- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
从Multicore到Many-Core:体系结构和经验
录入:edatop.com 点击:
您可能已经习惯了芯片系统(SoC)的multicore处理器这一概念,而现实却总是在不断变化。8月份举行的Hot Chips大会研讨中,已经清楚的表明multicore正在向many-core发展:在SoC核心位置,密切相关的处理器内核的数量在不断增长,从2个或者4个增加到8个、16个,甚至是很多,很多。
这种增长仅是摩尔定律发展的另一阶段,系统开发人员还是能清楚的了解这一切吗 从multicore发展到many-core是类型的变化,还是仅仅是规模的变化 这种转变能解决系统开发人员面临的问题吗
为找到这些问题的答案,我们与一些团队进行了交流,他们已经在many-coreSoC开发上积累了一些设计经验。我们向他们提出了一个简单的问题:您的体验与使用multicore有什么不同吗 对于这一简单的问题,我们得到了各种各样的回答。
Many-core的发展
Hot Chips的论文列出了SoC体系结构向many-core领域发展的三条主要路线。我们从Cavium的Kin-Yip Liu在小规模无线基站SoC设计论文中阐述的路线开始,这些设计包括微基站、微微基站和毫微微基站。
名为Octeon Fusion CNF71xx的设计如 图1所示,包括两个处理簇,含有四个一组的增强MIPS64内核,以及围绕一个共享L2高速缓存的各种硬件加速器,还有6个为一组的数字信号处理(DSP)内核,每个内核都有很多硬件加速器,这些内核分布在共享存储器交换架构周围。
图1.Cavium的Octeon Fusion体系结构结合了CPU簇以及相连接的硬件加速器和分立的DSP内核簇。
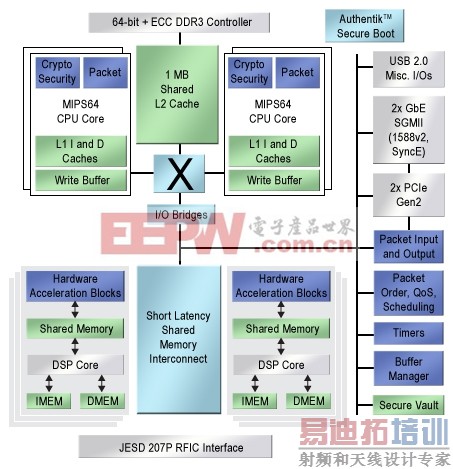
四个CPU还很难说明是many-core设计。但是有两个很好的理由让我们的讨论从这一芯片开始。首先,增加6个DSP内核使得芯片成为10核异构体系结构,表面上看已经进入many-core领域。其次,更多的是在理论上,Cavium使用内核的方式与传统的multicore并不相同。
Multicore SoC将线程映射至内核的方式一般是静态的。而随着内核数量的增加,这种映射更具流动性。CPU和DSP可以按数据流来划分,也可以构成虚拟流水线,每一个完成复杂任务的几级任务。或者,处理器可以观察任务序列,一旦空闲,就可以执行新任务。不断增强一个处理器的能力来完成所有数据的处理,而这一概念正在转向由很多处理器共同完成一项工作——从固定硬件到软件与加速器的组合。这种概念上的变化确定了multicore与many-core计算之间的边界。我们看到这种变化是从本地对称的Octeon Fusion体系结构开始的。Cavium很显然同意这一观点。他们在Hot Chips上的研讨表明,目前的芯片只是软件兼容系列的开始,这些系列能够从单核发展到48核。
作为对比,Fujitsu的Takumi Maruyama发表的论文介绍了公司的16核芯片SPARC64 X将成为服务器中心处理器。SPARC64 X与Octeon共享了一个重要的体系结构概念:16个SPARC内核簇围绕一个大规模内核——24 Mbyte,共享L2高速缓存。但这也有很大的不同。这就是专用硬件加速器。Fujitsu将其称之为“芯片软件”。Fujitsu没有在CPU之外开发松耦合加速器,来处理棘手的运算问题(在这个例子中,十进制数学运算、加密和数据库函数等),而是开发了新的RISC类型指令来加速这些运算,在每一CPU的浮点单元流水线中增加了必要的执行硬件。因此,硬件加速并不能灵活的共享L2高速缓存,或者链接系统总线,而是成为CPU不可缺少的组成部分。实际上,这些加速器增加了指令,编译器可以将其优化到CPU指令流中。
Intel和many-core
