- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
以Talus Vortex和Talus Vortex FX解决32/28纳米IC
录入:edatop.com 点击:
前言
目前的高端ASIC/ASSP/SoC器件开发商可考虑分为三大类:主流、早期采用者和技术领导者。在写这篇文章的时候,主流开发商正致力于65纳米技术节点设计,早期采用者开发商正专注于45/40纳米节点设计,而技术领导者开发商正力求超越32/28纳米及更小尺寸节点设计。随着技术采用开发步伐的日益加快,下一代的早期采用者过渡到32/28纳米节点的时间将不会很久,而他们的主流开发商同行也将紧随其后。
进行32/28纳米节点设计时会遇到许许多多的问题,包括:低功耗设计、串扰效应、工艺变异及操作模式和角点数量的显著增加。本文首先会为您呈现微捷码Talus® Vortex 1.2物理实现流程的高层次视图,接着将介绍32/28纳米节点设计所包含的一些问题并描述Talus Vortex 1.2是如何解决的这些问题。
除了上述技术问题以外,32/28纳米节点日益提高的设计规模和复杂性还造成了工程资源(在不扩大团队规模的前提下取得更大成果,同时还保持甚至缩短现有时间表)、硬件资源(无须增加内存或购买全新设备,利用现有设备和服务器处理更大型设计)、满足日益紧张的开发时间表等方面相关问题的增加。为了解决这些问题,本文还将描述通过Talus Vortex FX创新性的Distributed Smart Sync™(分布式智能同步)技术, Talus Vortex显著地提高了其容量和性能。Talus Vortex FX 提供了首款且唯一一款分布式布局布线解决方案。
Talus Vortex 1.2物理实现流程介绍
图1所展示的是标准Talus Vortex 1.2物理流程的高层次视图。从图中,您不难观察到它先假设了芯片级网表的存在,此网表可能已通过微捷码或第三方的设计输入和综合工具而生成。

图 1. 标准Talus Vortex 1.2流程高级视图
第一步,准备好网表;这包括了各种任务,如:如确定输入/输出焊盘(I/O pad)及所有宏单元的位置。第二步,进行标准单元 布局(这是与全局布线同时进行,因为布线可能影响到单元布局,而单元布局也会对布局造成影响)。
在完成初始单元布局之后,第三步是综合时钟树, 将其添加到设计中。多数时钟树综合工具并非执行真正的多模多角(MMMC)时钟树实现,而是将时序环境分为best-case(最佳情况)和worst- case(最差情况)角点。但这种做法过于的悲观,会导致性能一直处于“毫无起色”的状态。在32/28纳米节点,实现真正的MMMC时钟树势在必行(另见后文32/28纳米主题中“MMMC问题”部分)。 因此Talus 1.2的时钟树综合部署了完整的MMMC分析,以平均10%的延迟性改善和10% 的面积缩小实现了更为先进的鲁棒性时钟系统,如图2所示
在完成初始单元布局之后,第三步是综合时钟树, 将其添加到设计中。多数时钟树综合工具并非执行真正的多模多角(MMMC)时钟树实现,而是将时序环境分为best-case(最佳情况)和worst- case(最差情况)角点。但这种做法过于的悲观,会导致性能一直处于“毫无起色”的状态。在32/28纳米节点,实现真正的MMMC时钟树势在必行(另见后文32/28纳米主题中“MMMC问题”部分)。 因此Talus 1.2的时钟树综合部署了完整的MMMC分析,以平均10%的延迟性改善和10% 的面积缩小实现了更为先进的鲁棒性时钟系统,如图2所示
