- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
快速实现SHA-1算法的硬件结构
录入:edatop.com 点击:
摘要:安全散列算法是数字签名等密码学应用中重要的工具。目前最常用的安全散列算法是SHA-1算法,它被广泛地应用于电子商务等信息安全领域。为了满足应用对安全散列算法计算速度的需要,该文提出了一种快速计算SHA-1算法的硬件结构。该方法通过改变硬件结构、引入中间变量,达到缩短关键路径的目的,进而提高计算速度。这种硬件结构在0.18Lm工艺下的ASIC实现可以达到3.9Gb/s的数据吞吐量,是改进前的两倍以上;它在FPGA上实现的性能也接近目前SHA-1算法商用IP核的两倍。
关键词:集成电路设计;安全散列算法(SHA-1);关键路径;硬件结构
单向散列函数是密码学中一种重要的工具,它可以将一个较长的位串映射成一个较短的位串,同时它的逆函数很难求解。许多安全技术中都会用到单向散列函数的这种特殊性质,比如数字签名、密码保护、消息鉴别等。鉴于单向散列函数在密码系统中的重要地位,密码学家们设计了各种各样的安全散列函数。目前最常用的散列函数是NIST于1995年颁布的安全散列算法SHA-1。
SHA-1算法和之前的MD4、MD5等安全散列算法原理很接近,但是安全性更好。它可以通过一系列的迭代计算把任意长度的比特串压缩成长度为160bit的位串。而且一般认为它的这个计算过程在密码学意义上是单向的,也就是说很难找到两个不同的位串可以压缩成相同的160bit。到目前为止,还没有对SHA-1有效的攻击方法。
由于SHA-1算法的良好特性,它被广泛使用在诸如电子商务这样的现代安全领域,尤其是被大量应用于公钥密码系统的数字签名中。目前几乎所有相关密码协议、标准或者系统中,都包括了SHA-1算法,其中比较著名的有SSL、IPSec和PKCS。在这些场合下,能否快速计算出消息的散列值直接影响到整个系统的处理能力。但是,由于SHA-1算法本身是一个很复杂的算法,计算量也较大,加上每次迭代都需要依赖上次的计算结果,因此不论是硬件还是软件实现,计算速度都很有限,这大大限制了算法的适用场合。
本文提出一种新的硬件实现方法,通过改变迭代结构,达到缩短关键路径的目的,进而提高SHA-1的计算速度。
SHA-1算法
算法描述
SHA-1算法能够将任意长的输入压缩成160bit的输出。但是,SHA-1算法中的基本迭代只能处理512bit的数据块,因此为了处理任意长度的数据,首先需要将输入的消息每512bit分成一块,并且将最后一块不足512bit的消息按一定规则补齐。(限于篇幅,SHA-1算法的详细描述见文[1],下面是算法进一步的简单描述。)
分块之后就可以对每块消息按下述方法依次进行处理。
1)在5个中间变量H0、H1、H2、H3和H4中置入特定初值。
2)对每块消息依次执行步骤a)到e)
a)将512bit的消息块分成16个32bit的字W0,W1,…,W15;
b)For t=16 to 79l etWt=S1(W t-3W t-8
W t-14
W t-16);
c)LetA=H0,B=H1,C=H2,D=H3,E=H4;
d)For t=0 to 79 do
i)teMP=S 5 (A)+f t(B,C,D)+E+Wt+Kt;
ii)E=D;D=C;C=S30(B);B=A;A=TEMP;
e)LetH0=H0+A,H1=H1+B,H2=H2+C,H3=H3+D,H4=H4+E。
所有消息块处理完后得到的5个32bit变量H0到H4构成了160bit的数据,这就是SHA-1算法输出的散列值。
算法中使用了一些简单的逻辑函数和常数,其中函数ft()和常数Kt分别为

算法中S1(*)、S5(*)和S30(*)分别表示按位循环左移1bit、5bit和30bit。算子“∧”、“∨”、“”和“+”分别表示按位“与”、按位“或”、按位“异或”以及32bit整数加法。
[p]
算法分析
从算法描述可以看出,SHA-1最核心的计算是一个计算5个中间变量的迭代:
An=S5(A n-1)+f n(B n-1,C n-1,D n-1)+
E+Wn+Kn,
Bn=A n-1,
Cn=S30(B n-1),
Dn=C n-1,
En=D n-1.
在硬件实现中,5个变量在一个周期内同时由组合逻辑电路根据上次迭代的计算值产生,因此每次迭代所需要的时间是由最慢的计算过程决定。这样一条最慢的计算路径也就是所谓的关键路径。如果完全按照SHA-1的原始算法进行硬件设计,那么很明显的关键路径是变量A的计算。在每次迭代过程中,计算变量A需要进行4次32bit的整数加法和若干组合逻辑。这些计算一共需要的时间也就是算法硬件实现的最短周期。正是因为变量A的计算比较复杂,造成SHA-1算法硬件实现的工作频率难以提高。
因此,加快SHA-1硬件实现的计算速度关键就是改变迭代结构,从而缩短每次迭代过程的关键路径。
硬件快速实现的新结构
观察算法可发现,除了变量A以外,其他4个变量的计算都相当简单。因此,如果将变量A的计算过程通过一定方式分解成若干并行的计算,那么就可以在不增加迭代次数的前提下,缩短整个计算的关键路径。
出于这种目的,1997年A.Bosselaers等人对SHA-1算法的结构进行了分析,发现SHA-1算法的数据流图可以分解成并行的7路数据处理,每路数据上一个周期只需一个基本操作:加法、“异或”或者循环移位。
在此关于SHA-1结构结论的基础上,本文通过引入中间变量的方法,将计算的关键路径分解成若干个较短的路径,从而达到加速硬件计算的效果。考虑到硬件实现中32bit整数加法的延时远远大于循环移位和普通逻辑运算,所以分析关键路径时只考虑加法的代价,而忽略其他逻辑运算的延时。
首先引入中间变量P n-1=fn(B n-1,C n-1,D n-1)+E n-1+Wn+Kn,那么可以得到An=S5(A n-1)+P n-1。也就是说,将第n次迭代的部分计算提前到第n-1次迭代中进行计算。变形后,第n次迭代中A的计算只需要进行一次32bit整数加法。
但是这种方式下,变量P的计算仍然需要依赖于同一次迭代中的其他变量,也就是说在一次迭代中需要在计算完其他变量后才能计算出P,这样的话计算的关键路径还是没有缩短。所以还要充分利用A到E5个变量之间的相互关系
B n-1=A n-2,
C n-1=S30(B n-2),
D n-1=C n-2,
E n-1=D n-2.