最后,考虑Intel的Xeon Phi,或者还可以考虑Intel资深首席工程师George Chrysos所介绍的Knights Corner,如 图2 所示。在Chrysos有些含糊的描述中,该器件是采用了“50多个”x86处理器内核的协处理器,还含有四个GDDR存储器控制器,以及与主处理器Xeon CPU连接的PCI Express® (PCIe®)接口。每一个处理器都有自己的专用矢量处理单元,以及自己的512 Kbyte L2高速缓存。L2高速缓存、GDDR控制器以及PCIe控制器不是由传统的交换矩阵连接的,这样会导致规模非常大而在物理上无法实现,而是由双向环形总线连接。这一总线在每一方向上都有64字节数据通路,通过分布式标签方案来实现所有L2之间的一致性。遵从体系结构的发展规律,Xeon Phi在内部与早期的multicore设计非常相似,即,在PlayStation 3中首次使用的IBM Cell协处理器。
图2.Intel的Xeon Phi是50多个x86内核构成的异构阵列,这些内核通过两路跑道型互联结构连接起来。
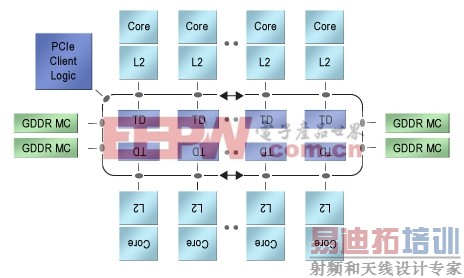
Xeon Phi代表了从multicore向many-core的深入发展。这里,与Cell不同,没有专门的加速器或者专用存储器结构,只有相对简单的x86处理器,连接了矢量处理单元和高速缓存、DRAM控制器以及PCIe接口。所有这些芯片都专门用于执行x86指令代码。Intel展望了Xeon Phi将用于物理、化学、生物和金融分析等应用中。[p]
编程模型
这三种芯片代表了系统软件开发人员三种完全不同的模型。Octeon Fusion非常专用:它是芯片基站。编程人员使用它时,将基站应用线程映射到CPU、加速器和DSP上,通过中心共享高速缓存来同步线程。虽然可以在CPU之间或者在DSP之间动态映射任务,还是需要在不同类型的处理器之间来回迁移一些任务。
对于软件设计人员,16核SPARC64在两方面是完全不同的。所有这些处理器都是一样的,都共享一个L2,因此,不需要将线程锁定某一CPU。硬件加速器位于指令级,由编译器推断其使用,而不是由编程器进行调用。您不需要在分立的硬件加速器之间输入输出数据,确定正确的线程位于正确的CPU上,或者与松耦合辅助处理器同步。
Xeon Phi在数量上与Fujitsu SPARC64芯片不同,北向有50个CPU,而不是16个。其互联结构也明显不同,连贯环上有适度的专用L2,而不是完全共享的L2。毫无疑问,对于与以前IBM相似的Intel体系结构,双环是最高效的芯片实现方式。
Intel和Fujitsu芯片都具有同构体系结构的优点,不需要专门调用硬件加速器,性能与具体位置无关,没有跑道方式那么复杂。软件设计人员可以按照自己的方式,将任何混合数据流、多线程或者数据并行机映射到CPU中。
那么,这到底意味着什么
很显然,这三种完全不同的many-core芯片对软件开发人员提出了不同的需求。但是,如果是这样,这些SoC究竟给系统开发人员带来了哪些问题呢 由于这些芯片是新出现的,因此,我们向其他公司中有many-core应用经验的用户提出了我们的问题。
他们建议我们应深入了解几个不同的问题。一是配置:SoC需要多大的I/O带宽、总线带宽以及外部存储器带宽 第二,密切相关的问题是性能建模。芯片到底需要多大带宽与它使用数据和产生数据的速度有关。第三是控制问题:SoC怎样处理中断 芯片初始化调试操作、电源管理和按序关断时,都需要什么条件 还有功耗问题,在另一篇文章中专门解决了这一问题。
有经验的用户还提出了另一个有用的建议:明确Octeon Fusion等异构专用SoC与Xeon Phi等同构芯片之间的不同。专家说,这两方面代表了完全不同的挑战。
数据之后
异构many-coreSoC尽管在内部组织上是围绕共享存储器和总线进行构建,而实际上用作数据流机。在某一工作模式下,已知数据流通过芯片的各种处理器来传送,一般是固定的数据无关码型。这些约束简化了系统级分析。
全球研究组织IMEC (比利时Leuven)的软件无线电(SDR)研究部科学项目总监Liesbet Van der Perre解释说:“这些系统的存储器数据流有很高的可预测性。在这些系统中,数据流定义了处理器和通路。在某些共享总线或者存储器结构中的某些点上,您会看到瓶颈,但这通常是可以预测的。”
Van der Perre的计划是采用可重新定义的粗粒度处理器阵列来实现移动SDR。芯片配置会随着射频工作模式而变化,但是,当射频保持在某一模式上时,配置会保持稳定。那么,在某一模式下,阵列的行为实际上与静态异构体系结构非常相似。一旦您理解了数据流之后,就比较容易对带宽需求和功耗进行建模。其实施要求主要来自算法级模型。