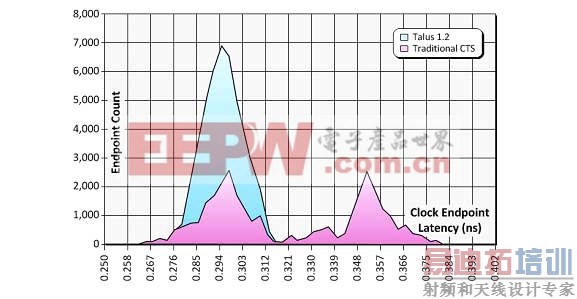
图2. 全MMMC时钟树综合实现了更为先进的鲁棒性时钟系统
一旦时钟树添加成功,那么第四步是执行复杂的优化工作。而接下来的第五步则是进行详细布线。Talus 1.2流程的收敛特性确保了详细布线结束时的时序可与流程早期所见到的时序密切吻合,甚至在考虑到串扰时也是如此(另见后文32/28纳米主题中 “串扰问题”部分)。
32/28纳米低功耗问题
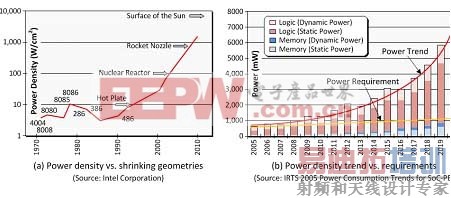
图3. 功耗是目前芯片设计最为关心的问题
工程师能够部署各种各样的技术来控制器件的动态(开关)功耗和漏电功耗。这些技术包括(但不限于)多开关阈值(multi-Vt)晶体管的使用、多电源多电压(MSMV)、动态电压与频率缩放(DVFS)及电源关断(PSO)。
在多开关阈值晶体管情况下,非关键时序路径上的单元可由漏电量较低、功耗较少、开关速度较慢的高开关阈值(high-Vt)晶体管来组成;而关键时序路径上的单元则可由漏电量较高、功耗较多、开关速度显著加快的低开关阈值(low-Vt)晶体管来组成。
多电源多电压(MSMV)所包括的芯片可分为不同区域(有时称为“电压岛”或“电压域),不同区域拥有不同的供电电压。分配到较高电压岛的功能块将拥有较高性能和较高功耗;而分配到较低电压岛的功能块则将拥有较低性能和较低功耗。
动态电压与频率缩放(DVFS)技术的使用是通过改变一个或多个功能块的相关电压或频率来优化性能与功耗间折衷权衡。例如:1.0V的额定电压在功能块活动率低时可降至0.8V以降低功耗,或在需要时它也可以提至1.2V以提高性能。同样地,额定时钟频率可在功能块活动率相对低时减至一半,或它也可增强一倍以满足短时间爆发的高性能需求。
顾名思义,电源关断(PSO)系指切断选定的目前不在使用中的功能块的电源。尽管这项技术在省电方面效果非常好,但它需要考虑到的问题真的很多,如:为避免造成电流浪涌,要按特殊顺序给相关功能块的供电和关电。
Talus Vortex 1.2提供了一款完整的集成化低功耗解决方案,包括一种自动化低功耗综合方法,可与跨多电压和频率区域的并行分析与优化功能结合使用。 Talus 1.2不仅不会对所使用的不同晶体管开关阈值的数量进行限制,同时还支持无限的电压、频率和电源切断区域。此外,Talus 1.2完全支持通用功率格式(CPF)和统一功率格式(UPF)。这两种格式让设计团队能够先从功耗角度出发把握设计意图,然后再推动下游规划、实现和验证策略(见侧边栏)。
在多开关阈值晶体管情况下,非关键时序路径上的单元可由漏电量较低、功耗较少、开关速度较慢的高开关阈值(high-Vt)晶体管来组成;而关键时序路径上的单元则可由漏电量较高、功耗较多、开关速度显著加快的低开关阈值(low-Vt)晶体管来组成。
多电源多电压(MSMV)所包括的芯片可分为不同区域(有时称为“电压岛”或“电压域),不同区域拥有不同的供电电压。分配到较高电压岛的功能块将拥有较高性能和较高功耗;而分配到较低电压岛的功能块则将拥有较低性能和较低功耗。
动态电压与频率缩放(DVFS)技术的使用是通过改变一个或多个功能块的相关电压或频率来优化性能与功耗间折衷权衡。例如:1.0V的额定电压在功能块活动率低时可降至0.8V以降低功耗,或在需要时它也可以提至1.2V以提高性能。同样地,额定时钟频率可在功能块活动率相对低时减至一半,或它也可增强一倍以满足短时间爆发的高性能需求。
