- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
设计大吞吐量、实时SoC系统的最佳实践
录入:edatop.com 点击:
现代SoC软件通常包括多种应用,从汽车发动机控制等硬件实时应用,到HD视频流等大吞吐量应用。随着现代SoC向大吞吐量系统的快速发展,处理器内核数量不断增加,宽带互联也越来越多,导致混合系统设计成为挑战。在这类系统中实现硬件实时—μs量级响应,抖动不到1μs,需要仔细的综合考虑分析和系统划分。随着SoC的复杂度越来越高,将来的验证策略也必须纳入考虑范围。
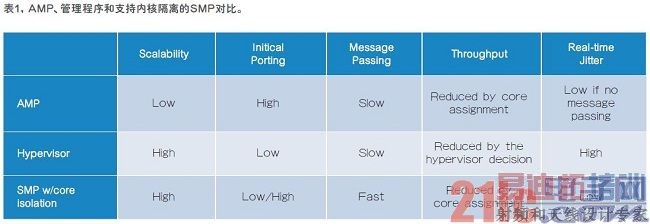
这类系统设计主要有三种方法—非对称多处理(AMP)、管理程序,以及支持内核隔离的对称多处理(SMP)(主要的对比见表1),系统设计人员可以从中选择一种方法来优化混合SoC系统。
非对称多处理
AMP实际是基于物理上不同的处理器内核的多操作系统(OS)端口。一个例子是,在第一个内核上运行专门用于处理实时任务的裸金属OS,在其他内核上运行嵌入式Linux等完整的OS。很多时候,最初将OS导入到内核中非常简单,但是,在启动代码和资源管理上很容易出错,例如,存储器、高速缓存和外设等。当多个OS访问相同的外设时,行为会是不确定的,调试起来可能非常耗时。通常要求仔细的保护ARM TrustZone等体系结构不受影响。
更复杂的是,在OS之间传递消息要求存储器共享,一起采用其他保护手段进行管理。不同的OS之间通常不会共享高速缓存。要通过非高速缓存区来传递消息,对于总体性能而言,增加了延时和抖动。从可扩展角度看,随着内核数量的增加,需要进行多次重新导入,使软件体系结构较差。
监控程序
管理程序是直接在硬件上运行的底层软件,在其上可管理多个独立的OS。最初的导入与AMP相似,而其优势在于管理程序隐藏了资源管理和消息传递中不重要的细节。缺点是由于吞吐量和实时性能要求,增加了额外的软件层,导致出现性能开销。
对称多处理
支持内核隔离的SMP在多个内核上运行一个OS,支持在内部划分内核。一个例子是让SMP OS在第一个内核上分配实时应用程序,在其他的内核上运行非实时应用程序。随着内核数量的增加,SMP OS可以设计无缝导入,因此,这一方法的可扩展性比较好。所有内核都是由一个OS管理的,因此,内核之间可以在L1数据高速缓存级上传递消息,通信速度更快,抖动 更低。
通过内核隔离,可以保留一个内核用于硬件实时应用,以屏蔽其他大吞吐量内核的影响,保持了低抖动和实时数据响应。这样,设计人员可以考虑使用哪一个OS,而不用重新设计容易出错的底层软件来管理多个OS。因此,这一般是很好的软件体系结构决定。如果从多个OS开始,最初的导入会需要一些付出。但是,从一个SMP体系结构开始会省很多事。
通过SMP优化大吞吐量、实时SoC
基于对各种方法的分析,支持内核隔离的SMP是最好的体系结构,优化了大吞吐量、实时SoC系统。我们考虑的体系结构与图3的系统相似,其中,I/O数据输入到SoC中,处理器对其进行计算,送回至I/O,满足低抖动和低延时实时响应要求。此外,SoC包括了多个内核,可同时运行其他吞吐量较大的应用程序。
首先,需要理解一个实时响应(循环时间)由哪些组成:
1.从一个I/O,将新数据传送至系统存储器(DMA)。
2.处理器探测系统存储器中的新数据 (内核隔离)。
3.将数据复制到私有存储器(memcpy)。
4.对数据进行计算。
5.将结果复制回系统存储器(memcpy)。
