- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
使用赛灵思 FPGA加速包处理
录入:edatop.com 点击:
随着 10Gb 以太网发展趋于成熟,且业界甚至已开始期待 40GbE 和 100GbE 以太网的出现,新一代网络基础架构方兴未艾。融合型网络在流量处理方面向可扩展开放式平台提出了全新的挑战。新一代融合型基础设施底板通常由高性能兆兆位 (TB) 交换结构和可编程内容处理器构成,能够在复杂性不断增长且层出不穷的各类应用中处理应用层高达数 10 Gb 的流量。CloudShield 已创建了一系列全新的可编程包处理器,能够对包进行检测、分类、修改以及复制,融合与应用层的动态交互。
我们的流程加速子系统 (FAST) 采用 Xilinx Virtex -class FPGA 来完成为 CloudShield 深度包处理与修改 (CloudShield Deep Packet Processing and Modification) 刀片的包预处理。这些 FPGA 包含 10Gb 以太网 MAC,并为每个端口配备了用于分类及密钥提取的入口处理器 (ingress processor)、用于包修改的出口处理器 (egress processor)、使用四倍数据速率 (QDR) SRAM的包队列、基于赛灵思 Aurora 的消息传输通道以及基于三态内容可寻址存储器 (TCAM) 的搜索引擎。我们的 FPGA 芯片组能够以最少的 CPU 参与来完成包的高速缓存及处理,可实现每秒高达 40Gb 的高性能处理能力。其采用 2 至 7 层字段查询法,能够根据动态可重配置规则在线速条件下以灵活和可确定的方式进行包修改。
FAST 包处理器的核心功能
我们当前部署的深度包处理刀片采用两个刀片存取控制器 FPGA 和一个包交换 FPGA,所有这些都通过 LX110T Virtex-5 FPGA 来实施。每个刀片存取控制器都具备使用两个赛灵思10GbE MAC/PHY 内核实现的数据层连接功能、基于赛灵思 ChipSyncTM 技术的芯片间接口以及使用赛灵思 IP 核的包处理功能。包交换 PFGA 使用标准的赛灵思 SPI-4.2 IP 核来实现与我们的网络处理器 (NPU) 及我们的 IP 核搜索引擎接口相连。
为了将片上系统的设计重点集中在包处理功能上,我们尽可能使用标准的赛灵思 IP 核。我们选用赛灵思 10Gb 以太网 MAC 内核配合双 GTP 收发器来实施 4 x 3.125-Gbps 的 XAUI 物理层接口。针对 NPU 接口,我们使用了带动态相位对准与 ChipSync 技术且支持每 LVDS 差分对高达 1Gbps 速率的赛灵思 SPI-4 Phase 2 内核。我们主要的包处理 IP 核如下:
FAST 包处理器:FPP 的入口包处理器 (FIPP) 负责第一层包解析、密钥与数据流 ID 的散列生成以及按端口进行的第 3 层至第 4 层校验和验证。FPP 的出口包处理器 (FEPP) 可执行出口包修改并重新计算第 3 层至第 4 层的校验和。
FAST 搜索引擎:我们 FSE 在 TCAM 和 QDR SRAM 中维护着一个流数据库,可用于决定需要在入口包上执行的处理任务。该 FSE 可从每个端口的 FIPP 处接受密钥消息,决定针对该包需要执行的处理任务,然后将结果消息返还给原始发出消息的队列。
FAST 数据队列:我们的数据队列 (FDQ) 可在“无序”保持缓冲器中存储传送进来的包。当入口包被写入到 QDR SRAM 时,该队列将密钥消息从 FIPP 发送至 FAST 搜索引擎。该 FSE 将使用这一密钥来决定如何处理此包,然后将结果消息返还给 FDQ。根据该结果消息,队列可对每个缓冲的包进行转发、复制或丢弃处理。此外,该队列还可对已转发或已复制的包独立进行包修改。
数据流的输入与输出
图 1 显示了流经我们流量加速子系统的数据流。核心 FPGA 功能以绿色表示,包数据流为黄色,控制消息为蓝色,外部器件则为灰色。
首先,我们可从 10GbE 网络端口所接收到的包来识别客户数据流的开始。每个端口上的包都会进入 FAST 入口包处理器进行包解析与分析(图中的 1 号)。在对协议和封包进行分类之后,FIPP 可定位第 2、3 以及 4 层的报头偏移量。接下来是数据流散列与密钥抽取(数据流选择查找规则,如使用源 IP 地址、目的地 IP 地址、源和目的地端口和协议的五元组法 (5-tuple))。