顾名思义,电源关断(PSO)系指切断选定的目前不在使用中的功能块的电源。尽管这项技术在省电方面效果非常好,但它需要考虑到的问题真的很多,如:为避免造成电流浪涌,要按特殊顺序给相关功能块的供电和关电。
Talus Vortex 1.2提供了一款完整的集成化低功耗解决方案,包括一种自动化低功耗综合方法,可与跨多电压和频率区域的并行分析与优化功能结合使用。 Talus 1.2不仅不会对所使用的不同晶体管开关阈值的数量进行限制,同时还支持无限的电压、频率和电源切断区域。此外,Talus 1.2完全支持通用功率格式(CPF)和统一功率格式(UPF)。这两种格式让设计团队能够先从功耗角度出发把握设计意图,然后再推动下游规划、实现和验证策略(见侧边栏)。
32/28纳米串扰问题
时钟频率的持续提高与供电电压的日益降低意味着对串扰型延时变化、功能失效等信号完整性(SI) 效应的敏感度在不断提高。在32/28纳米节点,由于更近的相邻轨道、横截面(32/28纳米节点的轨道的高度可能大于其宽度,如图4 所示,它增大了相邻轨道耦合电容)以及金属化的轨道和通孔的电阻的提高(相对而言),因此这些效应也进一步增强。
时钟频率的持续提高与供电电压的日益降低意味着对串扰型延时变化、功能失效等信号完整性(SI) 效应的敏感度在不断提高。在32/28纳米节点,由于更近的相邻轨道、横截面(32/28纳米节点的轨道的高度可能大于其宽度,如图4 所示,它增大了相邻轨道耦合电容)以及金属化的轨道和通孔的电阻的提高(相对而言),因此这些效应也进一步增强。
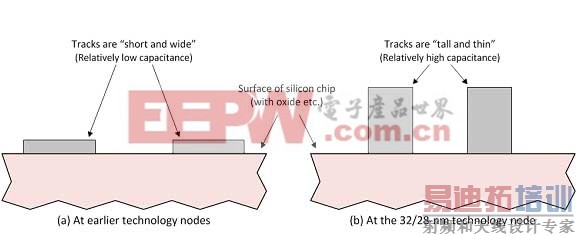
图4. 32/28纳米节点轨道的高度可能超过其宽度。
Talus 1.2以基于轨道的复杂优化算法而著称,它使得用户在流程更早期的全局布线期间就可解决串扰问题。Talus 1.2解决串扰相关问题的方式有很多,最基本的方式是使用最佳层分配和通过可用资源的扩散布线;它会有效管理这种扩散以避免对线长或通孔数量造成的显著负面影响。此外,全局布线器自带有多线程功能,可获得超高的性能水平。
为了获得高性能,所有全局布线器会先做假设。如 :在“桶(bucket)”中放置导线,每个“桶”中的导线都设置于相互的顶部,因此一开始就可以直观地看到。在多数环境中,流程下游的轨道的真正排序和布局工作是留待详细布线器来完成。而解决流程下游的串扰问题要花费多上一个数量级的精力,而且按需修复(如:上调单元的尺寸会伴随面积和漏电功耗的相应增加)可能不是最佳、乃至可完成的方法。
事实上,只有在知道轨道排序及其空间关系时才有可能精确评估潜在的串扰效应。因此Talus 1.2将全局轨道区段转换为空间上可布局的区段,然后再使用这一区段在流程更早期就对潜在的串扰问题进行评估;这样通过在全局布线阶段对线路的重新排序和设置, 所有的串扰问题都可以在流程的更早阶段得到解决。在全局布线阶段所做的这些修改接下来还可用于为流程下游的详细布线器提供指导,这样便可以少得多的计算工作获得更优的解决方案。
32/28纳米工艺变异问题
对于以180纳米及更高技术节点制造的硅芯片来说,所需的只是解决些少量晶圆间变异,即源自不同晶圆的晶粒在时序(性能)、功耗等特征方面的差异。这种差异可能是由于从一家代工厂到另一家代工厂的制程变异和仪器及操作环境微小差异所造成,如:炉温、掺杂程度、蚀刻浓度、用以形成晶圆的光刻掩膜等等。
在较高技术节点时,所有晶粒间工艺变异(同一晶圆上各晶粒间差异)和晶粒内工艺变异(同一晶粒上各区域间差异)相对来说并没那么重要。(晶粒间变异也被称之为“全局”、“芯片到芯片”、“晶粒到晶粒”变异。)例如:如果一个芯片的核心电压为2.5V,那么在多数情况下会假设整个晶粒拥有一致和稳定的 2.5V电压; 同样的也会假设整个晶粒上拥有统一的芯片温度。