6.将结果传送回I/O(DMA)。
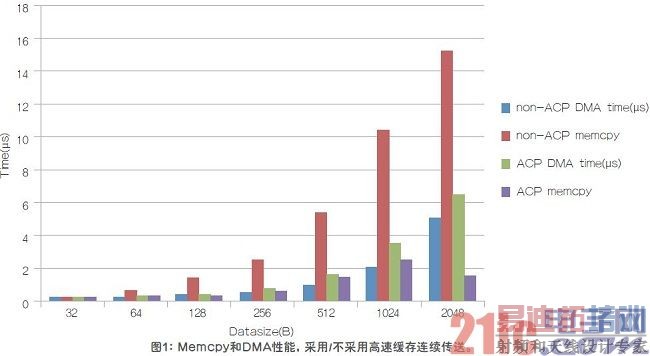
抖动和延时是6个步骤的累积,因此,需要优化每一个步骤。采用支持内核隔离的VxWorks等RTOS,可以在纳秒范围内完成轮询/中断响应(步骤2)。数据计算也是专用的,具有很好的可预测性(步骤4)。因此,我们的重点是综合考虑直接存储器访问(DMA)和memcpy(步骤1/3/5/6)。主要有两种方法来传送数据:高速缓存连续传送,以及不支持高速缓冲连续的传送。这两种方法在DMA和memcpy上的响应有很大的不同。如图1所示,虽然高速缓存连续传送(使用ARM高速缓存连续端口(ACP))导致DMA需要较长的通路,但处理器只需要访问L1高速缓存就可以获得所传送的数据。因此,使用高速缓存连续传送的memcpy时间要少很多,但是DMA性能会有些劣化。对于设计人员而言,由于是直接高速缓存访问,因此,高速缓存连续传送的延时更短,抖动 更小。
案例研究:SoC设计最佳实践
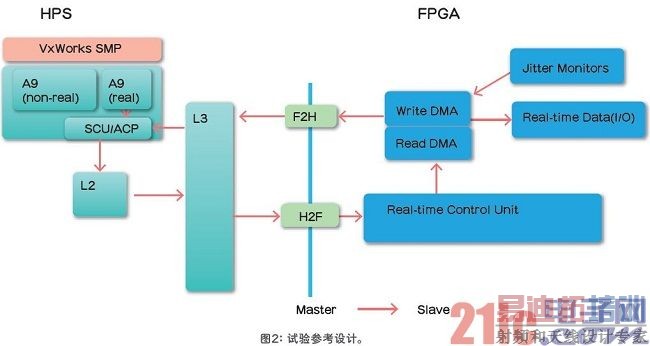
可以使用Cyclone V SoC FPGA开发套件,通过参考设计来演示一个完整的系统。器件在一个芯片中包括了一个双核32ARM Cortex-A9内核子系统(HPS)和一个28nm FPGA。下面总结了硬件和软件体系结构,如图2所示。
硬件体系结构
·两个DMA,将数据从FPGA I/O传送至ARM处理器,反之亦然。
·两个DMA都连接至ACP,实现数据在ARM处理器高速缓存的直接传送。
·实时控制单元IP,以尽可能快的方式启动ARM处理器和DMA引擎之间的消息传递。
·抖动监视器直接探测DMA信号,采集实时性能和抖动,精度在±6.7ns以内。
软件体系结构
·在双核ARM处理器上的VxWorks实时OS运行在SMP模式下。
·内核隔离,用于在第一个内核上分配实时应用程序,在第二个内核上分配其他的非 实时应用程序。
·实时应用程序连续从I/O读取数据,计算,然后将结果发送回I/O。
·当连续运行FTP传输并对数据加密时,非实时应用程序加重了对ARM内核和其它 I/O性能的要求。
结果
在长度不同的数据上运行实验,长度从32 字节直至2,048字节。为了采集循环时间的直方图,来分析抖动(最大和最小循环时间之间的不同),每一长度都要运行数百万次。如图3所示,即使是在第二个内核上运行数据流负载很大的FTP,经过数百万次的测试,延时也在微秒级,而抖动不到300ps。长度不同,会有些抖动摆动,但是可控制在200ps内,并不明显。
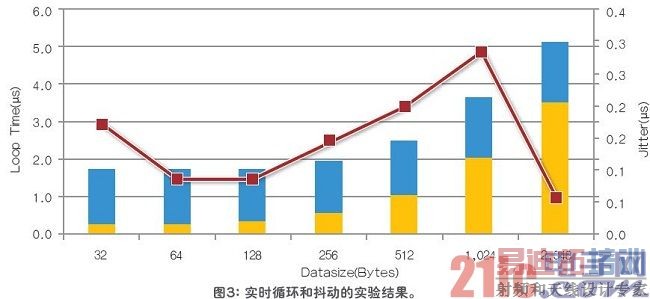
相同的FTP应用程序也运行在VxWorks SMP上,使用了两个内核,速度提高了近2倍。因此,这一方法并没有劣化吞吐量,是吞吐量和硬件实时应用程序的折中选择。但是,由于对内核进行了硬件划分,不能够灵活的增加内核数,因此,AMP解决方案也同样有一些劣化。
结论
设计一个支持大吞吐量和实时应用程序的均衡SoC系统需要进行很多综合考虑,例如:
·DMA数据传送。
·连续高速缓存。
·处理器内核与DMA之间的消息传递。
·OS划分。
·软件能够随着处理器内核数量的增加而进行扩展。
在此次实验中,我们展示了一个“最佳实践”系统设计,它使用了支持内核隔离和高速缓存连续传送的SMP,实现了低延时、低抖动实时性能,同时软件能够扩展应用到未来几代的SoC产品中。
射频工程师养成培训教程套装,助您快速成为一名优秀射频工程师...
射频和天线工程师培训课程详情>>
