- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
CST和CUDA
录入:edatop.com 点击:
非常感谢大家及时详细的解答,我先将我自己的理解总结一下,以便后人观看:(如果有问题请提出以便修改)
一、什么是CUDA
首先CUDA(Compute Unified Device Architecture)是一种利用显卡上的芯片(GPU)以及显存来分担CPU运算任务的并行计算架构,最早由NVIDIA提出并实现。
二、CUDA和CST MWS
历史:首先是一家叫做Acceleware的公司利用NVIDIA的CUDA提供软件接口,使得用户可以用以CUDA技术解决复杂的计算问题,2008年,CST也采用了这样的技术,并在官网上宣称利用CUDA加速可以提高40%的仿真速度。
等到了CST2010 我们再也看不到Acceleware的身影,CST已经将CUDA技术较好的融入到了CST2010中,根据CST2010的官方宣传,如下图所示
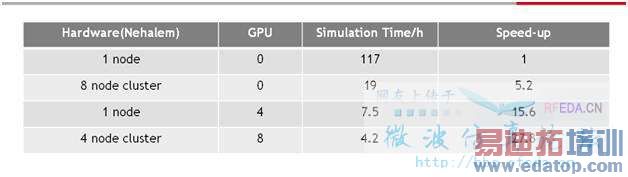
从上图就可以看出他快的而不仅仅是40%那么简单,这个是在进行检测chip的signal integrity的时候进行的,最高有可能提高将近28倍
下图是CST的仿真加速结构,从底层的硬件到仿真的时候的cluster分块,再到仿真算法的优化,
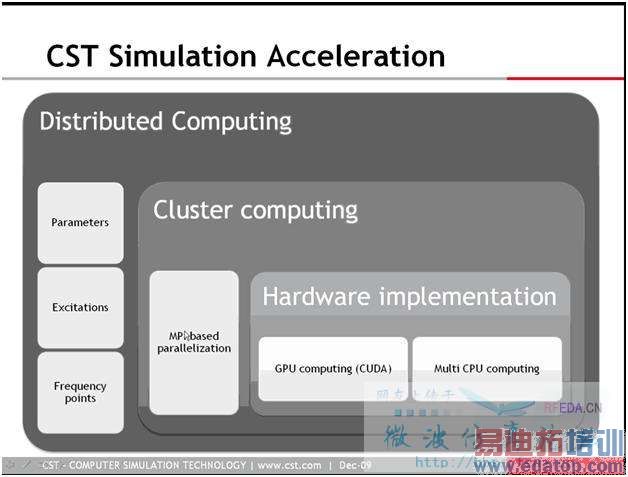
三、CST硬件加速
CST的硬件加速,包括:CUDA、Distributed Computing(分布式计算)和MPI Computing(线程并行计算),当然好东西不是白用的 需要收费,根据版主EDATOP提供Acceleration Token 9000欧元一年,之后是每年15%的维护费。关于acceleration的list如下图,
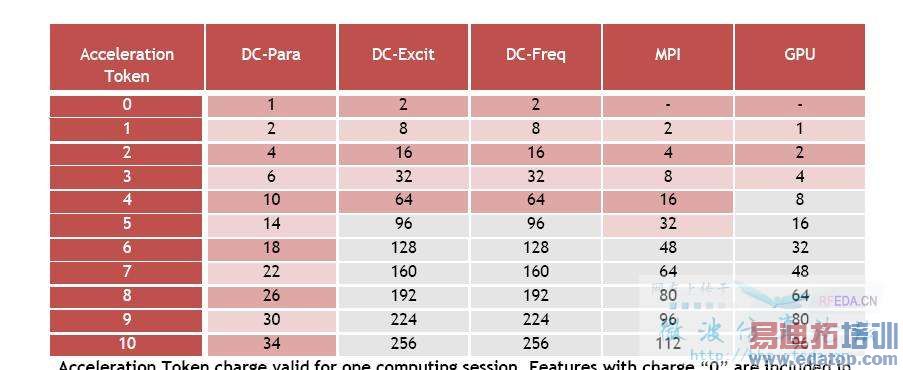
关于CUDA在CST里的介绍我能想起来的也就那么多了,但是CUDA并不仅仅是在CST里的应用,在这个本站里面也有不少关于CUDA应用的介绍,
利用CUDA在MATLAB中加速:/read-htm-tid-30481.html
还有一个巨牛的帖子手把手教大家CUDA编程的:/read-htm-tid-18915.html (看了这个帖子心潮澎湃,内牛满面啊,再次向牛人致敬)
最后感谢版主EDATOP,lantianyi ,以及zhknpu的帮助
P.S. 其实我心里还存在这样的侥幸心里,在CST2010的前一个版本是否可以自信安装Acceleware的第三方驱动以后进行加速,呵呵,邪念!