随着尺寸越来越小的新技术节点浮出水面,晶粒间与晶粒内工艺变异变得日益重要。这些变异中有些是系统变异,这意味着它会随着单元级电路功能而改变。例如:晶圆片中心附近所制造的芯片与朝向晶圆片边缘所制造的芯片相比,其相关的某些参数可能会有所不同;在这种情况下,可以预测所有参数都将受到类似影响;而一些参数还会在随机变异的情况下独立地波动,据说这可能是基于区域的变异(相对于基于距离的变异)。
对于以180纳米及更高技术节点制造的硅芯片来说,所需的只是解决些少量晶圆间变异,即源自不同晶圆的晶粒在时序(性能)、功耗等特征方面的差异。这种差异可能是由于从一家代工厂到另一家代工厂的制程变异和仪器及操作环境微小差异所造成,如:炉温、掺杂程度、蚀刻浓度、用以形成晶圆的光刻掩膜等等。
在较高技术节点时,所有晶粒间工艺变异(同一晶圆上各晶粒间差异)和晶粒内工艺变异(同一晶粒上各区域间差异)相对来说并没那么重要。(晶粒间变异也被称之为“全局”、“芯片到芯片”、“晶粒到晶粒”变异。)例如:如果一个芯片的核心电压为2.5V,那么在多数情况下会假设整个晶粒拥有一致和稳定的 2.5V电压; 同样的也会假设整个晶粒上拥有统一的芯片温度。
随着尺寸越来越小的新技术节点浮出水面,晶粒间与晶粒内工艺变异变得日益重要。这些变异中有些是系统变异,这意味着它会随着单元级电路功能而改变。例如:晶圆片中心附近所制造的芯片与朝向晶圆片边缘所制造的芯片相比,其相关的某些参数可能会有所不同;在这种情况下,可以预测所有参数都将受到类似影响;而一些参数还会在随机变异的情况下独立地波动,据说这可能是基于区域的变异(相对于基于距离的变异)。

图5.在32/28纳米节点,晶粒间与晶粒内变异极为重要。
晶粒间与晶粒内工艺变异统称为片上变异 (OCV),在32/28纳米节点变得极为重要。这是由于随着每个新技术节点的推出,控制如晶体管结构的宽度和厚度、轨道和氧化层等关键尺寸变得更为困难,最终导致相对变异百分率(与某些中值相比较)会随着每个新的技术节点而变得更大。
解决OCV的传统方式是使用一阶方案(first-order approach),包括在整个芯片上应用一揽子容限。不过在32/28纳米节点,这种方法过于悲观,会导致过度设计、设计性能降低和时序收敛周期变长。因此Talus 1.2部署了复杂的高级OCV (AOCV)算法,基于单元和轨道的邻近性(如:两个相邻单元与位于晶粒相反两端的两个单元相比较,相互间相关潜在变异会更少)来应用上下文特定的降额值。这种更为实际的模式可降低超额的容限,进而减少悲观的时序违规并提高器件性能。
32/28纳米多模多角(MMMC)问题
除了前文主题中所提及的制造工艺的变异以外,我们还必须解决芯片使用的环境条件(如:电压和温度)存在的潜在变异问题。所有这些变异均可归入PVT(工艺、电压和温度)项目范围。
对于以更早期技术节点所创建的器件来说,晶粒间与晶粒内PVT差异可以忽略不计。先做假设,然后基于整个芯片表面具有一致的工艺变异这一事实、基于整个晶粒上具有稳定的核心电压和温度等环境条件这一事实来简化工作是有可能的。基于这些假设,通过采用一系列bese-case条件(最高允许电压、最低允许温度等),确定每条路径bese-case(最小)延时会相对容易;同样的,通过采用一系列worst-case条件(最低允许电压、最高允许温度等),确定每条路径worst-case(最大)延时也会相对容易。
