- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
LTE中卷积码的译码器设计与FPGA实现
录入:edatop.com 点击:
摘要:基于长期演进(LTE)的Tail-biting卷积码,介绍了维特比译码算法,它是一种最优的卷积码译码算法。由于Tail-biting卷积码的循环特性,采用固定延迟译码的方法,降低了译码复杂度。通过使用全并行的结构及简单的回溯存储方法,设计了一个具有高速和低复杂度的固定延迟译码器。在FPGA上实现并验证,验证结果表明译码器的性能满足了LTE系统的要求。
关键词:LTE;Tail-biting卷积码;维特比译码算法;固定延迟译码;FPGA
0 引言
LTE(Long Term Evolution)是“准4G”的技术,以OFDM/FDMA和MIMO为其核心技术。它对实时业务、高可靠性业务和广播级多播业务都能提供较好的支持。LTE在20 MHz频谱带宽下能够提供下行100 Mb/s和上行50 Mb/s的峰值速率,高速率对信道编码和译码技术提出了更高的要求。
对于LTE低时延、高速率和高可靠性的要求,降低译码的实现复杂度和时延以及提高其可靠性对LTE系统性能就显得极其重要,也是一个巨大的挑战。
1 LTE中Tail-biting卷积码
卷积码通常用(n,k,N)表示。其中k表示输入编码器的数据位数;n表示编码器输出的数据位数;N为编码约束长度,R=k/n是卷积码的码率。
LTE中使用的Tail-biting卷积码编码器结构如图1所示。其约束长度N=7,码率R=1/3。
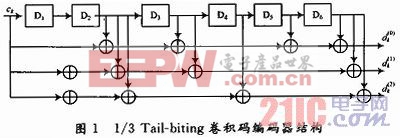
编码器移位寄存器的初始状态值被设置为相应的输入数据流的最后6个信息比特,以至于移位寄存器的初始状态和结束状态相同。
图1中,D6D5D4D3D2D1表示编码器的状态索引(State Index);ck表示输入数据比特;![]() 表示输出数据比特。
表示输出数据比特。
卷积码网格图中的蝶形结构,如图2所示。
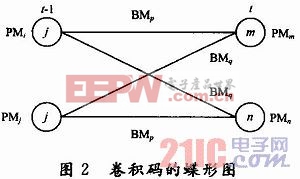
随着编码比特的输入,编码器状态的转移过程,由图2可以看出,时刻t-1的两个相关状态Si和Sj转移到时刻t的两个状态Sm和Sn。图中,PM和BM分别表示路径度量和分支度量,其中BM的下标为输出比特![]() 的组合。
的组合。
2 Tail-biting卷积码的译码算法
维特比算法的实质是最大似然译码,它是在卷积码的网格图中寻找一条与编码路径最接近的最大似然路径作为其最终译码输出。在译码的每个时间单元,把网格图上各个分支的度量加到前面状态的路径度量上,比较进入每个状态的所有分支的度量,选择具有最大度量的分支,即幸存路径,迭代上述步骤,最终输出最大似然路径作为其译码输出。
维特比算法主要由三部分组成:分支度量(Branch Metric,BM)模块、加比选(Add Compare Select,ACS)模块和回溯(Trace Back,TB)模块。
直接运用维特比算法对Tail-biting卷积码进行译码,其译码复杂度大,不利于硬件实现。为了能降低译码复杂度,用固定延时译码(Fixed Delay Decoding)算法,它是利用Tail-biting卷积码的循环特性,也就是编码输入的开始部分能用来估计译码网格图的最后状态,执行译码操作用的固定延时。
如有一段长为L的软判决数据,选择原数据的后LH个软判决比特,将其放置在数据头部,选择原数据的前LT个软判决比特,将其放置在数据尾部,最后形成长为LH+N+LT的待译码软判决数据。将它用Viterbi算法译码,在译码数据中丢弃前LH个比特和后LT个比特,即为所需译码数据。其中LH和LT分别称为头译码长度(Head Decoding Length)和尾译码长度(Tail Decoding Length),为此算法中需要决定这两个重要参数。