一、什么是CUDA
首先CUDA(Compute Unified Device Architecture)是一种利用显卡上的芯片(GPU)以及显存来分担CPU运算任务的并行计算架构,最早由NVIDIA提出并实现。
二、CUDA和CST MWS
历史:首先是一家叫做Acceleware的公司利用NVIDIA的CUDA提供软件接口,使得用户可以用以CUDA技术解决复杂的计算问题,2008年,CST也采用了这样的技术,并在官网上宣称利用CUDA加速可以提高40%的仿真速度。
等到了CST2010 我们再也看不到Acceleware的身影,CST已经将CUDA技术较好的融入到了CST2010中,根据CST2010的官方宣传,如下图所示
从上图就可以看出他快的而不仅仅是40%那么简单,这个是在进行检测chip的signal integrity的时候进行的,最高有可能提高将近28倍
下图是CST的仿真加速结构,从底层的硬件到仿真的时候的cluster分块,再到仿真算法的优化,
三、CST硬件加速
CST的硬件加速,包括:CUDA、Distributed Computing(分布式计算)和MPI Computing(线程并行计算),当然好东西不是白用的 需要收费,根据版主EDATOP提供Acceleration Token 9000欧元一年,之后是每年15%的维护费。关于acceleration的list如下图,
关于CUDA在CST里的介绍我能想起来的也就那么多了,但是CUDA并不仅仅是在CST里的应用,在这个本站里面也有不少关于CUDA应用的介绍,
利用CUDA在MATLAB中加速:/read-htm-tid-30481.html
还有一个巨牛的帖子手把手教大家CUDA编程的:/read-htm-tid-18915.html (看了这个帖子心潮澎湃,内牛满面啊,再次向牛人致敬)
最后感谢版主EDATOP,lantianyi ,以及zhknpu的帮助
P.S. 其实我心里还存在这样的侥幸心里,在CST2010的前一个版本是否可以自信安装Acceleware的第三方驱动以后进行加速,呵呵,邪念!
CST MICROWAVE STUDIO users can gain up to 40 percent performance improvements for electromagnetic simulations with Acceleware's next generation of software acceleration products
CALGARY, Alberta, and DARMSTADT, Germany, Aug. 25 -- Acceleware Corp., a leading developer of high performance computing applications, and Computer Simulation Technology (CST), a supplier of leading-edge electromagnetic (EM) simulation software, today announced a new CUDA (Compute Unified Device Architecture)-based Acceleware solution for accelerating EM simulations with CST MICROWAVE STUDIO (CST MWS). Trial tests of this new acceleration product have delivered performance gains of up to 40 percent compared to the current product. This faster version is compatible with current generation GPUs, delivering significant speed-ups to CST customers without having to upgrade hardware.
"CST MWS users already benefiting from our acceleration solutions will experience significant performance improvements with a simple software update," said Ryan Schneider, CTO of Acceleware. "This combined offering enables Acceleware and CST to deliver the first ever CUDA powered solution to solve electromagnetic problems."
The new Acceleware software uses NVIDIA's CUDA programming language that was designed to solve complex computational problems, enabling users to access multi-core parallel processing technology. Engineers and product designers who value the CST MWS time domain solver's efficiency, accuracy and user-friendly interface, will benefit from increased acceleration to help them tackle larger simulation problems and meet production deadlines.
"NVIDIA Tesla products in combination with CST and Acceleware's software provide an accelerated design environment for end users to reduce the time spent simulating products," said Andy Keane, general manager of the GPU computing business at NVIDIA. "Acceleware's use of CUDA in its libraries to harness the parallel architecture of the GPU will provide compelling value and considerable speed-ups for designers who frequently perform EM simulations."