32/28纳米多模多角(MMMC)问题
除了前文主题中所提及的制造工艺的变异以外,我们还必须解决芯片使用的环境条件(如:电压和温度)存在的潜在变异问题。所有这些变异均可归入PVT(工艺、电压和温度)项目范围。
对于以更早期技术节点所创建的器件来说,晶粒间与晶粒内PVT差异可以忽略不计。先做假设,然后基于整个芯片表面具有一致的工艺变异这一事实、基于整个晶粒上具有稳定的核心电压和温度等环境条件这一事实来简化工作是有可能的。基于这些假设,通过采用一系列bese-case条件(最高允许电压、最低允许温度等),确定每条路径bese-case(最小)延时会相对容易;同样的,通过采用一系列worst-case条件(最低允许电压、最高允许温度等),确定每条路径worst-case(最大)延时也会相对容易。

图6. 在 32/28纳米节点需要解决大量模式和角点。
如worst-case和best-case PVT等特定系列条件就是我们俗称的“角点”。在32/28纳米技术节点,晶粒间与晶粒内PVT差异十分明显,解决大量模式和角点的工作是必不可少的。而且,前文提过的低功耗设计技术还会让这一问题进一步复杂化。例如:在多电源多电压(MSMV)技术情况下,可能一个电压岛的电压值为其允许电压范围内最低电压,另一个电压岛的电压值为其允许电压范围内最高电压,而其余电压岛的电压值则会在这两者之间 。又如:有的芯片具有不同操作模式、拥有的一个或多个电路模块位于在电源切断的晶粒中心都将导致所需分析的角点情况显著增加。
目前工具的问题在于:实现期间 ,芯片必须可在MMMC前景下进行优化 。许多现有系统通过先考量已假设的worst-case情景、然后对别的条件进行优化的方式来着手处理优化问题。遗憾的是,这可能导致过度悲观主义,造成次优性能。甚至更糟的是,如果这些关于哪些是worst-case情景的假设是错误的,那么结果可能是得到完全不管用的芯片。 Talus 1.2内置有自带MMMC处理功能,这意味着优化过程不会漏掉任何情景。此外,Talus 1.2的高速度和大容量还意味着,它能够考虑到的不只是较小子集的实现情景,而是这款工具需要处理的整个系列的签核情景。因此,Talus 1.2可提供更好的性能和更短的实现周期。
以 Distributed Smart Sync技术增强Talus Vortex的性能
前文所提及的物理实现流程每个步骤都是属于计算密集型问题。而且为了解决伴随技术节点而增加的复杂性,每个节点必须执行的计算量也在提高。此外,当器件中所集成的功能越来越多时, 设计的规模和复杂性会随着每个节点而提高,物理实现相关的计算需求也会相应增加。
再有一个因素就是:功能模块的尺寸(为实现模块功能所需的单元数量)也会随着每项功能中包装进越来越多特性而不断增加。一些物理实现团队偏爱层次化方案,而另外一些团队则更喜欢使用“扁平化”方案,因为他们感觉在使用层次化方案时放弃了太多东西。
如果工具具有处理更大型电路模块的能力,那么生产率就可得到即时的提升。例如:定义和微调层次化模块间约束是极为耗时的资源密集型工作。如果这些工具具有处理更大型电路模块的能力,那么就不需要定义子模块间约束,因为不会有任何子模块存在。这会大大提高生产率。
问题在于:多数布局布线解决方案都局限于只能处理几百万个单元。这常迫使物理实现工程师由于工具的局限性而不得不人工将电路模块进行分割。而这也对工程师生产率造成了影响。.[p]