[p]
3 译码器的设计与实现
在译码器的设计中,采用固定延迟算法。首先对进入译码器之前的软判决数据进行处理,如图3所示。
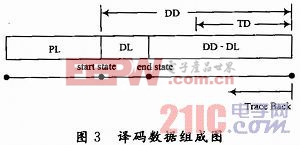
将其处理成图中所示的待译码数据格式,其中DL是实际输入的所需译码数据长度,PL为所需在数据中加的数据前缀长度,也即上述固定延迟算法中的头译码长度,DD为所要达到的译码深度(Decoding Depth),DD-DL为所要加的后缀长度,即固定延迟算法中的尾译码长度。在设计中选择PL为96,由于在LTE系统中DL是变化的,最大为76,不能够选择固定的尾译码长度,但在本文设计中选择固定的DD为192。
译码器的整体设计框图,如图4所示。图中译码器主要由译码器系统控制模块,分支度量(BM)模块,加比选(ACS)模块,回溯(TB)模块和输出缓存组成。
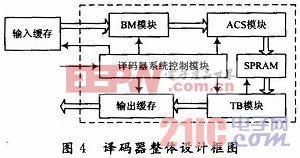
数据处理由译码器系统控制模块控制完成,它控制从输入缓存中读入数据进行译码。
下面对译码器BM模块、ACS模块和TB模块这三个核心模块的具体设计与实现进行详细介绍。
3.1 BM模块
在整个系统中分支度量采用的是软判决数据。软判决根据接收的的软判决比特和编码器网格图的参考分支,计算其欧氏距离。一般的欧氏距离采用如下公式计算:
![]()
式中:ri为接收的软判决比特;ci为编码器网格图的参考分支。上述公式经简化后结合系统所用软判决数据特点,可以得到如下计算方法:

式中:Ri为接收的软判决比特的绝对值;Ci∈{0,1)为参考分支比特。
3.2 BM模块
在每一个时钟中,用得到的分支度量(BM)和路径度量(PM)相加,得到下一时刻状态的多个路径度量,通过比较,选择一个幸存分支。将每个状态的幸存分支,存储到回溯存储器中,更新路径度量。在设计中,存储从数据段(即图4中的Initial State)开始,在这之前的幸存分支不需存储。同时,计算出64个状态中,具有最小路径度量的状态。
如果直接将前一状态的路径度量与分支度量相加,得到下一状态的路径度量,来选择幸存分支,如图2中,比较PMi+BMp和PMj+BMq选择幸存分支。每个状态2个加法器,64个状态就需要128个加法器。[p]
由于网格图的蝶形结构,可以比较PMi-PMj和BMq-BMp(即如果PMi+BMp>PMj+BMq,可以将其写为PMi-PMj>BMq-BMp),这样对于每一对相关状态可以重复使用这两项,在这个过程中需要用到32个加法器。通过这种方法,可以明显减少ACS模块中的加法器数量。
更新路径度量的操作设计如下,编码器的状态转移过程如图2中蝶形结构所示,蝶形结构中两个相关状态转移到两个新状态。
两个相关状态对应的用状态索引分别为i=OD5D4D3D2D1和j=1D5D4D3D2D1,两个新状态可以分别表示为m=D5D4D3D2D10和n=D5D4D3D2D11。即,状态i=0D5D4D3D2D1,如果输入比特0,转移到状态m=D5D4D3D2D10,如果输入是比特1,转移到状态n=D5D4D3D2D11;状态j=1D5D4D3D2 D1,如果输入比特0,转移到状态m=D5D4D3D2D10,如果输入比特1,转移到状态n=D5D4D3D2D11。根据上面的转移状态关系,更新状态的路径度量。