将P的计算变化为P n-1=f n(A n-2,S30(B n-2),C n-2)+D n-2+Wn+Kn。如此之后,第n-1轮的P值可以完全依赖于前一轮也就是第n-2轮的变量值计算而得。迭代计算的关键路径就分裂成变量A和P两路并行的计算。
类似的再引入其他中间变量,不断的分解关键路径,最终的迭代可变形为
An=S5(A n-1)+P n-1,
Pn=f n+1(A n-1,S30(B n-1),C n-1)+Q n-1,
Qn= C n-1+R n-1,
Rn=W n+3+K n+3,
Bn=A n-1,
Cn=S30(B n-1).
可以发现通过引入中间变量,使得计算变量A的关键路径分解成A、P、Q、R的4路并行计算,所需要的4次加法平均在4个周期内完成。这样每次迭代过程中任何一个变量的计算最多只需要一次32bit整数加法和少量组合逻辑。在此基础上,SHA-1算法可以通过如下方法来计算
1)将输入的512bit消息分成16个字W0,W1, …,W15;
2)For t=16 to 79 let Wt=S1(W t-3
W t-8
W t-14
W t-16);
3)LetA=H0,B=H1,C=H2,D=H3;
4)LetP=f 0 (B,C,D)+E+W0+K0,Q=D+W1+K1,R=W2+K2;
5)Fort=0 to 79 do
a)TEMP=S5(A)+P;
b)P=f t+1(A,S30(B),C)+Q;
c)Q=C+R;
d)R=W t+3+K t+3;
e)B=A;C=S30(B);A=TEMP;
6)LetH0=H0+A,H1=H1+B,H2=H2+ C,H3=H3+S30(A76),H4=H4+S30(A75)。
虽然引入中间变量的计算后,每块数据需要额外增加一个预计算的步骤4),但是因为关键路径得以缩短,整体硬件实现的速度仍然会大大提高。
[p]
实现结果
使用Verilog硬件描述语言按本文提出的优化方法实现了SHA-1算法,并使用Synopsys Design Compiler在0.18Lm标准单元库下综合,得到表1中的结果。表1中还包括了文[6]的实现结果。文[6]同样使用了0.18Lm工艺,但是实现SHA-1算法的方法仍然是传统的直接计算ABCDE5个中间变量的方法。

表1 ASIC实现结果比较
从前文的算法分析可以看出,传统实现方法的关键路径上有4次加法,如果把这4次加法按树型组织,那么关键路径的延时大约为3个32bit加法器的延时;通过本文方法改进后,关键路径延时可以缩短为1个32bit加法器延时加上少量组合逻辑延时。因此理论上速度大约可以提高为传统方法的2~3倍。从表1和使用传统方法实现的文[6]对比可以发现,实现结果和理论分析完全一致。改进方法因为计算中引入了中间变量,所以面积比传统方法要略大;同时为了计算中间变量的初值,每块数据也需要多两个周期的计算。但是因为关键路径得以明显缩短,整体的计算速度大大提高,吞吐量达到传统方法的两倍以上。
通过缩短关键路径加速SHA-1计算的方法不仅适用于ASIC设计,而且一样适用于基于FPGA的硬件设计。文[6,7]是目前常用的两种SHA-1算法的商业IP核。使用本文提出的改进方法在和文[6,7]同样的FPGA芯片上(XilinxVirtex2II系列XC2V50025)实现SHA-1算法。具体结果以及和文[6,7]结果的对比见表2。
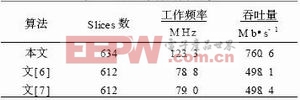
表2 FPGA实现结果比较
结论
针对有理分式拟合中的保证生成二端口网络无源性的问题,本文提出了一种简单且有效的局部补偿方法,其主要思想在于:在生成网络的Y参数矩阵的对角元素上加上(相当于并联)一个RLC串联的滤波回路,使得该回路可以以恰好补偿原网络违反无源性条件的频率段,而尽量少的引入误差。经过实验表明,该方法能很好的达到预期的目的,在保证无源性条件的同时,能使引入的误差限制在2%以内。
射频工程师养成培训教程套装,助您快速成为一名优秀射频工程师...
天线设计工程师培训课程套装,资深专家授课,让天线设计不再难...
上一篇:基于FPGA的数字三相锁相环优化设计
下一篇:通用异步串行接口的VHDL实用化设计
射频和天线工程师培训课程详情>>