除非通过某些方式进行增强,不然的话即便目前最先进的Talus 1.2布局布线解决方案的实际容量也只在200万到500万个单元之间,所提供的生产率为每天100-150万单元。结果会造成一种由容量驱动的生产率差距。为了处理32/28纳米节点设计,实现包括1000万以上个单元的扁平电路模块是必不可少的,如图7所示(另见侧边栏)。
目前工具的问题在于:实现期间 ,芯片必须可在MMMC前景下进行优化 。许多现有系统通过先考量已假设的worst-case情景、然后对别的条件进行优化的方式来着手处理优化问题。遗憾的是,这可能导致过度悲观主义,造成次优性能。甚至更糟的是,如果这些关于哪些是worst-case情景的假设是错误的,那么结果可能是得到完全不管用的芯片。 Talus 1.2内置有自带MMMC处理功能,这意味着优化过程不会漏掉任何情景。此外,Talus 1.2的高速度和大容量还意味着,它能够考虑到的不只是较小子集的实现情景,而是这款工具需要处理的整个系列的签核情景。因此,Talus 1.2可提供更好的性能和更短的实现周期。
以 Distributed Smart Sync技术增强Talus Vortex的性能
前文所提及的物理实现流程每个步骤都是属于计算密集型问题。而且为了解决伴随技术节点而增加的复杂性,每个节点必须执行的计算量也在提高。此外,当器件中所集成的功能越来越多时, 设计的规模和复杂性会随着每个节点而提高,物理实现相关的计算需求也会相应增加。
再有一个因素就是:功能模块的尺寸(为实现模块功能所需的单元数量)也会随着每项功能中包装进越来越多特性而不断增加。一些物理实现团队偏爱层次化方案,而另外一些团队则更喜欢使用“扁平化”方案,因为他们感觉在使用层次化方案时放弃了太多东西。
如果工具具有处理更大型电路模块的能力,那么生产率就可得到即时的提升。例如:定义和微调层次化模块间约束是极为耗时的资源密集型工作。如果这些工具具有处理更大型电路模块的能力,那么就不需要定义子模块间约束,因为不会有任何子模块存在。这会大大提高生产率。
问题在于:多数布局布线解决方案都局限于只能处理几百万个单元。这常迫使物理实现工程师由于工具的局限性而不得不人工将电路模块进行分割。而这也对工程师生产率造成了影响。.[p]
除非通过某些方式进行增强,不然的话即便目前最先进的Talus 1.2布局布线解决方案的实际容量也只在200万到500万个单元之间,所提供的生产率为每天100-150万单元。结果会造成一种由容量驱动的生产率差距。为了处理32/28纳米节点设计,实现包括1000万以上个单元的扁平电路模块是必不可少的,如图7所示(另见侧边栏)。

图 7. 物理实现工具对扁平容量需求永不满足。
在过去,一直是通过提供多线程功能来增强物理实现工具的容量和性能。在有些情况下,这些功能是被“生搬硬套”到的传统工具上,效果有限。相较之下,Talus 1.2中所有工具均完全内置有自带的多线程功能。
前文已说过,多线程对工具的作用十分有限;基于阿姆达尔定律(Amdahl’s law)等计算机科学定律,(伴随在其核心运行的每个线程)线程的数量越来越多所起到的效果却越来越小。简单来说,就是告诉我们,任何程序的加速均会受到并行数量的限制(也就是说,程序的最长序列片断关系到程序的其它部分),如图8所示。

图 8. 阿姆达尔定律反映了多线程的局限性。
对于被用来创建ASIC/ASSP/SoC器件的物理实现工具来说 ,这些工具的并行部分约占到了50%到75%。就如我们从图8中所看到的“ 甜蜜点(sweet spot)”, 而在best-case情景下, 使用8-10个处理核心,只可获得约3倍的加速。