Acceleware's CUDA enabled solvers take advantage of highly parallel NVIDIA compute hardware to offer performance gains while performing lengthy EM design simulations. Users will be able run their CST MWS simulations even faster while supporting the same accelerated feature sets that designers use today, including open boundaries, lossy metals, Thin Sheet Technology (TST), Perfect Boundary Approximation (PBA), dispersive materials, and far field monitors. Single card, dual card, and quad card configurations are supported.
"Acceleware's hardware acceleration solutions have been well received by our customers. Achieving an accurate solution in a shorter time frame is instrumental in bringing their products to market earlier," commented Jonathan Oakley, VP of sales and marketing at CST of America. "We are really excited by the prospect of offering them an even faster, CUDA enhanced solution as part of their regular maintenance."
Availability
The CUDA enabled solver is expected to be available by the end of 2008. CST and Acceleware end users will benefit from this development as part of their maintenance contract. All 30 series products will be supported. The range of hardware acceleration products may be extended in the future. For more information, visit www.acceleware.com or www.cst.com.
CST develops and markets software for the simulation of electromagnetic fields in all frequency bands. Its success is based on the implementation of unique, leading-edge technology in a user-friendly interface. Furthermore, CST's "complete technology" complements its market and technology leading time domain solver, thus offering unparalleled accuracy and versatility for all applications. CST's customers operate in industries as diverse as telecommunications, defence, automotive, electronics, and medical equipment, and include market leaders such as IBM, Intel, Mitsubishi, Samsung, and Siemens. Timely, local support is provided through CST's direct sales and technical support forces. Together with its highly qualified distributors and representatives, CST supports its EM products in over 30 countries. CST's flagship product, CST MICROWAVE STUDIO (CST MWS) is the leading-edge tool for the fast and accurate simulation of high frequency (HF) devices such as antennas, filters, couplers, planar and multi-layer structures and SI and EMC effects. CST MWS offers considerable product to market advantages such as shorter development cycles, virtual prototyping before physical trials, and optimization instead of experimentation. Further information about CST is available on the Web at www.cst.com.
About Acceleware
Acceleware (TSX-V: AXE) develops and markets solutions that enable software vendors to leverage heterogeneous, multi core processing hardware without rewriting their applications for parallel computing. This acceleration middleware allows customers to speed-up simulation and data processing algorithms, benefiting from high performance computing technologies available in the market such as multiple-core CPUs, GPUs or other acceleration hardware. Acceleware solutions are deployed by companies worldwide such Philips, Boston Scientific, Samsung, Eli Lilly, General Mills, Nokia, LG, RIM, Medtronic, Hitachi, Fujifilm, FDA, Mitsubishi, Sony Ericsson, AGC, NTT DoCoMo, and Renault to speed up product design, analyze data and make better business decisions in areas such as electronic manufacturing, oil & gas, medical and security imaging, industrial and consumer products, financial, and academic research. Acceleware is a public company on Canada's TSX Venture Exchange under the trading symbol AXE. For more information about Acceleware, visit www.acceleware.com.
wiki 对CUDA的概述
CUDA (an acronym for Compute Unified Device Architecture) is a parallel computing architecture developed by NVIDIA. CUDA is the computing engine in NVIDIA graphics processing units (GPUs) that is accessible to software developers through variants of industry standard programming languages. Programmers use 'C for CUDA' (C with NVIDIA extensions and certain restrictions), compiled through a PathScale Open64 C compiler,[1] to code algorithms for execution on the GPU. CUDA architecture shares a range of computational interfaces with two competitors -the Khronos Group's Open Computing Language[2] and Microsoft's DirectCompute[3]. Third party wrappers are also available for Python, Perl, Fortran, Java, Ruby, Lua, and MATLAB.
CUDA gives developers access to the virtual instruction set and memory of the parallel computational elements in CUDA GPUs. Using CUDA, the latest NVIDIA GPUs become accessible for computation like CPUs. Unlike CPUs however, GPUs have a parallel throughput architecture that emphasizes executing many concurrent threads slowly, rather than executing a single thread very fast. This approach of solving general purpose problems on GPUs is known as GPGPU.