此时,我们的队列管理器缓冲器负责接收包,以释放外部 QDR SRAM 的存储器页面。在此阶段接收到的包都被认为是无序的。在等待 FAST 调度的同时,我们将它们置于外部 QDR SRAM 中。FAST 数据队列(图中的 2 号)分配包 ID,并向 FAST 搜索引擎(图中的 3 号)分派密钥消息。FAST 搜索引擎使用该密钥来识别数据流。外部 TCAM 中匹配的数据流条目可在关联的 SRAM 中向数据流任务表 (Flow Action Table) 提供索引。匹配的数据流任务根据客户配置的应用订阅进行确定。
FAST 搜索引擎向 FDQ(图中的 4 号)发送结果消息进行回复,然后由任务调度程序根据其指定的任务将包分配给某个输出队列。然后我们从包队列中将包解至专用的目的地输出端口(图中的 5 号),其中我们的 FAST 出口包处理器(图中的 6 号)可根据指定任务的要求按数据流修改表 (Flow Modification Table) 中的规则处理包修改。
[p]
如果我们的 FAST 搜索引擎能够与客户数据流的匹配,则会执行指定的任务,如果不能,就执行默认的规则(丢弃或发送至 NPU)。我们允许的基本任务包括:丢弃包、将包直接转发至网络端口、将包转发给异常包处理 NPU 或复制包并依据独立规则转发包。我们的扩展任务包括包塌缩 (Packet collapse)(删除包的一部分)、包扩展/写入(在包中插入一系列字节)、包覆盖 (packet overwrite)(修改一系列字节)及其组合。以包覆盖规则为例,可以是修改MAC 源地址或目的地地址、修改 VLAN 的内或外部标记 (tag),或更改第 4 层报头标记。插入/删除的例子可以是简单到删除现有的 EtherType、插入 MPLS 标签或者 VLAN Q-in-Q 标记,也可以是复杂到需要先插入一个作为 GRE 交付报头的 IP 报头,接着紧随一个 GRE 报头(通用路由协议封装 (GRE) 是一种隧道协议,具体参阅因特网 RFC 1702 号文件)。
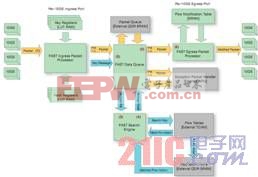
图 1 – 流加速子系统中的数据流
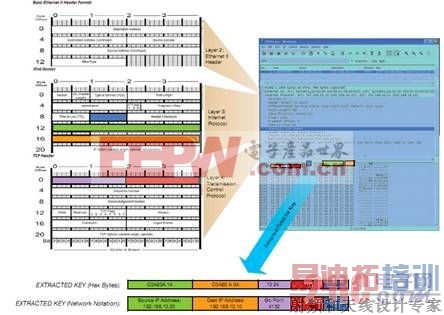
图 2 – 针对 Type II 以太网 TCP/IP 包的 5 元组密钥提取
FAST 包处理器
FAST 入口包处理器可对所有包进行解码,以确定第 2 层、3 层以及 4 层的内容(若存在)。在完成以太网第 2 层的初步解码之后,可对包进行更进一步的 2 层处理。随后我们继续进行第 3 层,处理 IPv4 或 IPv6 包。假定我们发现这种第 3 层类型的其中之一存在,我们即继续进行第 4 层处理。
在对包进行解码的同时,我们的密钥抽取单元也在定位并存储密钥字段,以生成可供我们 FAST 搜索引擎在日后用于数据流查找的搜索密钥。图 2 是 Type II 以太网 (Ethernet Type II)的 TCP/IP 包格式和待抽取的标准 5 元组密钥,此外还显示了从本例中抽取的结果密钥。
我们还可同时对入口处理器与出口处理器的各类包执行 IP、TCP、UDP 以及 ICMP 校验和计算。两个 Virtex-5 FPGA DSP48E slice 可提供校验和计算以及验证所需的加法器。我们的第一个 DSP 可在 32 位的边界内对数据流进行汇总,而第二个 DSP 则负责在相关层的计算结束时将所得总数折叠成 16 位的校验和。然后我们进行校验和的计算;对于重计算,我们可将传输进入的数据流的校验和字节位置清空,使用存储缓冲器将校验和结果的倒数重新插回。可将第 4 层校验和要求的伪报头字节多路复用到传输进入的数据流中,以用于最终计算。
每个输出端口的 FAST 出口包处理器都可根据规则表(规则存储在内部 BRAM 中)进行包修改和第 3 层至 4 层校验和的重新计算及插入。该 FEPP 超越了传统的包修改“固定功能”方案,从而能够按照指定的修改规则编号对包进行覆盖、插入、删除或者截断操作等修改。我们的数据流修改规则支持可代表操作类型的操作码规范,以 OpLoc 代表启始位置、OpOffset 代表偏移、Insert Size 代表插入的数据大小、Delete Size 代表删除的数据大小,以及是否执行第 3 层和第 4 层校验和计算和插入以及是否进行修改规则链化。
我们的新一代实施方案不仅能够显著提升性能、进一步加强高速缓冲的能力,同时还能添加新功能。通过把我们的 FAST 芯片组升级到单个的赛灵思 Virtex-6 FPGA,我们不仅能够将新一代 FAST 的功能、接口和性能提升到一个前所未有的水平,同时还能缩小板级空间并降低功耗要求,从而实现单芯片深度包处理协处理器单元。
我们能够使用包覆盖特性来简单地对诸如 MAC 目的地地址、MAC 源地址、VLAN 标记甚或是单个 TCP 标志等现有字段进行修改。