幸运的是,通过将物理实现任务分发到多台机器上就可以克服阿姆达尔定律所定义的局限性。如图9所示,采用全新Distributed Smart Sync(分布式智能同步)技术的Talus Vortex FX提供了与贯穿物理实现流程所有步骤(时钟树综合除外,这种方法对它起不了什么作用)的智能同步技术相结合的独特分布式管理。微捷码将这款最新解决方案称为Talus Vortex FX,它以Distributed Smart Sync技术增强了Talus 1.2。

图 9. 经istributed Smart Sync[p]
技术增强的Talus Vortex FX流程的高级视图
这种技术背后的概念是:对一个更大型的设计或模块进行智能分割、将设计分区分散到整个网络的服务器上执行设计实现、最后在主要流程阶段自动对这些设计实施重新同步。本质上,这让设计师能够处理更大型设计,同时仍可获得与他们之前在规模更小得多的电路模块上所实现的相同的吞吐量(即每天单元数)。甚至在使用同等数量的内核/线程的时候,这种分布式方案的处理速度也较最佳多线程扁平流程要快上2-3倍。
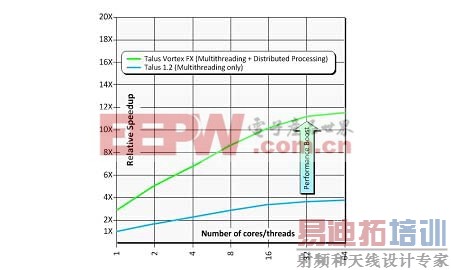
图10. 仅多线程 vs. 多线程+分布式处理
物理实现工程师的生产率一般是根据每天单元数来进行衡量。使用最好的常规流程,可能获得的最大生产率一般约为每天100万个单元。相较之下,Talus Vortex FX的分布式处理技术可将这一数字提高到每天200-500万个单元, 这种技术贯穿整个流程(对于只布局的门极电路而言, 生产率可获得更高的提升,这是一些用户会关注的另一指标)。[p]
还值得关注的是: Talus Vortex FX为物理实现团队提供了在设计周期早期执行快速的假设分析的能力,实现了最佳的面积、速度和功耗间折衷权衡。但还有一点也不容忽视:Distributed Smart Sync技术完全增强了现有Talus 1.2技术,进而促进了这款产品的快速采用。
至于保留现有硬件资源的投资方面,Distributed Smart Sync技术让用户现有的内存为 32 GB和64 GB的设备能够得到充分利用。若未采用这项技术而转向32/28纳米节点设计,那么将要求用户的设备要升级为内存128 GB 或256 GB的设备,碰到大型服务器场的话这可能需耗费几百万美元。
除了通过缩短设计周期、提高工程团队使用扁平方法的能力(在不必添加额外资源的前提下)、提高工程团队的生产率以外,Talus Vortex FX的使用通过缩短上市时间(赢利时间)还解决了如何满足日益紧张的开发时间表这一问题。
总结
进行32/28纳米及更小尺寸技术节点设计时会遇到许许多多的问题,包括低功耗设计、串扰效应、工艺变异以及操作模式和角点数量的显著增加。微捷码的 Talus Vortex 1.2物理实现环境完全解决了所有这些问题。
此外, 32/28纳米节点设计尺寸及复杂性的不断提高还造成了工程资源(不扩大团队规模而取得更大成果)、硬件资源(无需升级主板、增加内存或购买全新设备,使用现有设备和服务器场来处理更大型设计)和如何满足日益紧张开发时间表等方面相关问题的增加。为了解决这些问题,通过Talus Vortex FX创新性的Distributed Smart Sync™(分布式智能同步)技术, Talus Vortex显著地提高了其容量和性能。
射频工程师养成培训教程套装,助您快速成为一名优秀射频工程师...
天线设计工程师培训课程套装,资深专家授课,让天线设计不再难...
上一篇:下一代STA工具Tekton
下一篇:平台ASIC架构突破传统ASIC设计局限性
射频和天线工程师培训课程详情>>