这种实现方法是应用异构多处理器常用的方法,能够以同样的方式来使用同构many-core系统。对于某一工作模式,可以将任务固定映射至处理器和存储器,明确设计团队的配置需求,能够解释数据。由于这种映射,分析SoC体系结构和算法描述体现了系统设计人员是否具有这方面的设计技巧。这也是Mercury计算机公司成名的原因之一,该公司是高端嵌入式计算公司,在PowerPC早期就使用了multicore和many-core体系结构,并率先使用了图像处理单元(GPU)进行信号处理。Mercury公司的技术总监Scott Thieret说:“这成为我们增值的主要来源,使我们能够与客户一起工作,将数据流映射到硬件中。”
通过固定映射,至少有信心在理论上对数据流和功耗建模。但这并不意味着很容易实现。Thieret说:“对这些系统建模和优化来自于经验。您需要进行很多测试。有一些重要的指南,例如,让数据尽可能靠近处理器,利用芯片最佳数据移动模型等。但这要依靠经验。”
动态挑战
一些规划人员认为many-core系统的未来是在另一方向:不是将任务静态映射至处理器,而是流动的、虚拟化系统,其中任何线程都可能随时占用任何资源。在这一环境中,预测带宽需求、处理负载甚至是功耗都会成为很复杂的任务。
一家经验丰富的many-core系统开发公司内部人士评论说:“出于这一原因,发售的很多系统性能都不是太好。开发人员能够对系统平均带宽需求进行建模,但是,他们低估了峰值需求,遇到了无法预测的瓶颈问题。使其能够正常工作的唯一方法是降低系统性能。”
他继续解释说:“很难预测这些系统中的总线竞争或者峰值带宽。设计人员一般甚至都不会进行尝试;他们只是尽量做好总线和外部存储器配置。他们设计,测试,并不断重复。”
这种不确定性意味着,在工程开始时,如果缺少工作参考设计,则无法知道某一many-coreSoC是否能够满足一些特殊的要求。解决的唯一方法是为系统提供过多的资源,使得资源竞争不会超出能够使用的资源范围。
这样做必然的结果就是增大了功耗。如果不能提前预测哪些处理器会全速运行,哪些会降速工作,哪些会在某些时刻关断,那么,很难估算SoC和DRAM的功耗或者温度。Thieret认为:“很难预测功耗。总功耗等数据指标几乎与系统中的实际功耗不相干。您最好的做法是借鉴以前工程的经验,进行大量的测试。在FPGA行业以外,还没有很好的工具来进行早期功耗估算。”
谁在控制
如果理解了many-coreSoC的性能和功耗是很大的挑战,那么,也就知道这些芯片的系统控制同样是棘手的问题。与前两个问题不同,对于异构、静态映射的系统,系统控制并不那么简单。也不能通过过度设计来解决这一问题。Thieret提醒说:“系统控制是一个基本问题,随着处理器数量的增加,会越来越复杂。但是,您必须解决这一问题。”
最基本的难点在于将不同处理器中的任务与外部异步事件同步,例如,中断、调试信号或者掉电等。即使是以清晰数据流模型为主的静态系统,如果需要对某一处理器中的任务进行中断,以响应某一事件,那么,也很难弄清楚应该启动、暂停或者重新同步哪些任务。
在同构虚拟系统中,只有系统管理程序知道某一任务所在的位置,几乎不可能在正确的地方及时执行中断,在嵌入式操作系统中,会很难完成这一过程。系统设计人员可能要考虑中断的替代方案,例如,让一个处理器专门用于轮询外部事件,或者使用中断信号来启动新服务线程,而不是中断现有线程。这些方法都不能很好的解决SoC内部和外部之间复杂的仲裁问题。
初始化和关断是同样的难题。只是停止所有处理器上的所有线程,并不是一种好选择,这可能会破坏数据结构,或者使得受控机处于危险状态中。在出现电源完全失效等情况时,也会很难理解系统是怎样工作的。一开始就会很难。一些设计团队已经证实,能够设计无法初始化的芯片。一些设计支持有序启动,但是不在系统要求的时间范围内。Thieret看到:“不同的应用有不同的需求。有时候,您有一个小时的重新启动时间,而有时候,只有四秒的时间。” Many-core计算的前景很直观:这是摩尔定律向前发展的唯一途径。而采用many-core SoC来实际实现系统时,在系统理解、估算、配置和控制等方面会带来很多新问题。SoC设计人员和系统设计人员一般通过参考设计来互相理解,这样才能够推动向前发展。
射频工程师养成培训教程套装,助您快速成为一名优秀射频工程师...
射频和天线工程师培训课程详情>>