[p]
如果只需要修改 MAC 目标地址,FEPP 在接受到包时收到的“任务”将会被使用,例如,流修改表(图 3)中的规则 2。对规则 2 预先配置的内容包括:指定操作码(覆盖)、OpLoc(在包中所处的位置,比如第 2 层)、OpOffset(距离启始位置的偏移)、掩码类型(使用什么字节)以及修改数据(实际覆盖的数据)等。执行的结果是使用预先配置的修改数据覆盖从第 2 层位置开始的 6 个字节。
图 3 – 简单 MAC 目的地地址覆盖修改
另一种覆盖实例是如规则 6 所示的方案,例如我们希望修改某个特定的 TCP 标志,如 ACK、SYN 或者 FIN(参见图 4)。该规则将使用操作码(覆盖)、OpLoc(第 4 层)、OpOffset(从第 4 层开始 0 偏移)、掩码类型(使用字节 14)和位掩码(字节中的那些位需要掩蔽)。我们可以使用掩码类型来包含或是排除特定的字节,从而指定多个字段实现覆盖。

图 4 – TCP 标志的覆盖修改
我们的覆盖功能不仅限于数据流修改规则表中存储的内容,而且还能包括作为关联数据存储在数据流任务表 (Flow Action Table) 中的内容。可以通过指定规则,让传输到 FEPP 的关联数据成为任务的组成部分,从而显著扩展可用于修改的数据的范围。其结果,举例来说,是可以覆盖整个 VLAN 标记范围。
我们的插入/删除功能能够实现甚至更为复杂的包修改。以规则 5(参见图 5)为例,使用我们的插入/删除功能。包括操作码(插入/删除)、OpLoc(第 2 层)、OpOffset(从第 12 个字节开始)、ISize(插入数据大小= 22 个字节)、DSize(删除的字节大小 = 2个字节)和Insert Data(0x8847,MPLS 标签)等与规则5相关的各种任务,将删除现有的 EtherType,并插入新的 EtherType=8847,这说明新的包将是一个 MPLS 单播包,接着是由插入数据所指定的 MPLS 标签组。

图 5 – MPLS 标签插入修改
布局规划与时序收敛
在设计我们独特的包处理器过程中,我们面临的最严峻挑战是 FPGA 设计复杂程度不断增大,路由和使用密度的增加,各种 IP 核的集成,多种硬逻辑对象的使用(如 BRAM、GTP、DSP 以及类似对象),以及在项目最早期阶段的数据流规划不足等。我们发布的 Phase 1 Virtex-5 FPGA 的bit文件建立在较低的使用密度之上,特别是较低的 BRAM 使用密度基础之上,结果导致相对简单的时序收敛。在稍后阶段因为增加了新的重要功能,导致 BRAM 的利用密度接近 97%,我们开始强烈意识到优化布局规划的重要意义,以及产品生命周期初期的决策将对后期造成怎样的影响。
布局规划的主要目标通过减少路由延迟来改进时序。为此,在设计分析过程中非常重要的事情就是将数据流和管脚配置纳入考虑范围。现在已经与 ISE Y合一起的赛灵思 PlanAheadTM工具作为布局规划和时序分析的单点工具 (point tool),为我们提供了如何在高利用率的使用设计中为了实现时序收敛而需要穿越重重复杂网络的交互分析和可视化功能。PlanAhead 使我们能深入了解我们的设计,即我们需要提供最少数量的约束条件来引导映射、布置以及布线工具充分满足我们的时序要求。我们发现,要做到这一点,往往需要在基于模块的设计区域约束之外优化放置一部分关键的 BRAM。
回想起来,如果我们在项目最初阶段即花更多的时间使用 PlanAhead 来进行假定方案的验证,帮助我们看到最佳的数据流和管脚,我们在设计后期的任务就会轻松许多。
动态自适应包处理
我们的整数流加速子系统能够在最高的灵活程度下以线速检查并和修改包,同时能够动态地与应用层业务进行交互,实现高度自适应的包处理。Virtex-class FPGA 是重要的实现手段,提供了一个前一代 FPGA 无法实现的片上系统平台,加速基于内容的路由以及实施重要包处理功能。
我们的新一代实施方案不仅能够显著提升性能、进一步加强高速缓冲的能力,同时还能添加新功能。通过在单个赛灵思 Virtex-6 FPGA 中升级我们的 FAST 芯片组,我们不仅能够将新一代 FAST 的功能、接口和性能提升到一个前所未有的水平,同时还能缩小电路板空间并降低功耗要求,从而实现单芯片深度包处理协处理器单元。
射频工程师养成培训教程套装,助您快速成为一名优秀射频工程师...
天线设计工程师培训课程套装,资深专家授课,让天线设计不再难...
上一篇:Mentor
Graphics应用介绍
下一篇:PCB设计中减少谐波失真的措施
射频和天线工程师培训课程详情>>