In the computer game industry, in addition to graphics rendering, GPUs are used in game physics calculations (physical effects like debris, smoke, fire, fluids); examples include PhysX and Bullet. CUDA has also been used to accelerate non-graphical applications in computational biology, cryptography and other fields by an order of magnitude or more.[4][5][6][7] An example of this is the BOINC distributed computing client.[8]
CUDA provides both a low level API and a higher level API. The initial CUDA SDK was made public on 15 February 2007, for Microsoft Windows and Linux. Mac OS X support was later added in version 2.0[9], which supersedes the beta released February 14, 2008.[10] CUDA works with all NVIDIA GPUs from the G8X series onwards, including GeForce, Quadro and the Tesla line. NVIDIA states that programs developed for the GeForce 8 series will also work without modification on all future NVIDIA video cards, due to binary compatibility
这个就是CST所说的GPU Computing,是Hardware Acceleration方法之一,现在和Distributed Computing、MPI Computing统一使用Acceleration Token实现授权。具体的说明可以参考GPU Computing Guide,官网可以下载。
现在公司正在考虑要不要买一个token,9000欧元一年,之后是每年15%的维护费。用最简单的Nvidia Quadro FX 5800或者Nvidia Tesla C1060可以实现6-7倍的提速。我们让CST技术支持做过测试,现在我正在仿真的模型用HP个人工作站xw8400耗时19个小时,CST那边用GPU加速用时不到两个小时!
使用GPU加速有硬件配置的要求,上面的两种加速卡要求最少12 GB内存,工作站需要800 W - 1000 W功耗。更高级的加速设备要求更高,GPU Computing Guide有列出来需要的硬件配置要求。
谢谢版主的回复,刚才已经阅读了您推荐的 GPU Computing Guide,
可惜的我现在只有一台双核2.6+4GRAM的PC机,如果我没有理解错的话,就算我买了支持cuda的显卡,我也还需要购买cst的token才能实现加速?
观望,等待!
简单的回答:是的!
使用一个GPU,需要一个Acceleration Token。
具体内容可以参考CST Licensing Guide 2010。
非常感谢版主
看来只有花钱才能买到好东西 呵呵
这个我已经用了一年多了,还有些经验。有什么问题可以给我留言。
据我所知,并不是单单买一块显卡就能搞定的,这个硬件加速卡最早是安装在机箱里面的,后来由于功耗和重量的原因,现在都是做成一个单独的模块。
硬件加速功能一共是三家公司共同实现的,cst提供仿真软件,Nvidia提供加速卡硬件,Acceleware提供两者之间的接口模块。
前面的信息已经有点儿老了……。
CST公司刚刚又更新了一次GPU Computing Guide(8月26日),更新了Telsa M系列加速卡的支持信息,更新了驱动的链接,现在使用GPU也可以支持Remote Login了。
通读现在的GPU Computing Guide,你已经看不到Acceleware的影子了,而且上一次和CST技术支持的人开网络会议,他们也没提到要和Acceleware打什么交道。
要使用GPU Computing,加速设备自备,再购买Token就好了,就这么简单。硬件兼容方面是客户自己需要考虑的。
现在单GPU的Nvidia Quadro FX 5800和Nvidia Tesla C1060还是安装在主板PCI-E G2 *16插槽上,显卡需要200 W功耗。今年底有新一代的加速卡会推出(Tesla 2系列,Quadro系列好像也有更新),单GPU加速卡仍然是插在主板上。
NVIDIA Quadro Plex 2200 D2是一个独立的模块,两个GPU,功耗640 W,工作站功耗750 W,看尺寸应该是独立于机箱之外,占用一个PCI-E G2 *16插槽。
NVIDIA Tesla S1070要用到rack-mount system,四个GPU,功耗800 W,工作站功耗750 W,占用两个PCI-E G2 *16插槽。
新列出来的NVIDIA Tesla M1060是Embedded module,PCI-E接口模式,一个GPU,不过看不出来是插在主板上还是连接在外面。
这个帖子技术很先进啊,未来的趋势啊~
申明:网友回复良莠不齐,仅供参考。如需专业解答,请学习易迪拓培训专家讲授的CST视频培训教程。
上一篇:The discrete edge port is inside perfect conducting material ?
下一篇:CST 2010 examples中问题