对于幸存分支的存储表示,本文采取如下方法,状态m=D5D4D3D2D10,如果由状态i=0D5D4D3D2D1转移而来,那么此幸存分支取状态的最高有效比特0;如果由状态j=1D5D4D3D2D1转移而来,此幸存分支取状态的最高有效比特1。同样,状态n=D5D4D3D2D11,如果由状态i=0D5D4D3 D2D1转移而来,此幸存分支用0表示;如果是由状态j=1D5D4D3D2D1转移而来,此幸存分支用1表示。每个时刻,经过ACS选出64个状态所对应的幸存分支,存入回溯存储器。
3.3 BM模块
回溯算法,由于已经将每个时钟下所有状态的幸存分支存储在回溯存储器里,在达到译码深度DD后,开始对整个幸存分支进行回溯,如图3所示。当达到回溯深度(Trace Back Depth)后,幸存路径就开始合并,就开始输出译码数据。
回溯指针是卷积码编码逆过程的状态索引。回溯指针的具体建立过程如下:回溯开始时,由ACS中计算的最小度量状态的状态索引作为初始回溯指针,从回溯存储器中读出的所有64个状态的幸存分支中,选出该回溯指针对应的幸存分支,形成下一个回溯指针,以此在回溯过程中循环向前,在每一时钟中形成回溯指针。
由幸存分支的存储表示可以得出,回溯指针m=D5D4D3D2D10,如果该指针对应的幸存分支为比特0,那么下一个回溯指针为i=0D5D4D3D2 D1,如果对应的幸存分支为比特1,那么下一个回溯指针为j=1D5D4D3D2D1;同理,回溯指针n=D5D4D3D2D11,如果幸存分支为比特0,下一个回溯指针为i=0D5D4D3D2D1,如果幸存分支为比特1,那么下一个回溯指针为j=1D5D4D3DzD1。
在该设计中,最重要的是译码深度(DD)的选择,译码深度能够决定所用的回溯存储器得深度。结合数据前缀的固定延迟操作,采用一个单端口RAM(SPRAM),大小为96×128 b,如图5所示。
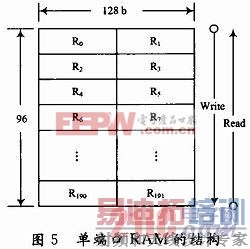
在一个译码周期里,数据前缀译码结束,从数据段(即图3所示start state)开始,每2个时钟往SPRAM里写1次这两个时钟分别产生的幸存分支,共128 b,如图5所示,即顺序写入数据R0R1,R2R3,R4R5,……,往SPRAM里写数据共需192个时钟。在达到译码深度后,开始回溯,读出SPRAM里幸存分支,每个时钟读出两个连续幸存分支,进行回溯指针的操作,在回溯深度后就会合并为一条幸存路径,直到回溯完成,共需96个时钟。在回溯的同时,如有数据输入译码器,开始下一个周期的译码,在回溯操作从SPRAM读数据的96个时钟里,用来译码数据前缀,在数据段开始时往SPRAM里写数据,同时回溯操作的读数据也已完毕。
从SPRAM里读出的数据R(DL+5)~R6(DL为数据长度)中的幸存路径,即为译码比特,输出到输出缓存中。根据系统需要,译码比特输出到输出缓存完成后,一次将最终的译码数据输出。
4 FPGA验证
该设计采用Verilog HDL语言编写代码,使用Quartus 9.0综合,并在Altera公司的StratixⅢEP3SL340F151713型号的FPGA上验证,该设计的译码器能达到135.78 MHz的速度,使用FPGA资源为4 992个ALUTs。
5 结语
本文设计的译码器,利用Tail-biting卷积码的循环特性,采用固定延迟的算法与维特比算法结合,使其硬件实现更简单,采用并行结构以及简单的回溯存储器方法,显著提高译码器速度。在设计各个子模块时,优化了硬件结构,减少占用资源和降低功耗,使其整体性能更优。
本文设计的译码器在FPGA上实现和验证,能达到135.78 MHz时钟,该译码器达到了LTE系统所要求的122.88 MHz时钟要求,达到了LTE系统所要求的整体性能,并已应用到ASIC芯片设计中。
射频工程师养成培训教程套装,助您快速成为一名优秀射频工程师...
射频和天线工程师培训课程详情>>
