束条件的新情况。
对于具体的微架构来说,这不会成为大问题,因为电路尺寸将以二次方的比例缩小。但为了充分利用更小的晶体管尺寸并获得更高的IPC,设计师正在开发更为复杂的微架构,生成更深的流水线,增加更多的执行单元,并使用大的微架构化结构。现在,芯片上更高的通信延时将对尺寸甚至这些结构的布局和最大工作频率造成实际的限制。
举个例子,Intel Pentium 4中使用的错误预测流水线设计要求的级数是Pentium Ⅲ流水线的两倍。由于具有更高的时钟速率和走线延时,流水线必须划分为更小的段,并且在每级流水线中做更少的工作。但走线延时变得如此之大,以致于Pentium 4流水线中有两级是额外增加的,用于将信号从一级驱动到下一级,以便有足够的时间去执行要求的运算,因为有很多的时钟周期时间用在了信号抵达下一级上。
在ARM公司发布的高级微控制器总线架构(AMBA)规范中,可以看到走线延时如何影响设计的另一个类似例子。在第一版AMBA规范中引入、设计用于互连高性能系统模块的高级系统总线(ASB)使用了双向总线和主/从架构。
在第二版AMBA规范中,引入了高级高性能总线(AHB),用于改善对更高性能的支持,并替代ASB。在这个新的总线规范中,独立于其它功能的双向总线被替换为复用总线机制。这种修改初看起来似乎增加了不必要的走线和电路复杂性。但在很高性能系统中的走线延时效应使得有必要引入中继驱动器(与Pentium 4例子中看到的一样)。这在形成组合式复用总线的单向总线中是可行的,但在双向总线中很难实现。
[p]
面临的挑战
我们已经看到有两个主要的技术性限制在不断影响摩尔定律和和处理器性能的持续改进。但技术在不断发展。缩小特征尺寸有助于提高晶体管密度和频率,而设计师也仍在设法缩小晶体管尺寸,单颗芯片上的晶体管数量有望超过10亿个。
业界预测,半导体技术工艺将在2014年达到35nm栅极长度,但实际上从2011年开始就已经有人在用22nm工艺制造产品了。功耗和传输延时问题激励着业界每个人去研究制造晶体管的新材料,而在现代处理器中已经在应用新的组织化和架构化解决方案。高k值氧化栅(k指的是材料的介电常数)正在替代用了几十年的二氧化硅栅极电介质,它能实现更薄的绝缘层并更好地控制漏电流。
新的低k值电介质的使用使得减小耦合电容以及传输延时成为可能。实现单个大型单片内核的传统微架构正在演变为更简单的多内核微架构,后者允许占大部分的局部通信,从而避免了大的延时。
最近一些芯片制造商,如Intel公司,发布了三维集成电路。Intel最新的Ivy Bridge系列处理器作为Sandy Bridge系列的后继产品,采用了新的三栅极(tri-gate)晶体管技术,在提升处理能力的同时可以降低所需的能耗。
使用3D晶体管替代以前的平面结构晶体管后,各级流水线可以彼此垂直堆叠,从而能够有效地缩短块与块之间的距离,消除走线延时效应。据Intel介绍,公司的22nm 3D Tri-Gate晶体管功耗在相同时钟频率下不到32nm芯片上的平面晶体管的一半,超过了从一代工艺升级到下一代时通常所取得的效果。
多内核架构的发展非常迅速。例如,Tilera公司已经在单颗芯片上成功开发出首个100内核的处理器。为了达到这种集成度,Tilera将处理器与他们的设计师称之为“瓦片(tile)”的通信开关组合在一起。通过组合这些瓦片,Tilera公司能够搭建出一个形成网状网的硅片。处理器一般通过总线互相连接,但随着处理器数量的增加,这种总线很快变成了瓶颈。借助Tilera用瓦片平铺出的网,每个处理器连接一个开关,它们可以像点到点网络那样相互通信。除此之外,每个瓦片可以独立运行一个实时操作系统。或者你也可以将多个瓦片组合在一起,运行像SMP Linux那样的操作系统。
目前业内正在研究开发令人称奇的石墨烯晶体管,每个晶体管都是用一片仅一个原子厚度的碳制造的。理论上,这些晶体管支持非常高的工作频率,可以高达1THz(1000GHz),甚至可以在柔性基板上制造这些晶体管。不过这种技术还面临许多挑战,我们可能还要等几年才能看到这些先进技术实用化。
本文小结
目前业界面临的问题是如何充分发挥这种巨大的并行处理能力。但嵌入式软件行业已经在开发强大的工具来帮助构建新的、复杂的许多内核应用世界。
针对共享和分布式存储架构的OpenMP和MPI建议、以及针对不同种类系统的并行编程制定的开放标准OpenCL(开放计算语言)都非常有前途。利用OpenGL可以为混合有多内核CPU、GPU甚至DSP的系统开发出合适的软件。但最大的挑战可能是改变编程人员的想法,使他们学会如何编写出适合在这些系统运行的高度并行和可靠的软件。
关于作者:
Julio Diez是一位软件工程师,在嵌入式领域拥有15年的丰富经验。在过去6年中他致力于为嵌入式系统开发通信和安全软件,包括用于西班牙国家安全局的首个安全通信系统。他的兴趣包括多内核架构、操作系统、软件设计和并行编程。他拥有西班牙马德里理工大学的电信工程学士学位。你可以通过juliod73@yahoo.es与他取得联系。
射频工程师养成培训教程套装,助您快速成为一名优秀射频工程师...
射频和天线工程师培训课程详情>>
